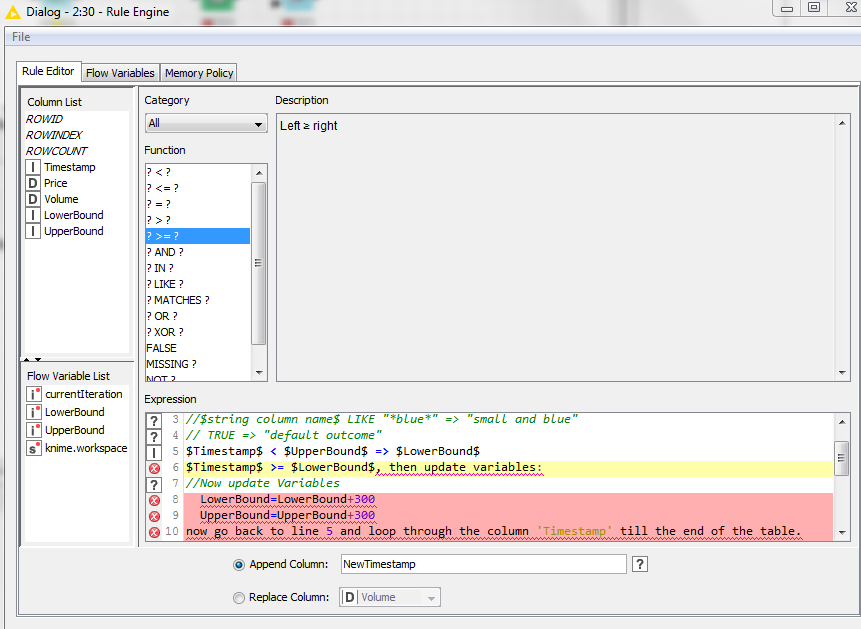
$Timestamp$ < $UpperBound$ => $LowerBound$
$Timestamp$ >= $LowerBound$, then update variables:
//Now update Variables
LowerBound=LowerBound+300
UpperBound=UpperBound+300
now go back to line 5 and loop through the column ‘Timestamp’ till the end of the table.
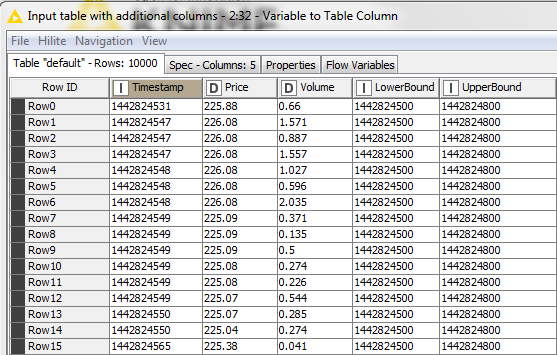
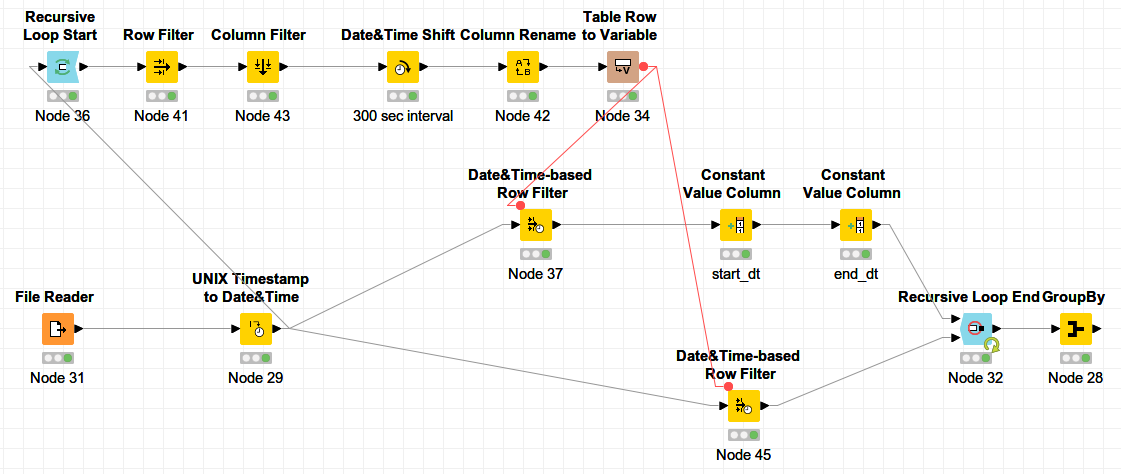
So what i want to do is find all values that lie in between the first 5min Interval, write for them in a new Column NewTimestamp the beginning of the interval (This is for one the Timestamp for that interval but acts as a marker, so that i can later use GroupBy for this column to aggregate the data for the interval in the next step). Then create the next interval by adding 300 seconds to the lower und upper border of the interval and continue to find all the values that belong int hat interval, then updaten interval again… and so on…
Upper and LowerBound don’t need to be actually in the table they could be flow variables too, i just wasn’t able to update them and continue the loop with the updated values. The column Timestamp is in ascending order.
