Hello.
I’m trying to implement the BERT embedder NLP algorithm to my workflow to do some linkedin text based analysis. My problem is that once i get the embedded vectors deriving from the columns im using as variables(such as job or education), knime doesn’t allow me to perform linear regression (or any other ml algorithm for that matter) on it, as vectors are not the correct data type for learners. What can i do to fix this?
Hi
you either need to use a neural net, possibly directly with python node or you could try to split the vector in individual cells and then use those as features for your ml model
br
Hi @rickybordon & welcome to the KNIME community forum
As mentioned by @Daniel_Weikert, you most probably can split your column of “vector-like” type into separated columns, for instance using the -Split Collection Column- node.
The following workflow shows how to do it on a column of type bit vector (but the node can normally split any type of vector data):
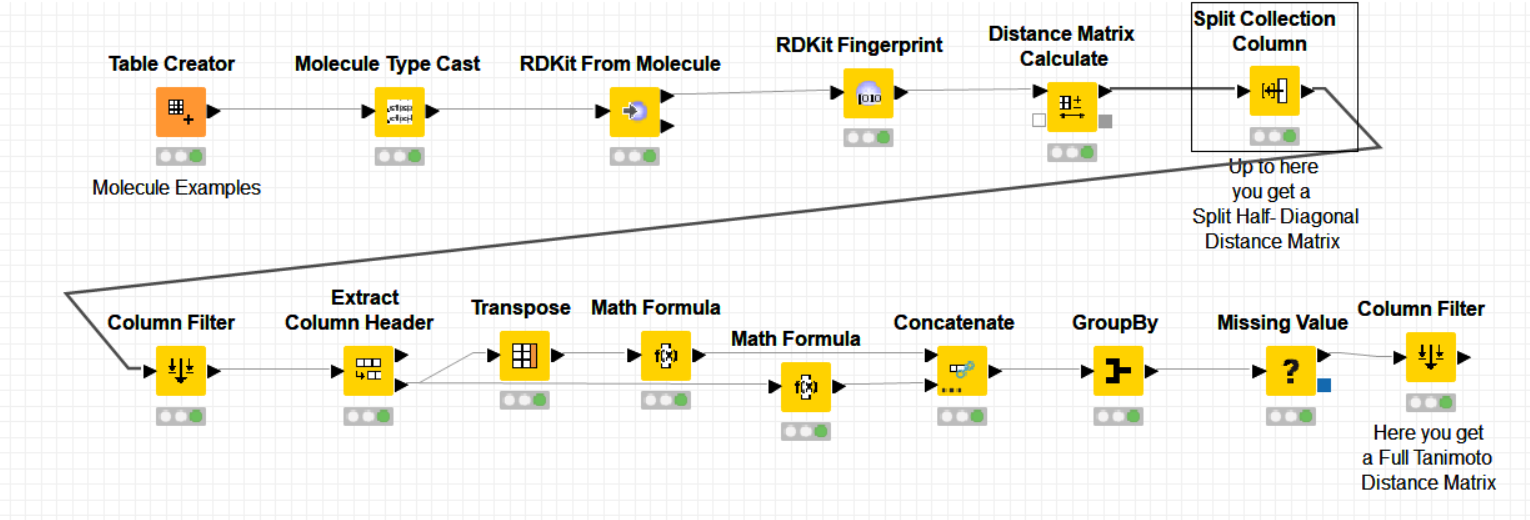
If this example doesn’t help, please upload here an example of your data on a KNIME workflow so that we can take the problem from there and help you further.
Best,
Ael
3 Likes
Thank you for your answers. I had already tried splitting the vector in multiple columns but, since i am trying to use learners such as OLS, i would expect so many columns (the embedder gives vector with 150 numbers) to create a situation of overfitting. Furthermore i’d think that columns made of random numbers (one of the 150 that make up the vector )wouldn’t have a concrete meaning for a regression. Am I wrong for thinking that? Do you think that other learners could use these raw numbers as meaningful imput?
Thanks again for the support
Hi @rickybordon
It is difficult to answer your question without having access to your data nor knowing how many data samples your data contains. Besides this, the problem of overfitting with 150 variables (columns) is not dependent on the way you code your columns, either as a compact vector or as separated columns.
One would most probably need to do some variable normalisation & selection before applying a OLS regression model on top of knowing whether the underlying regression problem is linear or not.
I would hence recommend to use first the -Tree Ensemble Learner (Regresion)- and the -Tree Ensemble Predictor (Regresion)- nodes which can achieve regression and are resilient to overfitting in view to checking how well a non-linear regresion model could perform.
Hope it helps.
Best
Ael
My question would be why you need embeddings for your regression at all? Is there a particular reason for using bert embeddings? Just curious.
I have only used them for NLP tasks so far (I am not a data scientist)
br
To go a little more in detail my project consists in profiling optimal leads for the proposal of the product my company sells. Basically in the past years the majority of outbounds operation was done through linkedin, and such operations were recorded on a crm.
The database i have consists of thousands of leads, with their job, experience, education, interests etc…
Unfortunately these data are not standardized and, consequently, i need an embedder to get a meaningful prediction for what charateristics to look for. If you have any advice on how to do this kind of analysis without recurring to embedding i’m all ears
1 Like
So you can’t “map” your features to some kind of standard features? What kind of client data do you actually embedd using vectors. Maybe you could only embedd the features individually to map them to a specific value?
br
Thats what i hoped to do in the beginning but every possible job, experience and such are written in many, many different ways, considering that the dataset is managed by 10 different people. The entries are also way too many to standardize by hand ![]()
Hi @rickybordon
The workflow you have posted comes without data and the excel data uploaded along doesn’t seem to be the input data for the workflow you posted. Can you upload the workflow executed so that it becomes easy to inspect and understand what the workflow does ?
Thanks
Ael
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.