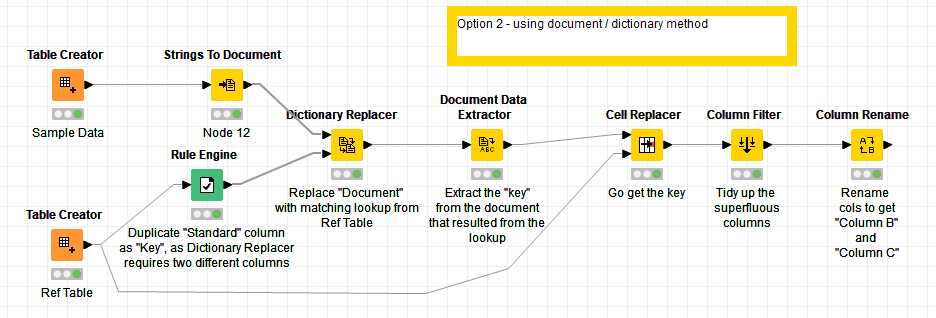
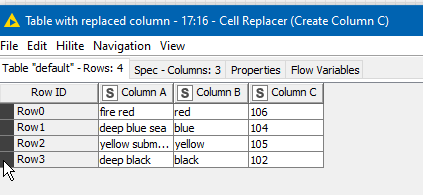
As you can see. I want to add data in my orginal file via a reference table (e.g. via table creator). Search criteria is only a part of a string.
The rule must be something like that.
If you find “*green*” in Column A add “green” in column B and “101” in column C
If you find “*black*” in Column A add “black” in column B and “102” in column C
If you find “*white*” in Column A add “white” in column B and “103” in column C
If you find “*blue*” in Column A add “blue” in column B and “104” in column C
If you find “*yellow*” in Column A add “yellow” in column B and “105” in column C
If you find “*red*” in Column A add “red” in column B and “106” in column C
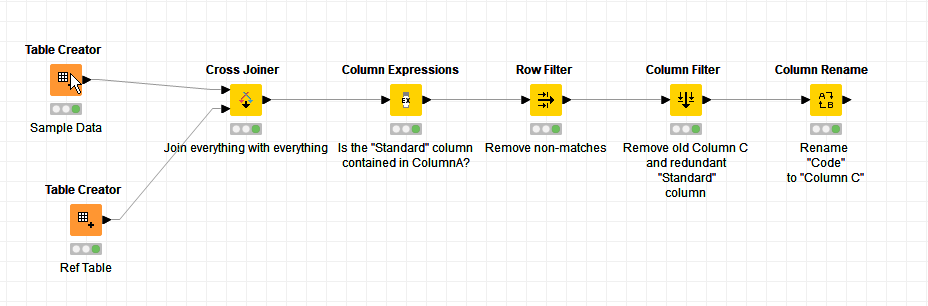
Hi @AndreP , depending on just how much data you’d really have, this is one possible solution. It involves joining every row of your reference data with every row on you sample data table using a cross join.
After that, a rule can be used to say for each row "is the ‘standard’ column contained in the text of ‘Column A’. Filter out those rows that don’t match, and then filter and rename the columns that you have remaining.
There are variations that could be done on this workflow in terms of how “Column B” gets created (I do it in the Column Expressions node, but the Column Expressions could simply return a “Y/N” flag, and then you’d filter on that and rename Standard to Column B. )
I also found an alternative using somewhat more “exotic” nodes…
I’d imagine this might work be less resource hungry if you have large data sets (cross joins can get very memory hungry if you have large numbers of rows in both tables). I’ve not played with Documents and Dictionaries in Knime before so there might be some shortcuts to this, but it’s a start!
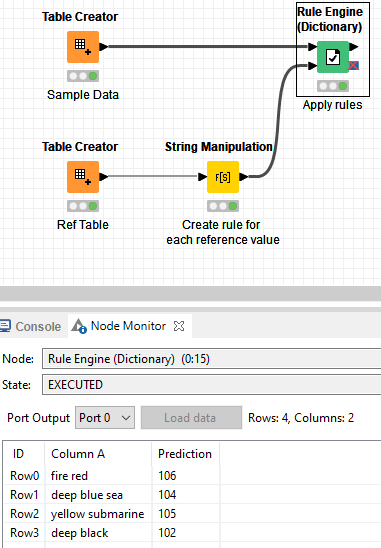
even better as you don’t have to use GroupBy node and convert rules to flow variable. And additionally you can simplify expression in String Manipulation node and define output column in Rule Engine (Dictionary) node. Nice one
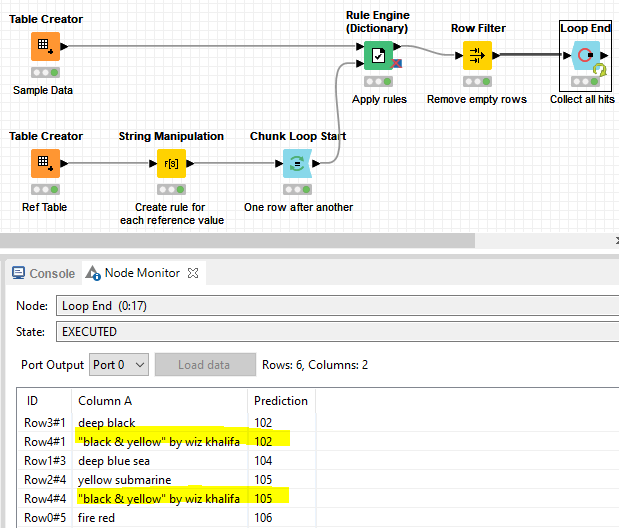
One more addition I’d like to propose: the Rule Engine will read the rules from top to bottom, so if more than one rule could apply, only the first rule would be applied. Let’s say I’d add “black & yellow by wiz khalifa” to the sample table, you’d want to see matches for “black” and “yellow”. You can use a loop that feeds one rule after another into the Rule Engine, so each rule will be treated equally, and remove rows without any matches.
If you want to do math with the assigned values (e.g. calculate sum or mean of each group via a GroupBy node), you’d probably want to change the String Manipulation node’s content to join("$Column A$ LIKE \"*", $Standard$, "*\" => ", $Code$), so the result would be an integer. That’s what I’ve done in the workflow below:
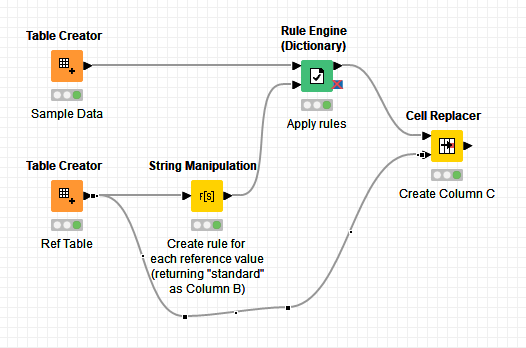
@G47_2 , that’s great. I added a slight mod to yours [your first post], for the benefit of the OP to get the full result back as per the Column A,B,C but both your and @ipazin’s workflows have provided new insights, which is what this is all about!

 nodes…
nodes…