I set up an example that should look like your data (if not feel free to adapt and inform). We have two years of data (from one city) and data from January and want to predict the coefficient for Feb 2020.
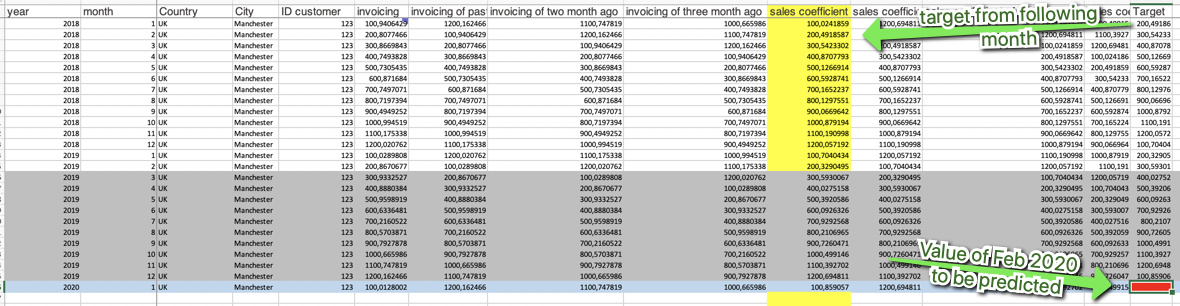
2019 serves as training and 2018 as test data. You might have more complex settings with cross-validation if you want. And also since you have the data you might provide coefficients of some more past months. Each line represents its own time series so to speak. Of course, such a setting depends on the connection you would expect from your sales coefficient. If they are influenced by external effects instead of seasonality (like in this example) you would have to add that information. And also in this example, we only have one city. Question is which of this additional information would provide any connection to the target. Eg.: if London significantly behaves different that Bristol it makes sense to include that information. Also you could substitute that info by giving the no of people living there or the no of shops that you have there. But it could be that all this is already captured within the sales coefficient.
Data preparation:
Model development:
Prediction of new data based on past information (Target= coefficient):

Of course, it would also be possible to use other time series methods that stress more the sequence of events (which here is provided by the coefficients of past moth and the number of the month). The assumption is that a typical April would behave like an April and that past coefficients ar a good forecast.
If want to try more advanced stuff you could try to adapt this workflow: