Hi, i am trying to analyze reviews of reviews scrapped from a software comparing website. I have done everything the same like in the blog except few cleaning and filtering some rows.
However, in the processing component, the groupby node which comes after the bag of words that support to filter contain some terms, there are no any results.
can you please assist ?
Topics extraction_elbow method_final.knwf (228.0 KB)
HubSpot Marketing Hub Reviews _ Ratings _ 2021 _ combined text.xlsx (2.4 MB)
thıs ıs the data set.
the stop words
marketing terms.xlsx (8.1 KB)
Hi @abdkhirfan -
Document cells in KNIME only show the title portion of their metadata in the standard tabular view. In order to get a better view of the text, you can try using the Tagged Document Viewer or Document Viewer nodes, as shown in this video:

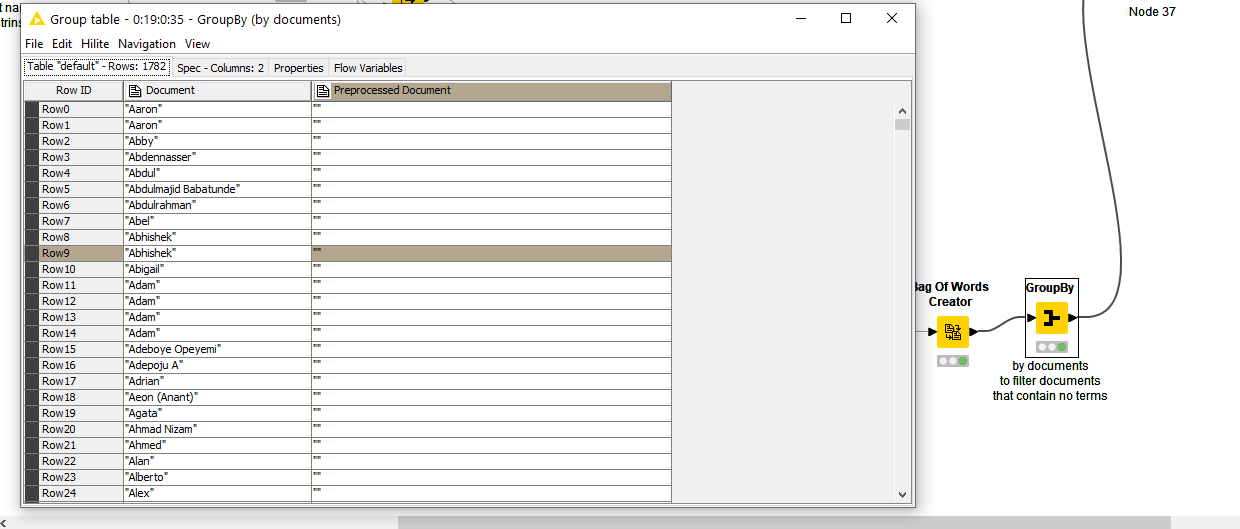
For example, this is what I see when I use the Tagged Document Viewer directly after your GroupBy node:
1 Like
thanks for quick reply. I think this groupby was only for one of the meta node(tıtle for the document) not for the whole text?
