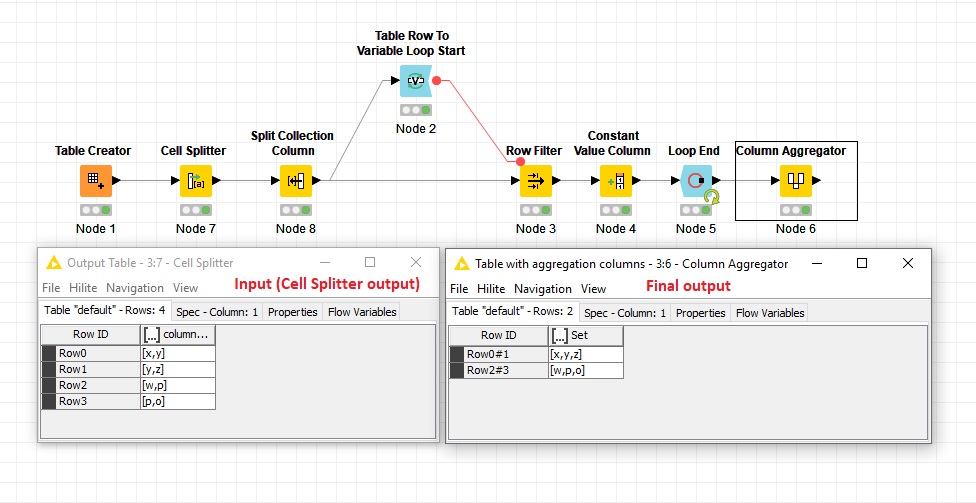
I did a group by but the result ist not 100% because some Grouping have sometimes the same Platforms just with other combinations.
But I can solve this problem if I can solve this example:
List input:
X;Y
Y;Z
W;P
P;O
thanks for replying but i have written the result of my group by. It’s a group by for a many to many relationship (between Platform and product tables ) and it will have as result a collection of all platforms which have the same products:
e. g.
Platform--------- Product
P2, P3, P4, P6… are products not platform! I need to show just a list of aggregated collections. Better would be
Platform--------- Product
G1;G2------------P1;P2;P3
G3;G4------------P5;P6;P4
Thanks DaveK for replying and trying to help me. You are in the right way!
I tried to use your workflow but I found in your node Itemset findet a min 1 of support which for this example works. But for my productive data it doesnt work because support is too low
Could you elaborate on that? Do you mean the configured minimum support is too low?
In this case, the Item Set Finder (Borgelt) node is just used to find the biggest super sets of the platform groupings. Hence, the minimum support of 1 should find all of them. Could you maybe attach a workflow showing your issue?
I just saw that in my attached workflow, the Item Set Finder (Borgelt) node is configured to use a percentage as minimum support. However, as explained above, this should have been an absolute number. Sorry for that. Does this maybe solve your issue?
thanks armingrudd, but I still have some errors it’s still not right.
I Uploaded my excel data to show you my problem
My problem is so simple but may be I explained it bad.
I need to group all the platforms which have the same products and list them in a forme of collection or concatenate them, I tried excel power query but still don’t have what I need.
I think the problem were duplicate platforms after the first Group By node. Hence, I added another one to also group by the platforms to also aggregate all products. The rest stayed the same (see attached workflow). Is that what you are looking for?
I’m not sure about this, but does the solution provided by @DaveK truly solve your issue?
Because still I can find sets with duplicate platforms (e.g. row 102 and 63 or those you mentioned).
I guess you want to merge them, right?
