I am just a beginner to the knime platform and I do not know if this is an easy problem to solve. My work requires me to read data from PDFs and work with that data. But, I have hit a roadblock recently as I could not find a way to read Non-OCR PDFs. I could not find anything related to this problem in the hub. Someone please help me with this issue.
I’ve added a Non-OCR PDF file down below from which I have to extract the whole page data.
I’ve provided a drive link as the site does not allow pdf type file uploads. Non-OCR pdf Drive link
Given a text-based PDF document with a table, can you partially extract the table into a KNIME data table for further analysis? For this challenge we will extr…
@Rohan5019 question has brought my attention because while reading it, it has reminded me something that I have experienced with scanned documents and that I always found amazing.
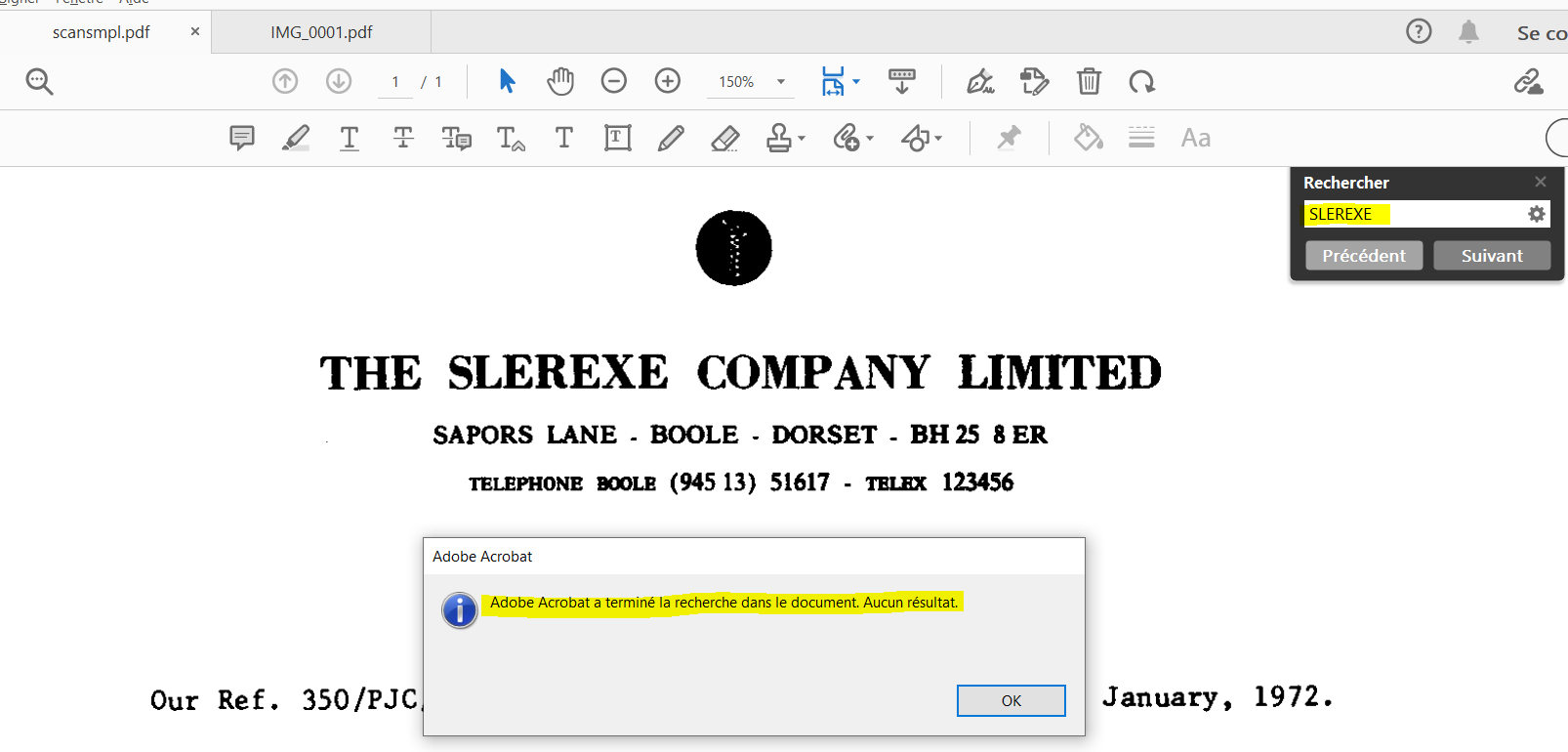
So I took @Rohan5019’s scanned document example and I tried to search with Acrobat Reader as sometimes I regularly do with scanned documents. Btw, as an scanned document, this is coded as an image behind the scene. When I “OCR” search for instance the word “SLEREXE” on this scanned PDF document using Acrobat Reader, I do not get any result, as shown as follows:
However, if I take the same document, I print it and then I scan it, then I can open it with Acrobat Reader and do a “OCR” search of words, as follows:
and amazingly it works. Is there anything in this initial scanned PDF document that prevents the Acrobat Reader (or any other tool such as the TIKA Parser) to do the OCR searching job ?
Hope this corollary explanation is of help to may be better understand @Rohan5019 question
I can’t comment on Acrobat’s behavior, but for the TIKA Parser it is only able to read information from a text-based PDF by design. To read an image-based PDF, you first need to perform OCR to get the text. If the TIKA Parser did this by default without prompting the user, that could be quite time consuming (if the PDF is large) and you may not even want the text (perhaps you only want the metadata). As well, OCR usually has a language based component too (which usually leads to better word prediction), so I’m surprised Acrobat did this.
To see what I mean, have a look at a workflow I made for Mac users who want to OCR (it requires Python to run, but the workflow itself is useful for illustrating what I mean without using Python).
First off, thank you for your reply.
What you have explained is correct, but there is also another type of PDF OCR problem, where we can look at the PDF as broken. In these types of PDFs, the OCR tends to be very inconsistent, recognizing some as text and some as static (or image) objects. This might be due to the file being a bit older or maybe the alignment might not be good. To be honest, Im not that well informed in this problem myself.
Thank you for this reply.
Yes, I’ve tried using the tika parser and also the pdf reader nodes and have got an output. But, the problem is that, the output is very inconsistent; some data from the file is not being read. Is there any other nodes that can help me with this problem?