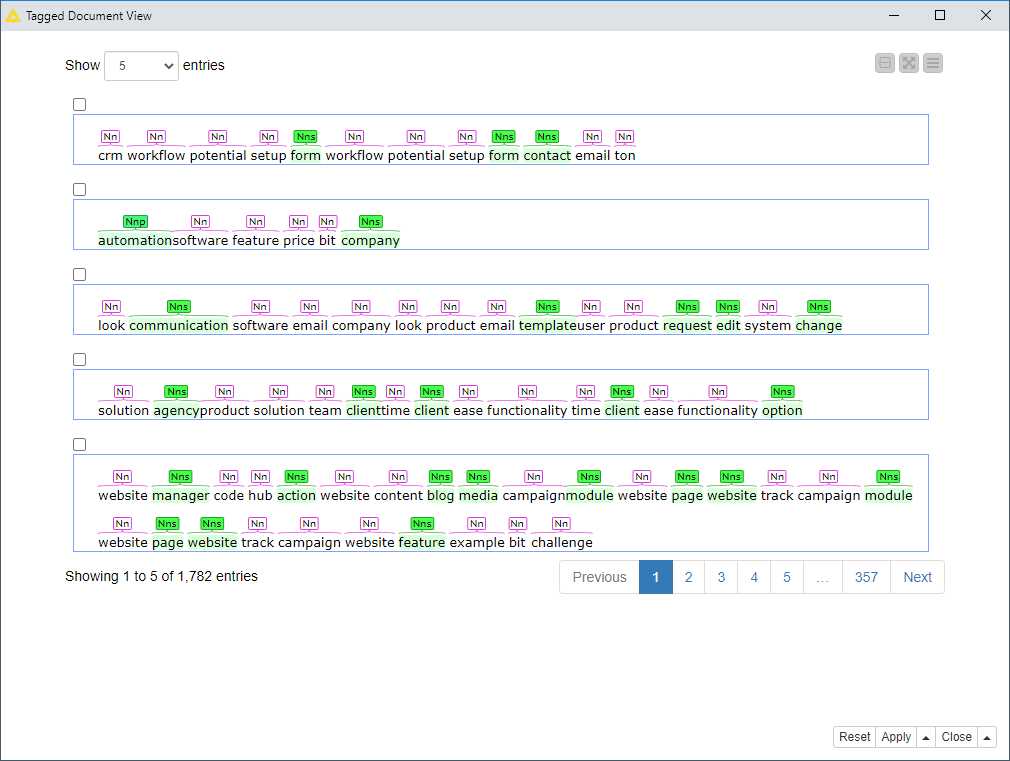
I have other questıons, despite that i inserted stop words with an added dictionary to be filtered out but the terms still appear? what i have done wrong ?.
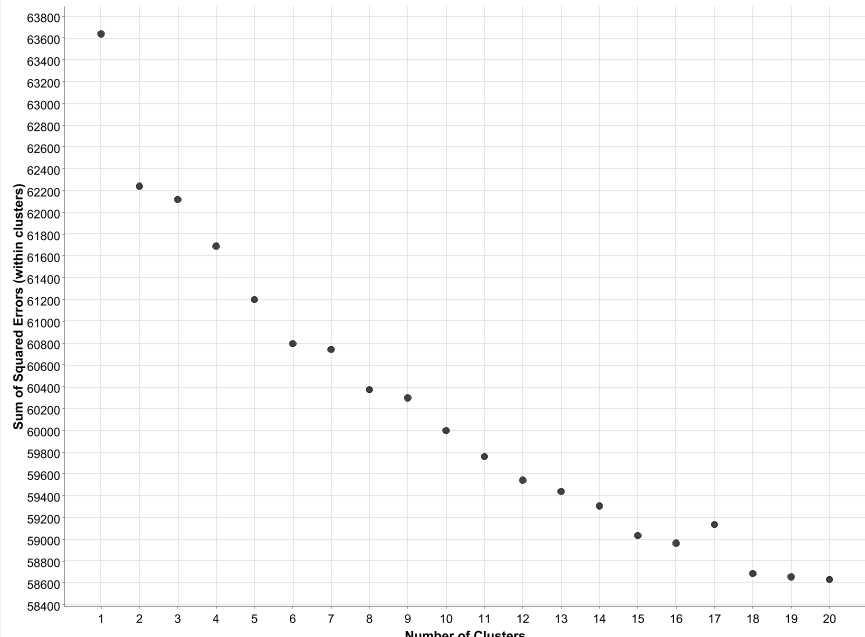
second question: is the scatter plot correct? i have 1 big falls, and 2 small one. the big fall means that i should only choose two topics ? but that doesnt make sense. Correct me if im wrong?
For the stop words, definitely uncheck the “Case sensitive” box - that’s why terms like marketing are still showing up.