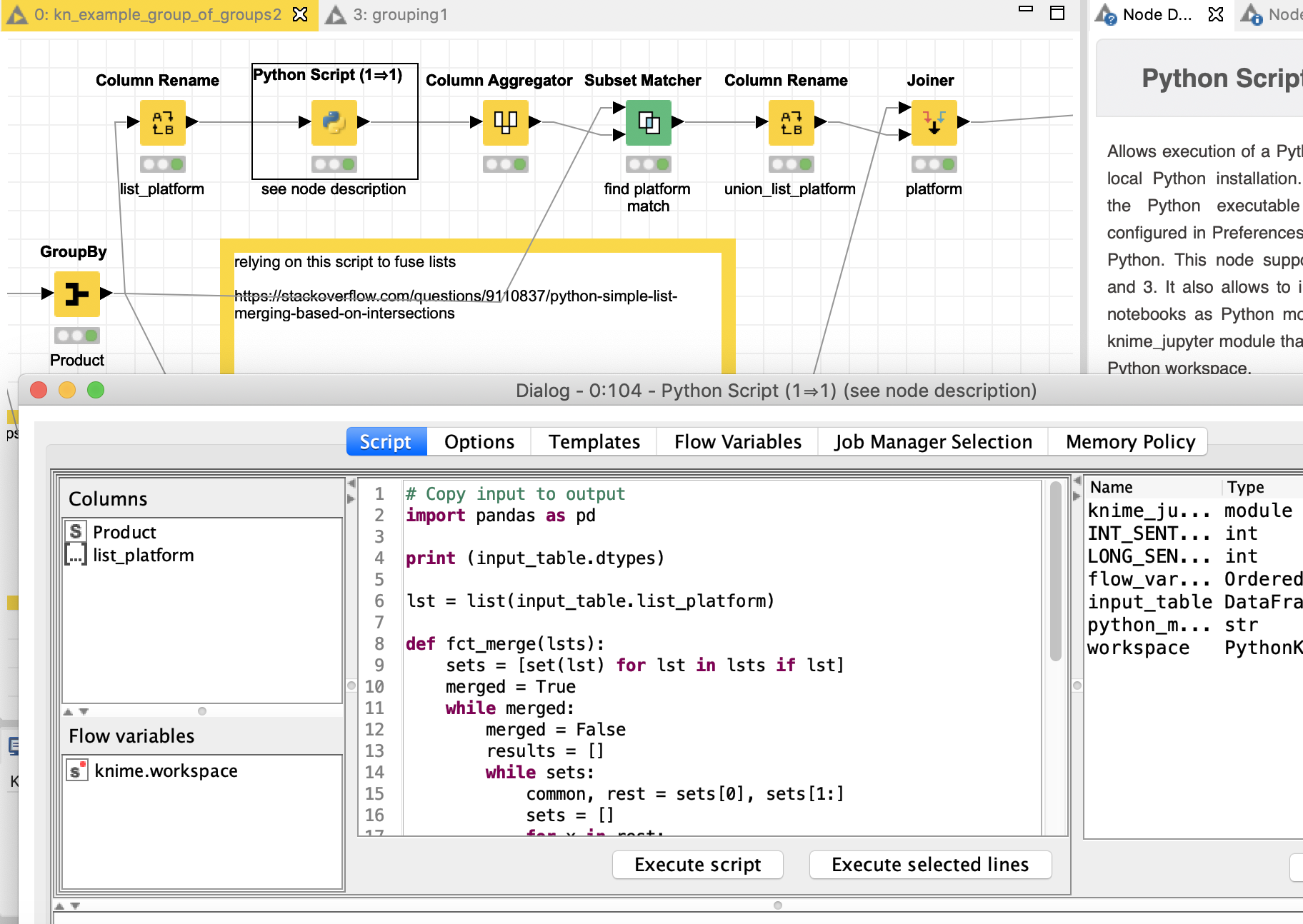
To be honest this problem went around in my mind for quite some time because I could not figure out if it was super simple or super complex and I did not get my head around it.
I now found a mixed solution relying heavily on a small (well) Python script merging lists and it becomes a mixture of Python and some KNIME nodes. I just wonder if the whole thing would be easier in just Python but I do not have the stamina right now to figure that out…
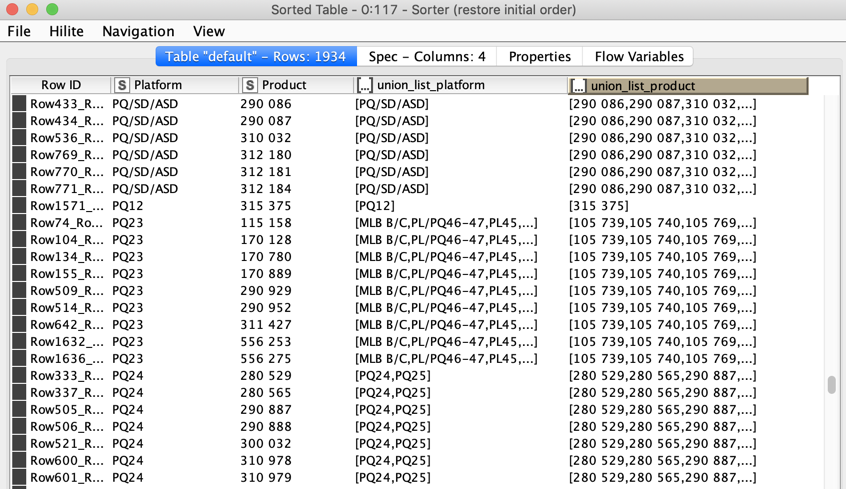
So without further ado here is the solution. It is possible there is a step which is too complicated. Hope this can be adapted. The results are lists. I kept all original lines on purpose so one can check if it makes sense. In a final step the duplicates of lists could be removed.