I am using Tika PDF Parser to extract images from scanned PDFs. I have encountered the following problem:
I use two test files. File 1 is a scan directly from my printer. It does not contain any text, only images. File 2 is identical; I just added a “confidential” stamp to file 2 to test if that interferes with the process.
Tika PDF parser extracts the images as expected from file 2 (with the stamp), giving me PNGs that I can work with. However, it only extracts TIF files that apparently contain no data and have a size of 0 bytes from file 1. I use the same node to do this, so the settings are exactly the same. I do not have problems extracting the images from either PDF file outside KNIME, e.g., with ubuntu’s document viewer.
Has this occurred before? Or do you know if Tika Parser (or its KNIME implementation) has any limitations regarding the layout of the PDF? Does it not work with PDFs that exclusively contain images, or anything like that?
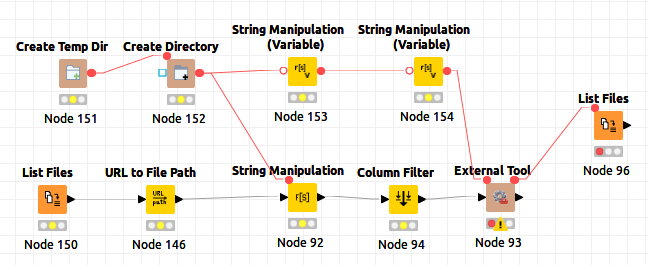
I have got the same problem and tested some solution with and without tika-parser. The best solution I have found to extract images from hundreds of pdf-files from different sources, is the usage of pdfimages (https://anaconda.org/conda-forge/poppler/files).
I am using linux and the script is a bash script but I think it is easy to transfer into a Windows batch-script.
Thank you for your solution! I think I can work with that.
In your experience, what kind of documents worked well with KNIME’s Tika Parser, and which documents caused problems? You seem to tried out a lot of different approaches
Hi Jan,
I worked with tika-parser, image magic convert and pdfimages with different options. Inside my pdf-files I found a mixture of jpeg with rgb color and ccitt with gray color.
The tika-parser extracted jpeg to jpg and ccitt to empty tif files.
Image magic convert created own images and did not extract embedded images.
pdfimages with -j for jpeg and -png as fallback for all other formats was the best solution for me.