Since there doesn’t seem to be a huge drop in your skree plot, I would perform LDA (and create word clouds) for a few of the smaller cluster sizes, maybe 2-6, and see if any natural grouping jumps out at you. There’s often a bit of human intuition that’s required to determine what the “correct” cluster size is.
1 Like
Many thanks for the input and help. I am highly grateful for this forum.
One more question: on which basis, i choose the number words per each topic ?
I have another question, is there a way to incorporate the workflow of sentimant analysis (lexicon based approach ) (tagging reviews with positive and negative ) with this workflow, and if there is.how it should be done
I want the combined workflow to give me the extracted topics from positive reviews and negative reviews (separately)
I don’t know that’s there a “correct” answer to this question. If you’re holding the number of topics fixed, then the terms associated with each topic are going to help steer you toward the underlying meaning. So more is probably “better” in that case, although eventually with a lot of additional terms you are probably introducing noise that inhibits interpretability.
Here I would do this in sequence - first do the classification, then separately extract the topics for each of the labeled positive and negative groups.
You could do this in a single workflow if you like. I would probably split it into two workflows myself, but that’s just personal preference.
1 Like
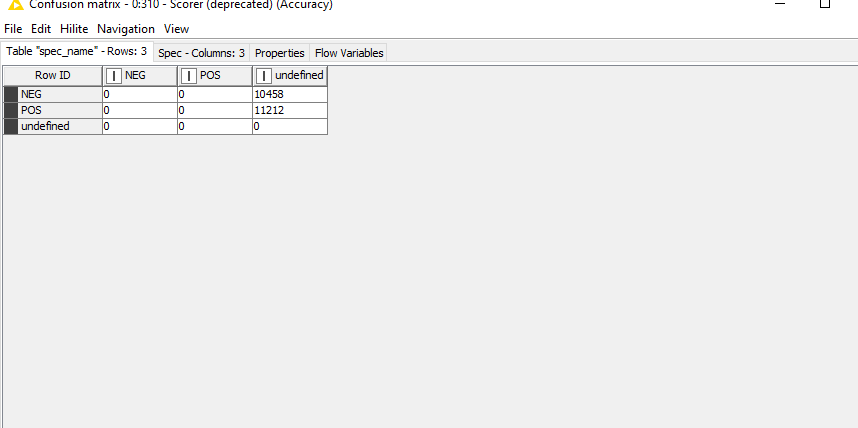
I run the classification exactly as provided in the exampel workflow. However, i got this in the confusion matrix
Labeling classification.knwf (73.5 KB)
I used the previously labeled positive and negative lists you used in the examples. please help.
many thanks
The confusion matrix has no meaning in this case because you don’t have a “true” value to compare to. That only makes sense in the context of when you are using data pre-labeled as positive or negative, which you don’t have here.
All you can do in this case is calculate a score, based on the sentiment dictionaries, and apply that to each document.
Incidentally, I noticed another strange thing in this workflow that you should reconsider - the use of the sentence extractor to a field called Document2, which you never again reuse. Be sure that you understand what each node in the workflow is doing, and consider carefully whether or not it should be applied to your specific case.
i checked again, but the input in the sentence extractor is the document ( which is further processed in the worklow). the weird thing is that the dictionary tagger doesnt not work on the preprocessed document but rather the original document. that’s why i included another string to document node.
So, i can not use knime or this workflow to classify the rows or documents into positive or negative based on the lists?/
thank you in advance
The Dictionary Tagger node will work on any Document columns provided to it. I don’t see a “Preprocessed Document” column in your workflow.
Your workflow is already classifying documents based on the lists and assigning a calculated index score to them. Look at the results of the Rule Engine node (and ignore the Category to Class node because it is meaningless).
I have a question regarding combing the workflow. After getting the results from the rule engine node, how i can transform them to a readable separate set of data (one is positive list and another negative list) to extract topics from them ?
I really appreciate your help.
You could use a Row Splitter to separate the documents based on their classification, and subsequently do topic extraction for POS/NEG separately.
Can you figure out please why the stop words arent eliminated, which are added in the file reader in the processing componentTopics extraction_elbow method2.knwf (212.6 KB)
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.