My trouble was that i could check for the condition and write lowerBound in a new column, but the part with updating 2 Variables inside the loop and continue the loop with new values i was not able to do.
Hi izaychik63, could you (or someone else) post an example of this? I would be really thankful. Problem is i don’t get it how this would be used. Would i then still need a loop start and end? Or would i write the loop inside of this? - and i don’t really can code in java. I mean i would understand it if see something. If someone could post a quick example it would help a lot. But thanks for the tipp…
Hi Hans,
thx for that workflow. But the worfklow doesn’t build an time interval. Maybe it was a bit unclear what i wanted to do:
I give the process a LowerBound and an Upperbound as a unixtimestamp. The Input in the worfklow could be via FlowVariable or via Create Table.This would be for the file:
LowerBound= 1442824500
UpperBound= 1442824800 (its alsways 300 higher than LowerBound)
Then collect all the rows where the timestamp is between Lower and UpperBound as long as timestamp<UpperBound:
For timestamp (col0)<UpperBound
timestamp(col0) >= LowerBound AND timestamp <UpperBound
then write the timestamp of the LowerBound in an NewColumn for each row
Now increase LowerBound and UpperBound by 300 each.
LowerBound=LowerBound+300
Upper Bound=UpperBound+300
and continue with 2.
For example the file starts at Timestamp:1442824531
which is more readable:
21.09.2015 08:35:31
it would now start with the first given intervall (the unix timestamps above):
LowerBound:21.09.2015 08:35:00
UpperBound: 21.09.2015 08:40:00
Collect all rows that lie within these boundaries.
Write the Timestamp of the LowerBound in a new column then set the new interval:
LowerBound: 21.09.2015 08:40:00
UpperBound: 21.09.2015 08:45:00
and so on…
So that in the next step i can then can use GroupBy with Unixtimestamps of the beginning of the interval in the new column and make the Sum of Col2 (which is what i actually want).
The last 5 Lines with the If-Statement would need to run inside a loop for the whole table.
I would now need the Syntax for a loop, unfortunately i don’t know how to do it??
Does someone here know how to write a loop in the column expression node?
