I tried to use the Topic Extractor node for the first time and have struggles to interpret the results correctly. I preprocessed a column from an excel-sheet, directed the resulting document to the Extractor node and now got numbers as a result. How can I match/group them to previously defined categories?
Initially the idea was to search for keywords inside my given table and categorize the string to defined topics.
Can anybody tell me if the Topic Extractor node is the right tool for my intention? Unfortunately I´m not allowed to use the Regex-Extractor which was my fist idea.
As well, KNIME has various ways to use Regex without using Regex-Extractor. If you know the regex rules, I can help get you started with interactive regex using widgets:
many thanks for your advices! Sorry for answering that late but we had some company issues which needed to be fixed first.
I checked the the Spanish notes analysis and I think if I edit that example in parts it will work for as well. If there are some other difficulties I Cabot fix on my own I’d like to reach out to you again.
as I already suspected I need a little bit more help with that workflow than I expected.
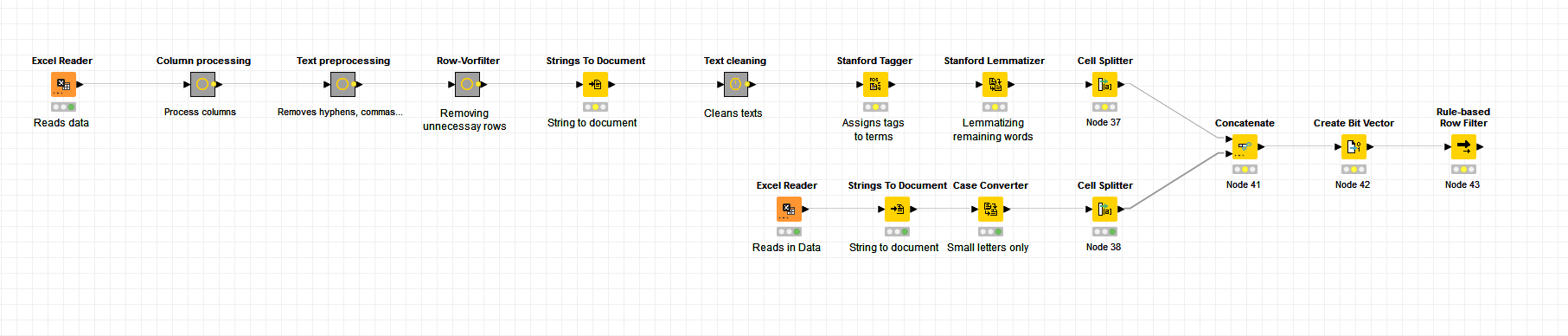
I rebuilt the “Spanish notes Analysis” workflow and configuerd it for my task. Everything went fine until I got to the point were I need to create the bit vectors and previously have to concatenate the preprocessed tokens.
Here again is what I plan to do and my workflow I created so far:
I have a table of findings, meaning a table with one column and around 30 rows. Each row only contains one word.
Then there´s another list with multiple columns and around 40k rows. One of these columns contains texts who describe conditions of components. In every text of this column there is a word which is similar to one of the words in the first table.
What I want to do now is to assing the different texts to one of each findings of the first table. Therefor I thought the workflow you mentioned fits pretty good. But the last step, to compare and assign the conditions of table 2 with the findings of table 1 is pretty hard for me.
I´d appreciate if you could give me an advice how to fix that problem
Let’s say your reference table (with a single column) enlists these one-word items for each row:
lizard
mantis
centipede
computer
And your other table (multiple columns) has one specific column that you want to check with the reference, and this specific column enlists these sentences:
I love ants.
Birds are wonderful.
I drive cars fast.
I build houses by the river.
A centipede is ugly.
Does a mantis pray?
We all love dogs!
Please buy me a starfish.
