Hi All,
I am new to knime and using the platform for last one month and need help. I can understand the platform has huge applicability but I know very less. Currently I am working in a text classification project. I followed the example Document_Classification from the example server. I am working on a ticket issue, which has the problem description as the text to classify, the categories, sub categories and ticket nos. I used Tree Ensemble Learner and Predictor for building model and got approx 88% accuracy. For one class the F-measure is very less and have to do error analysis on that class. For that purpose I need the ticket ids in my Prediction Output table so that I can pull data from the excel file and check the problem description of the ids which are not predicting correctly. I tried to load the ticket ids as String but it didnt work, couldnot do much with joiner too.
Iused the following nodes: Excel reader, Strings to Documents, ColumnFilter, Preprocessings nodes like PunctuationEraser etc,BoW,TermtoSting, Groupby,RowFilter,RowReference,TF, DocumentVector, CategorytoClass,ColorManager,ColumnFilter,Partitioning,TreeEnsembleLearner,TreeEnsemblePredictor,Scorer.
Please help me to handle the problem.
Thnx
Jhuma
In this case it would helpful if you could upload a minimal workflow example, along with an example of your ticket dataset (if it’s not confidential), to check your work and see where things might be going wrong.
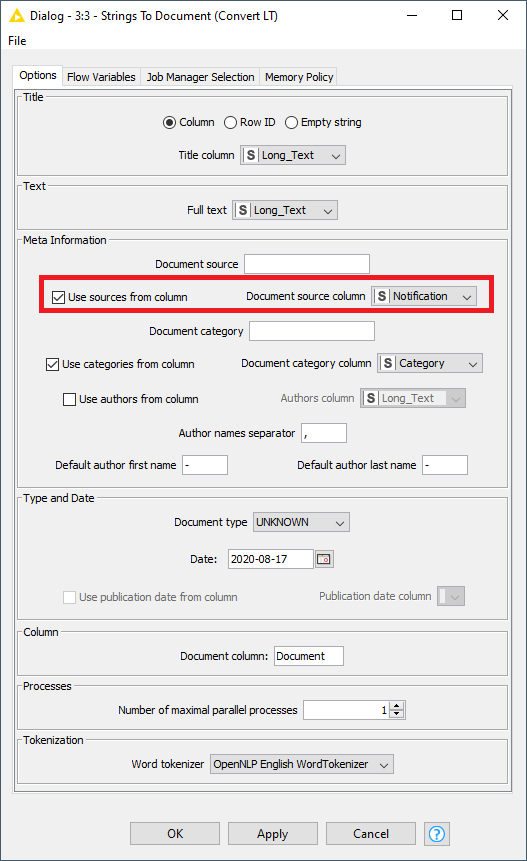
I am uploading the workflow,I have created a dummy data as I cannot share client data. I have taken the text from one of the classification examples. My question is howto get the Notifications(which is my unique id) in my Partition Output from the Tree Ensemble Predictor node. It will help me to identify the full text (the original text) which are not getting predicted correctly,…Also howto keep the Notification inother nodes like Document vector node,
Please help.
Can you provide the dummy data and stop word list? (When you export workflows, by default they are reset and the data is not included). That will help me understand why your unique ID isn’t being retained in the way you think it should be.
Hi Scott,
Please find the dummy data. Since this is a dummy one, so my custom stopword list wont work here. You can ignore the custom stopword list (It consists of the names of users who logged the ticket and persons who resolved it) The text I have used here, I have copied from an example in knime server and not the original one (as I cannot share the client information). My main motto is to get the Notification i.e the unique identifier in the Predicted Output from the Tree Ensemble Predictor node.
Thanks for providing your data. I think the key here is to convert your Notification field to a string before your Strings to Document node. Then, within that node, you can store the Notification as the source of the each document, as shown here:
Later in your workflow, after you have done predictions on your test set, you can use the Document Data Extractor node to pull the Notification back out from the Source field. Give that a try and let me know if it makes sense.
Thanks a lot Scott, its working fine now. I will check some more things to see if everything is working fine. I have used the Document Data Extractor after Column Filter node which is after my Document Vector node. I have taken the data in excel and also the Predicted Output in excel and now with vlookup I can the notifications back.Thanks again…
Also can you plz suggest any example in server to check how multi level classification is done on text data. As you can see I have different class on Category and also in Subcategory.
I don’t know that we have handy a workflow that deals with multi-level classification with categories and sub categories. What is it you’d like to do there? I guess as a workaround you could concatenate the category and sub-category together…?
Hi Scott,
As you asked What is it you’d like to do there?
I am trying to build a model in which if I get a ticket log which is my text my model should identify which category it belongs to and which subcategory it belongs to.
I tried building two models one for category(accuracy 88% ) and another for Subcategory(accuracy 82%) with Tree Ensemble learner and Predictor…I am not sure if it is the correct approach. Also tried to deploy the Category part, but the outcome is not good. I am getting 4 predicted correctly out to 10. So wondering whats the correct approach.
Also I will try by combining the category and subcategory. But if you come around any example plz let me know.
On second thought, ignore what I said about concatentation of categories - I think that’s a non-starter.
One thing you mgiht try would be a nested classification approach, where you classify according to the top level first, then use a separate model for the sub categories. If you wanted to get fancy, deep learning could be an option as well.
I’m hearing that one of our engineers may have a sample workflow already to deal with problems like these, but it may not have been released publicly on the KNIME Hub yet. Let me see what I can find out.