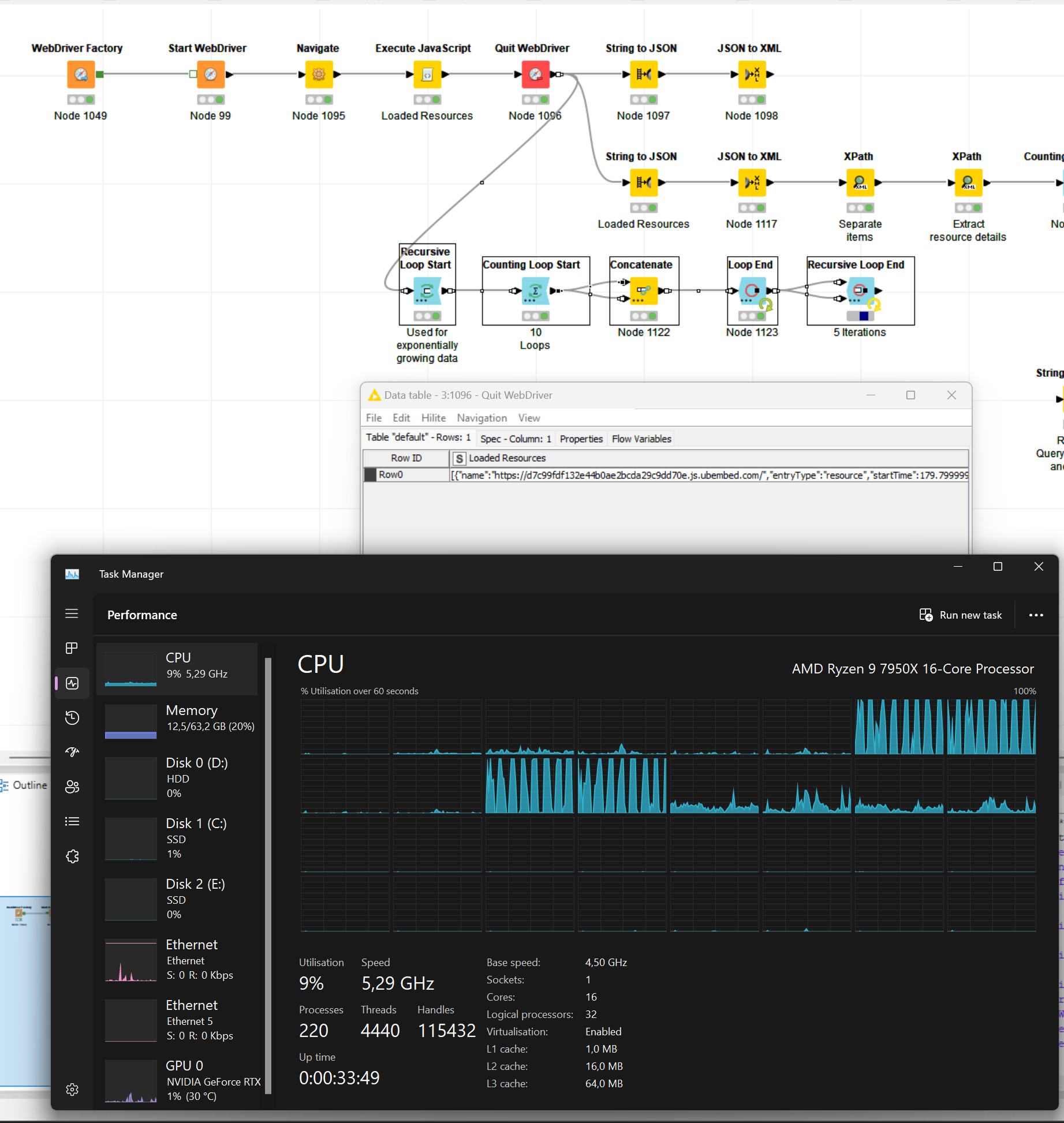
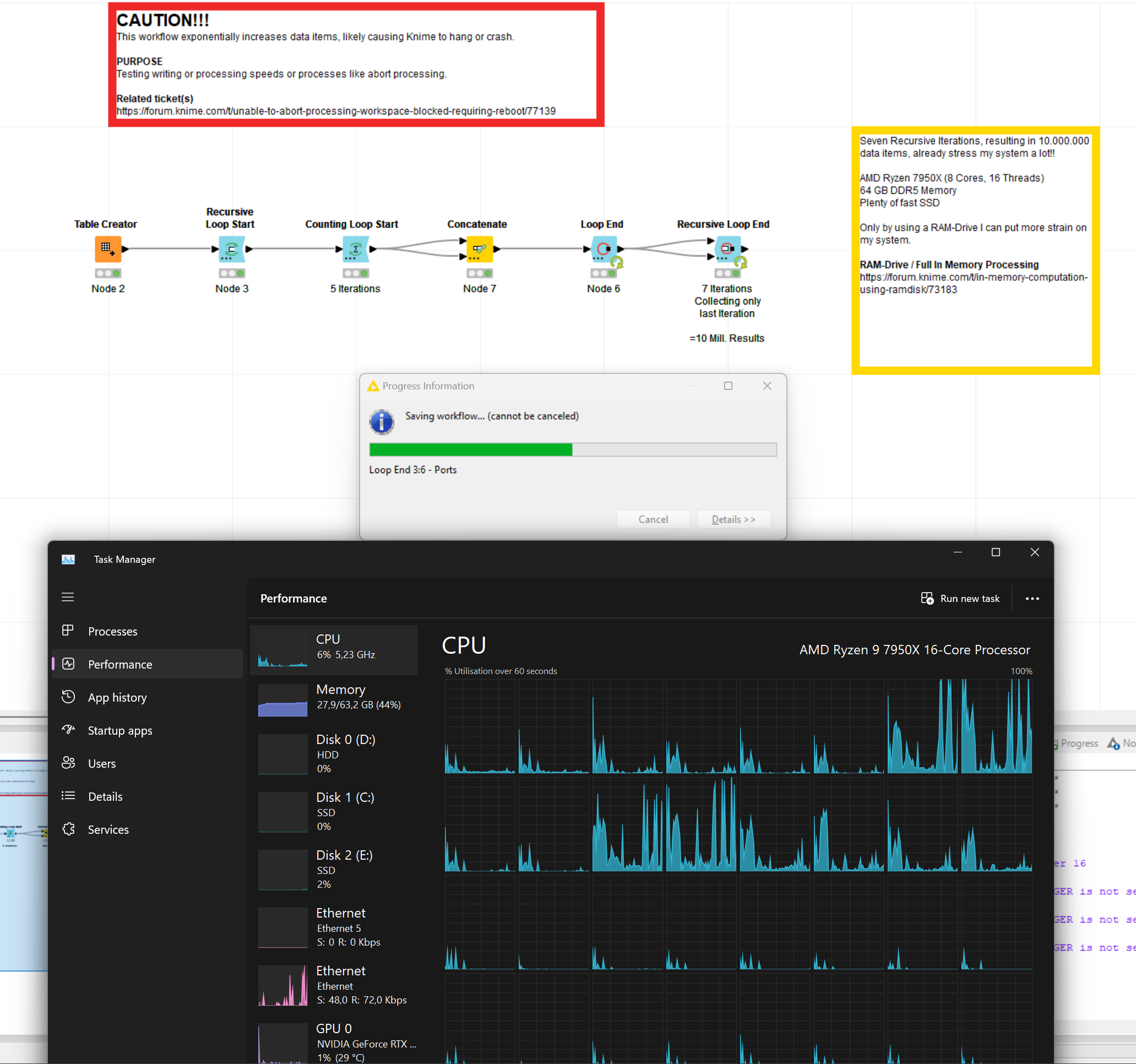
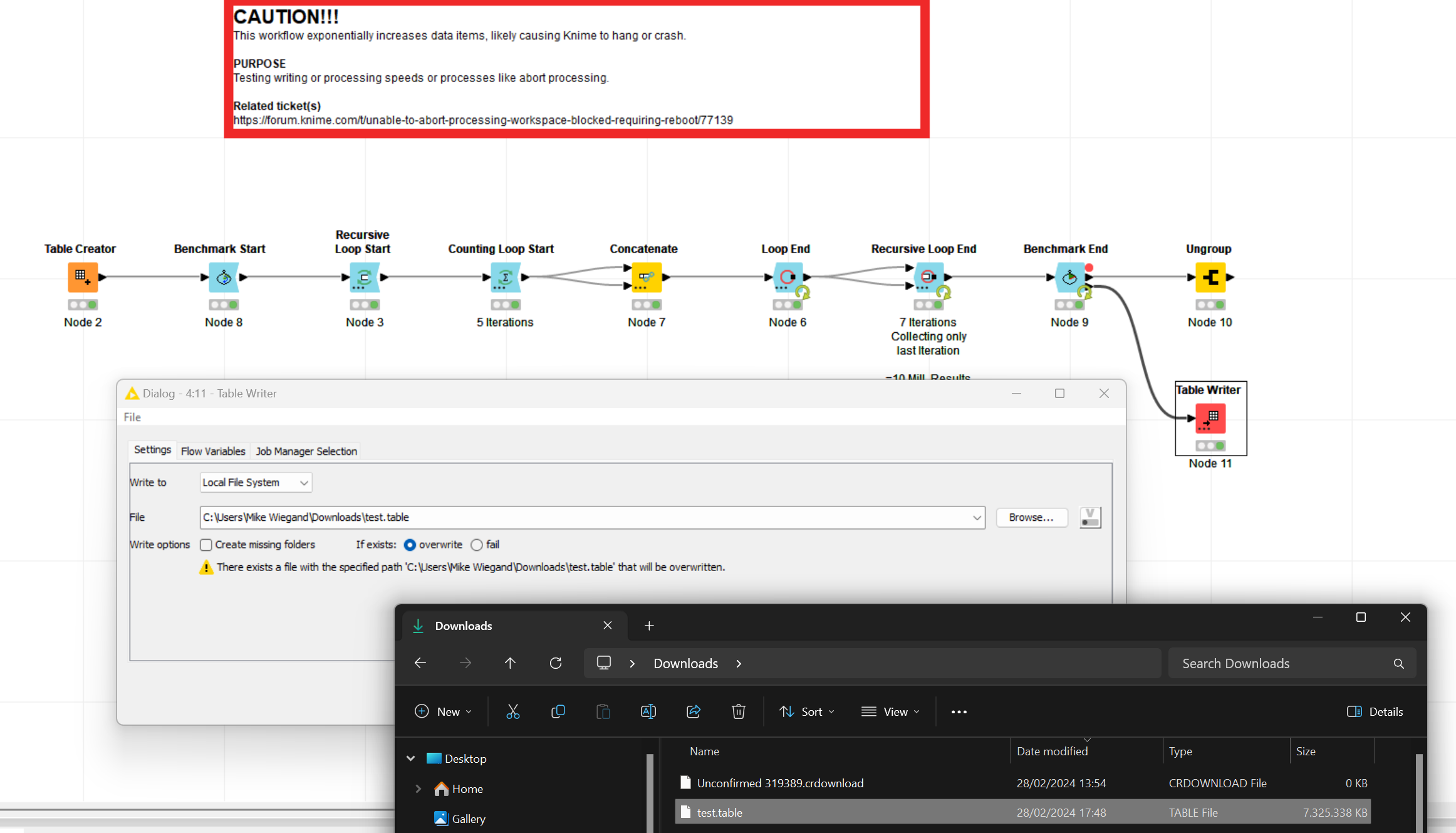
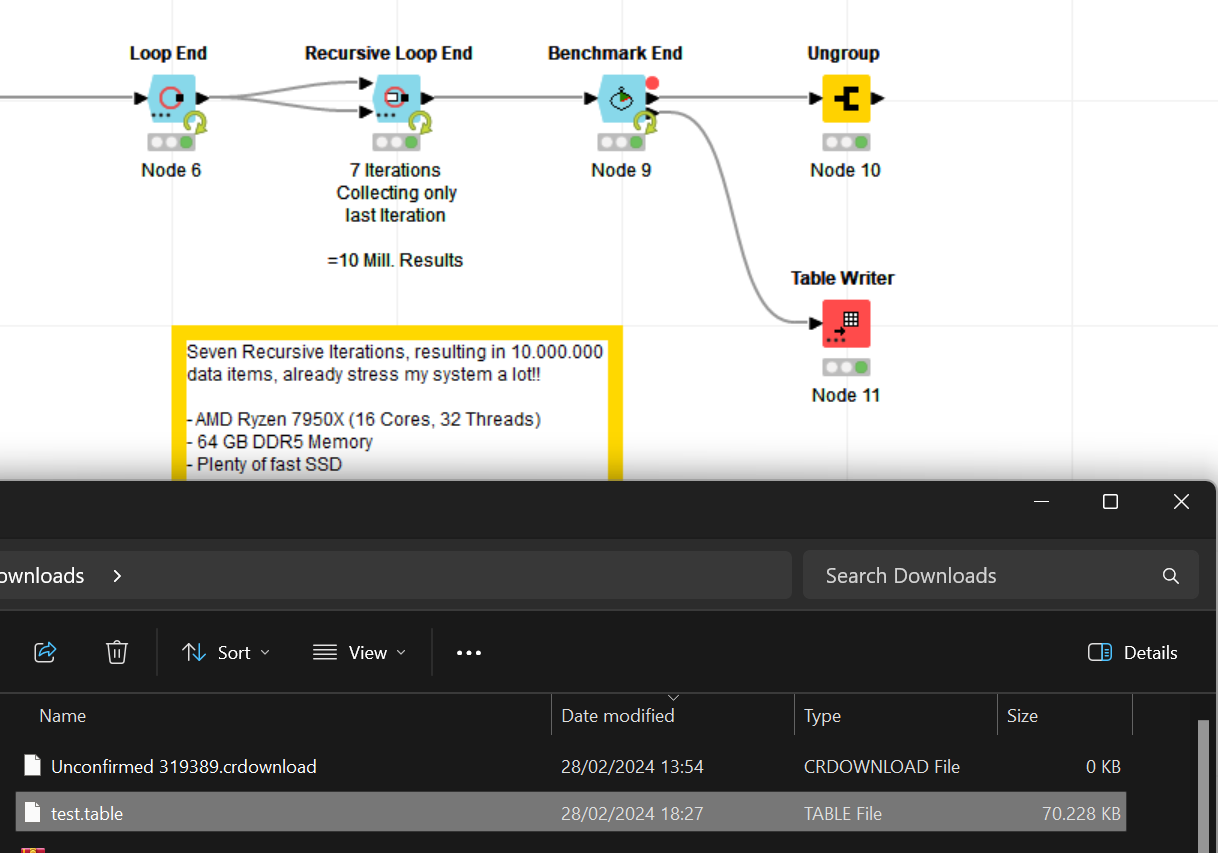
In order to back test improvements I created a workflow to exponentially increase the data (1 Row with some JSON). I encountered the issue before that Knime cannot finish due to the amount but I am equally unable to abort the processing.
Whilst I am able to close Knime and no background process is running, it seems some sort of lock