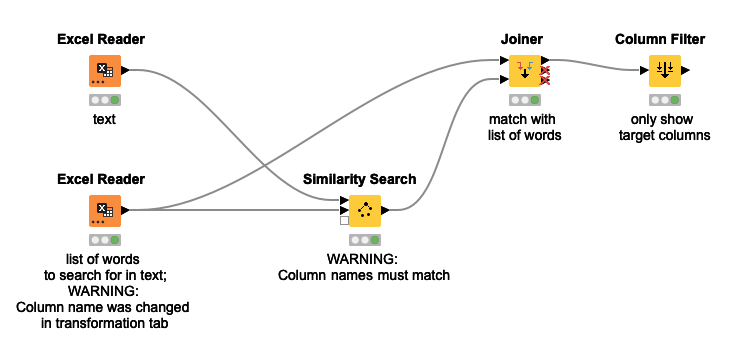
If I can produce a resulting table that tells you the long list overlaps with the reference list with the following items:
mantis and centipede
Would that be useful? If yes, then I’ll know exactly what workflow you’ll need.
@Martin_23, Also, could you attach your workflow (with real or fake data) so I can add on to it?
Just looking at your question though, using the Similarity Search node and Levenshtein distance (for words) may be sufficient, but without the workflow and data, I’m not sure.
that is what I’m looking for. Another table would be fine for me as long as I can see which of the longer texts belongs to which one-word-item.
Looking forward to your idea!
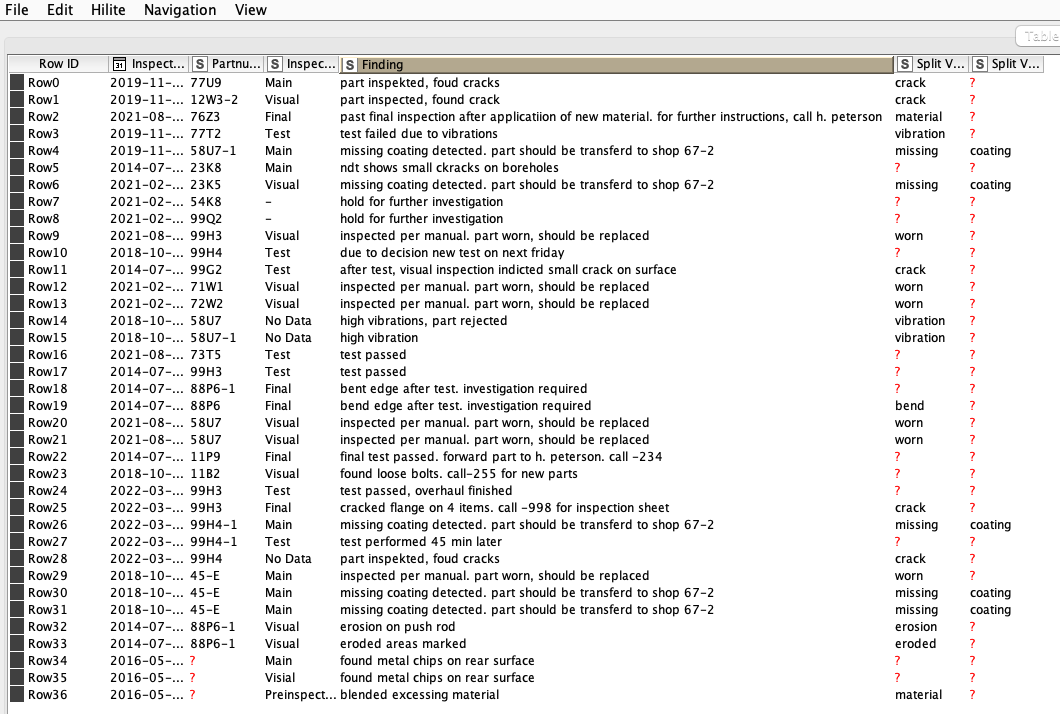
thanks for your answer. I provide you two examplary lists, one with single words and the other with inspection data. Inspection_A.xlsx (10.4 KB) Possible Findings.xlsx (8.9 KB)
As you can see in the inspection data, there is a column including texts from component inspection. What I’d like to do know is to preprocess the texts (what I’m already able to do) and then match the “Findings” to one or more words from the table including the “Possible Findings”.
