Hi,
you can always rename the column to a specific name and rename it after the Math Formula node e.g. by storing the original name in a flow variable and using that in the Column Rename node after the math formula.
Another option, if the index of these columns remain the same and only the name changes, is the Column Expression Node, which is part of the extension ‘KNIME Expressions’.
This node also provides mathematical functions and you can access columns dynamically.
Unfortunately the syntax is slightly different as you have to provide the column index yourself:
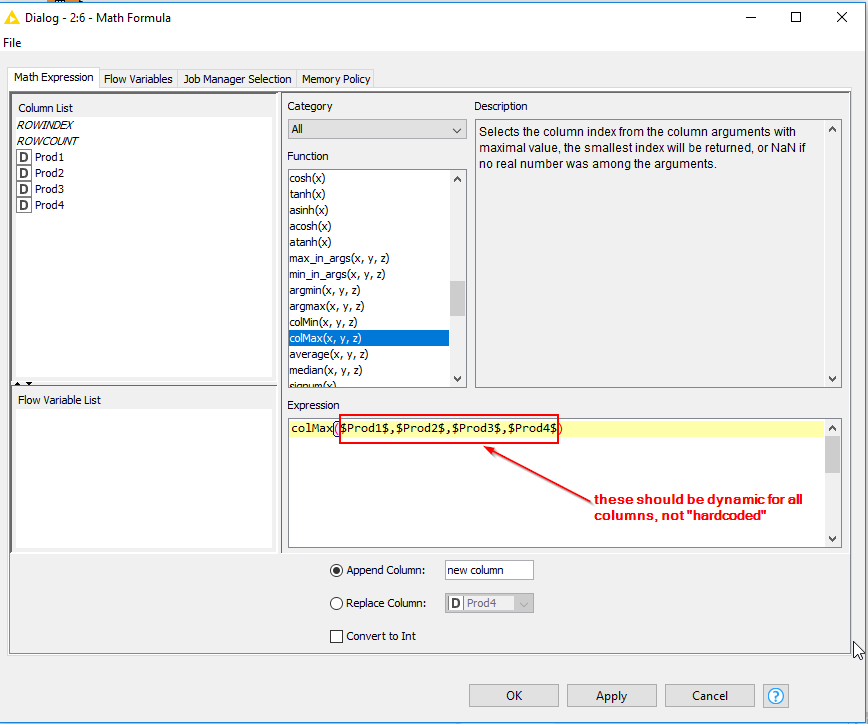
colMax(column(“Prod1”), 0, column(“Prod2”), 1, column(“Prod3”), 2, column(“Prod4”), 3)
where 0, 1, 2, and 3 indicate the column index of the columns Prod1, Prod2, Prod3, and Prod4.
In this specific casethe following line is equivalent:
colMax(column(0), 0, column(1), 1, column(2), 2, column(3), 3)
If the column index does not remain the same you can do something like:
names = arrayFlat(columnNames())
colMax(column(“Prod1”), arrayIndexOf(names, “Prod1”), column(“Prod2”),
arrayIndexOf(names, “Prod2”), column(“Prod3”), arrayIndexOf(names, “Prod3”))
Now the dynamic part: you can extract the names you want to use into a flow variable and instead of writing:
column(“Prod1”) you could acces the column via column(variable(“firstCol”)).
Cheers,
Moritz