file is still in place blocking the workspace. Hence, I am forced to restart my whole system.
I tested my systems limits and 10 Million data points seems to be the limit where it starts to struggle executing the workflow. Worth to mention that this performance issue was raised in other posts before.
Interestingly, though, several posts mention the arbitrary “sound barrier” of around 10 Million rows. Feels too much of a coincidence and I do recall, which dates back several major Knime versions by now, that handling several tens of million rows with hundreds of columns wasn’t even a problem on my old Mac Book Pro from 2016 with a mere 16 GB of memory.
Increase the count in the recursive loop end for greater steps and the one of the counting loop for fine granularity.
By the way, here is my system and knime config. I also tested different Xmx settings and Knime copes well with 2 and 50 GB ram allocation showing only marginal performance differences executing the workflow.
64 GB DDR5 6000 Mhz (tCAS-tRCD-tRP-tRAS): 32-38-38-96)
Note: Pretty fast memory which Ryzen needs to not “choke” itself
Two NVMe (PCIe x4 16.0 GT/s @ x4 16.0 GT/s) WD Black SN850X 2TB each
Note: The do not saturate the PCIe Gen5 lanes directly hocked up to the CPU!
NVIDIA GeForce RTX 3080 Ti with 12 GB GDDR6X (PCIe v4.0 x16 (16.0 GT/s) @ x16 (5.0 GT/s))
Note. Not saturating the PCIe Gen 5 lanes
Windows 11 Pro
Note: TRIM enabled, Debloated so all stubborn Microsoft and other bloatware got removed and more tuning done.