I already thouhght about using the Levenshtein distance or LDA but it feels like that transforming the “Findings” into a binary type and than performing a similarity search ( like you explained in the “Spanish notes Analysis” ) would be more helpful. But I´m completely open to new ideas and advices.
My biggest problem, as I already mentioned, is to create a working similarity search and to understand what the e.g. Joiner, Bit Vector Creator and Similarity Search nodes to specifically.
Thanks for your support so far, I really appreciate your help.
Great, could you also attach the .knar file? (the workflow). That way I can inspect what you’ve done and see how you expected your output and assumptions, settings, etc. Thanks.
I‘ll upload my workflow as soon as I‘ve Internet access with my computer again. I’m currently on the highway so it might take couple hours. I will get in touch with you asap!
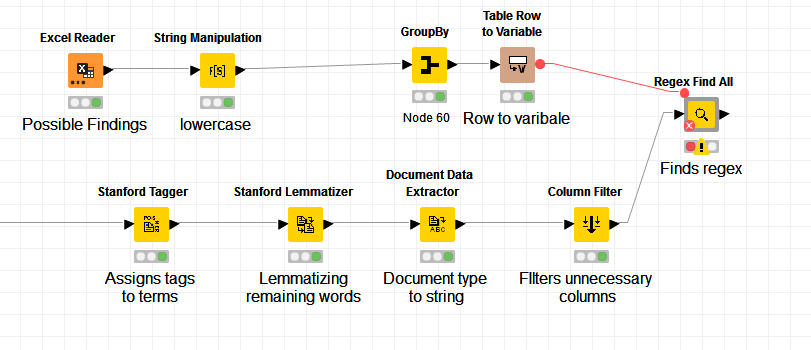
attached you find the workflow I created so far. It took me a while to export it yesterday, sorry for that.
Summarized again:
I still have not a good solution to assign the “Finding”-Texts to the appropriate “Possible Findings” yet (but there is an idea for a similar solution you explained in the “Spanish notes Analysis”)
I used the Stanford Lemmatizer to shorten the words but it doesn´t work if it is spelled worng (inspekted instead of inspected)
I´d beyond grateful if you could help me out with that problem.
This solution actually works better on this sample of data, but if you have a lot of misspellings, this won’t work that well unless you account for those misspellings.
If there are common misspellings then this just add them to your list of words to search, if not, you may have accept some loss of information in exchange for automation.
Notice this method is more convenient because you can filter non-matches using missing rows from the Split Value 1 column.
Hi, it seems like the workflow you shared here is the advanced version of what I had in mind. I’d choose yours over mine. Plus I didnt take into account the possibility of finding more than one word from the reference source.
big thanks for your two solutions. I tried the first one on my real data and it worked most of the time. Sometimes was not correct or didn´t match to the findings as expected.
The second one looks more suitable for what I want to to with the data. Did you build this node? I didn´t know that there are nodes wich include even more nodes. Could I for example build my own ones? As I can see there´s only a chance to sum up nodes into metanodes.
How did you come up with the idea to put all words in one regex? I see that it works but I would never had thought that this is necessary.
Thanks for your help so far and have a great start into the week.
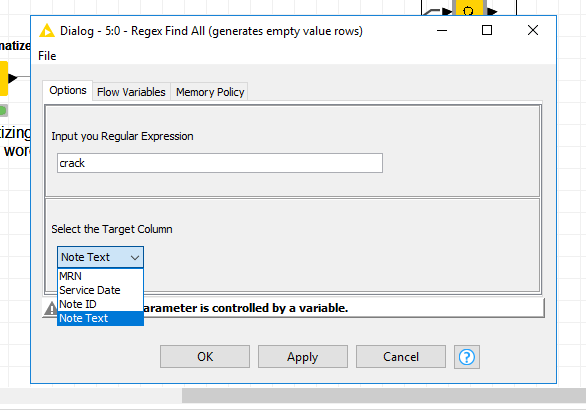
All colums consist of strings, so no different data types. How is it possible to see my column names in the drop down list? Do I need to change the flow variables in the “Regex Find all” node?