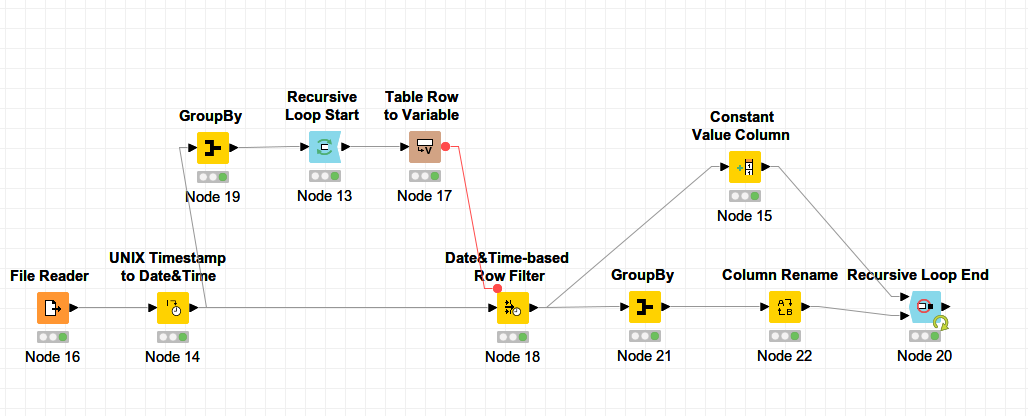
sometimes when developing (and expected solution is not working - Window Loop Start) you can try to start from the back or from end of requirement. In your case you need to perform (simple) grouping operation. Easiest thing to do is to use GroupBy node. So you need to go from your timestamp into timestamp you can as grouping criteria (column) meaning following:
Timestamp
LowerBoundTimestamp
2011-09-13T13:53:36
2011-09-13T13:50
2011-09-13T13:53:44
2011-09-13T13:50
2011-09-13T13:53:49
2011-09-13T13:50
2011-09-13T13:53:54
2011-09-13T13:50
2011-09-13T14:32:53
2011-09-13T14:30
2011-09-13T14:35:04
2011-09-13T14:35
2011-09-13T14:36:54
2011-09-13T14:35
2011-09-13T14:54:23
2011-09-13T14:50
2011-09-13T15:31:38
2011-09-13T15:30
2011-09-13T19:32:59
2011-09-13T19:30
…
Now to do above operation in KNIME (create LowerBoundTimepstamp column from Timestamp column) you can take couple of approaches/different nodes.
which you will then join in String Manipulation node with original timestamp with appropriate usage of substr() functions. From there you have it as you can now properly group.
Another similar way is to only look at single minute digit or calculate duration and then utilizing Date&Time Shift node (that wasn’t polish till the end but is interesting one…).
Notice: I tested my solution only on part of your data and workflow is not reset, UpperBound is not necessary and regarding time execution all three nodes I used are streamable so you can try streaming functionality to speed things up once you are done developing.
Hi Ipazin fellow traveler, i just stumbled across your post. Well that looks interesting especially since it uses streaming, something i want to try.
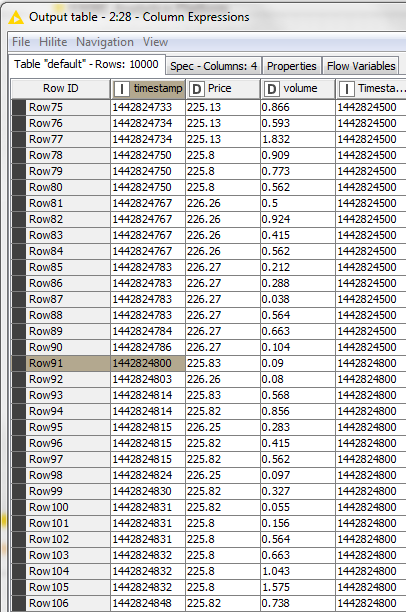
To the problem I found a solution now that is similar to yours but integrates all in one formular and is computational very efficient. One just writes in a column expression node, and saves as a new integer column:
The variable “start” ist just flow variable with the desired startdate as a unixtimestamp e. g. =
1442824500
With this variable in the new column one can just GroupBy.
(I don’t want to post the whole workflow since it contains a lot of adjustments, column renames etc. that are user specific) In core its just that formula.
Since its very easy for computers to calculate integers, the Formula finished in just 26min compared to 2:45h min for Window Start.
Right now there are still some differences between this Data and the old data, so i don’t want to scream Juchu to early. But i think that those differences are due to an errenous rounding in Access…
But i wanted to check back.
@izaychik63 thanks for the tip with the rule engine - it made everything possible! @HansS: Thanks for your version 2. I played quite intensively with it - lots of interesting application of principles didn’t understand everything. The problem was a bit speed it was simply not fast enough i think the Recursive Loops slow it to much down…
So thank all of you without you i wouldn’t have made it this far…