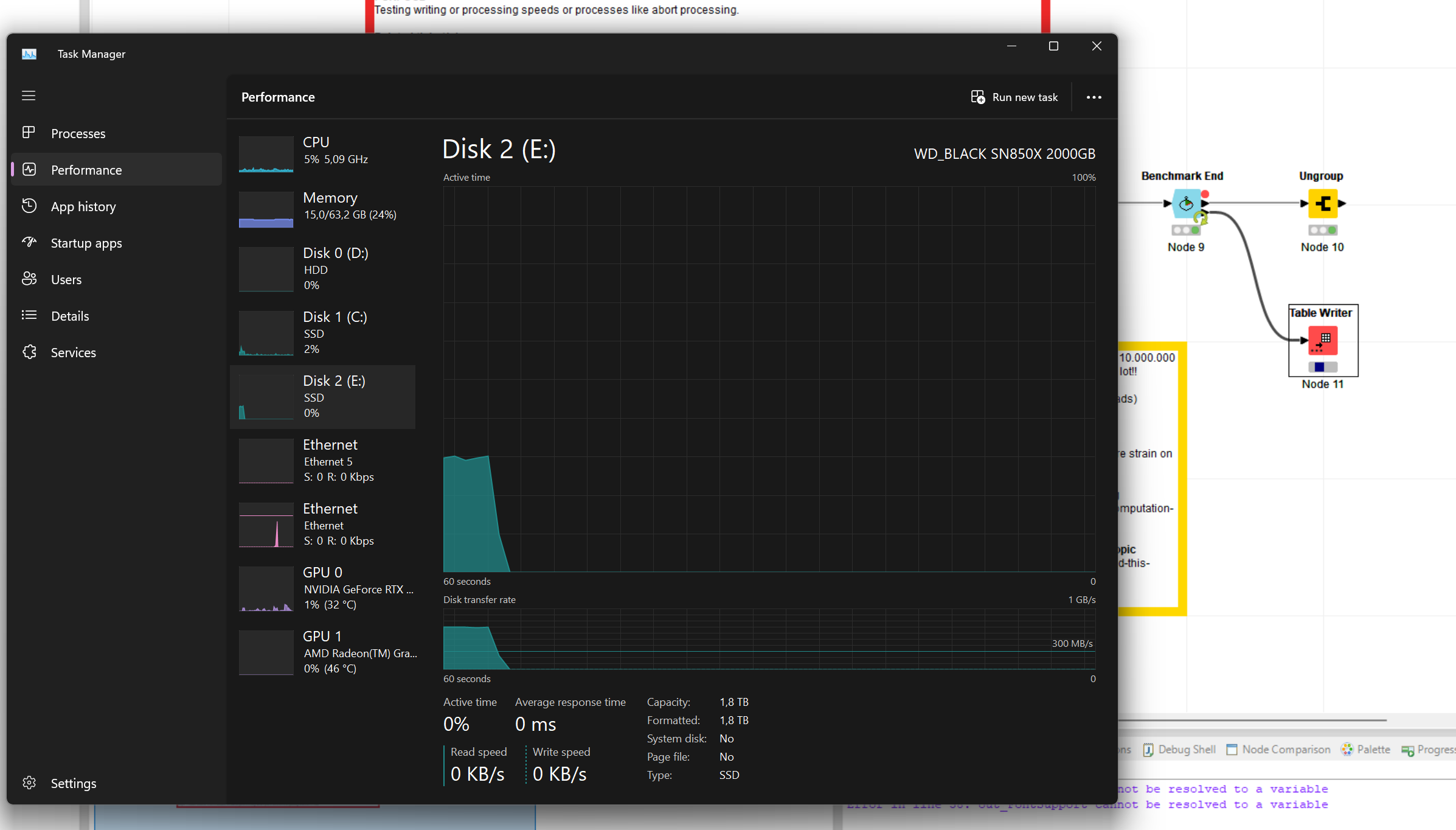
The saving process seems to be divided into several steps as upon triggering it, CPU but not Disk usage increases letting me to assume compression is happening. Though, I’d believe all data is already available and compressed in Knime tables or so. Disk usage actually never spikes during save.
PPS: I have my workspace located on the 2nd SSD separate from the OS. Still, I see data being cached in the users cache folder. That further strengthens the approach to split disk load but equally raises the question of possible data transfer bottle necks. Worth to note that disk usage didn’t exceed 1 % and I tried putting strain on disk utilization before.
@mlauber71 I did execute the inner loop facing little to no compute bottle neck. Though, that workflow is only for testing but not serving any apparent real live purpose.
Switching from row to columnar based backend I happen to notice a stark difference in processing time as well. Using the benchmark nodes, only running one iteration, the new columnar backend shows a stark regression.
@mwiegand is the problem you have with performance mainly present when you use loop or loops with a large amount of data or is there a general problem with large datasets.
What happens if you run the workflow I have provided?
The issue, not being able to abort processing, is mostly present when using loops. I just had a data set with around 19 million rows (around 1.8 GB as a knime table file), containing XML, from which I extracted data using XPath. Aborting didn’t happen immediately but concluded after some time.
Trying to save the data from my provided test workflow, disk usage briefly went up, on the disk where the workspace resides and windows, but then went flat but the writer node was still working.
Yes most likely. Do you have your modified test workflow?
Also if the data is not too exotic it might help to use parquet files in chunks - not a solution I know but maybe it is more stable and you can later use it as one file.
It the initial one, I always update it except if it would be stupid
I ran the workflow with -Dknime.compress.io=true and presto, data saved got condensed to astoninglishly small 70 MB. Wonder why yours is +400 MB, though.