I don’t think I’ve seen this issue before. Could you send me a list of your column names and types so I can attempt to replicate this (use Extract Table Spec node) and then cut and paste the names giving you problems directly from the output:
And yes, you can create “components” or “metanodes” which will let you wrap up several nodes. Then you can share those components with the community. The Regex Find All is a community component which I use regularly. Whenever I run into an issue, I then open the component (ctrl+double click or command+double click) to look inside the component and see where it is failing.
I´m glad to say that I was able to fix the problem on my own. Everything went fine so far after I restarted KNIME this morning.
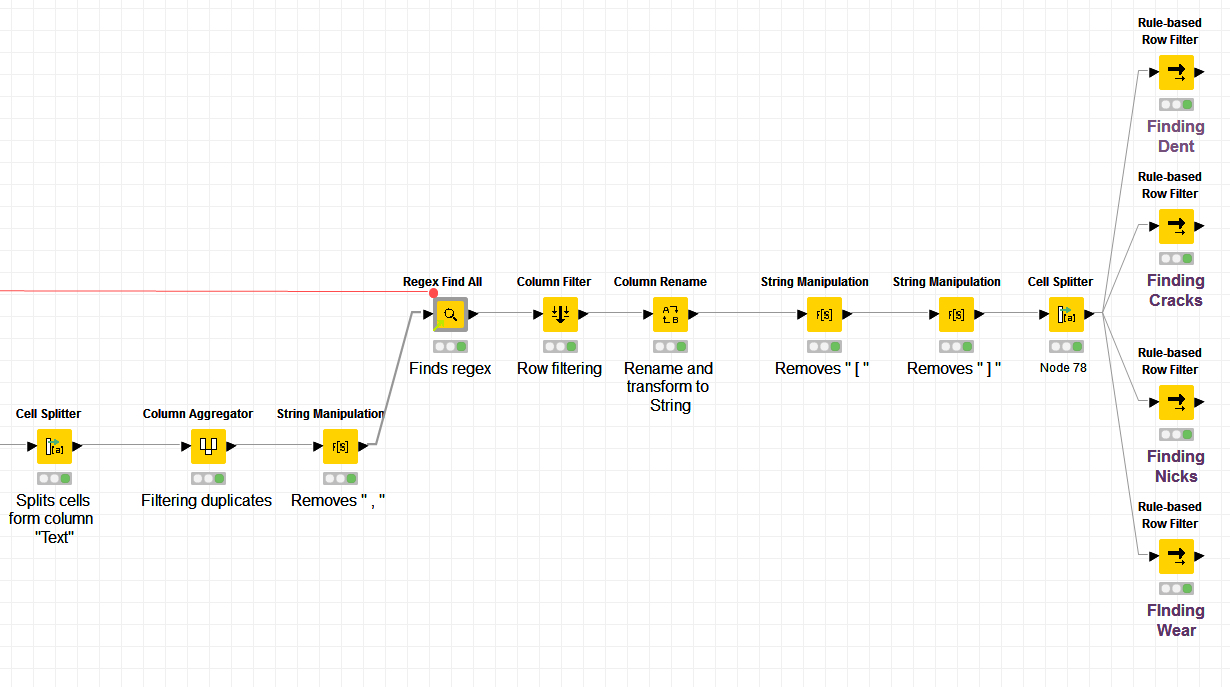
After manipulating the results (converting it into strings, etc.) I now want to match the rows to the appropriate findings. Right now I have a bunch of rule based row filters which output the rows with the corresponding finding. Is there a way to make it more “simple”?
It will look pretty “bulky” when I add about 7 or 8 more filters. Later on I´d like to show how many text belong to which finding (e.g. in a bar chart or pie chart). Do you have an advice for that?