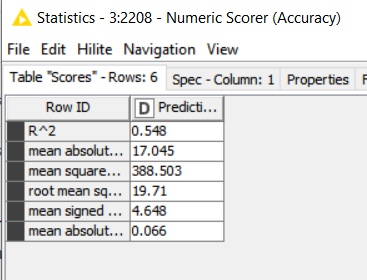
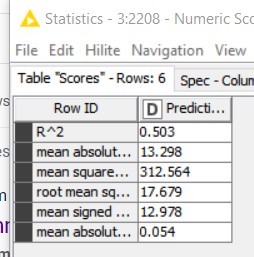
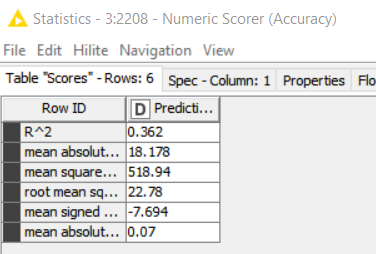
I’ve done something wrong…Each time I run a KNIME linear regression I get wildly different R2 and MSE results using the exact same data. All I am doing is disconnecting the data node, then reattaching it–with zero changes to the data or the regression–and each time I get very different results.
The same thing happens with KNIME Random Forest, H20 Random Forest, and H20 Gradient Boosting.
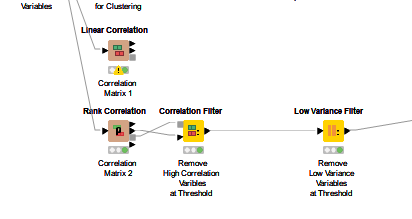
The data set is small, but I pared down the variables using the Correlation Filter and Low Variance Filter.
I stumbled on this occurrence as I was testing different models for the best outcomes on this data–but when the target moves every time that’s not possible.
All I am doing is disconnecting the data node, then reattaching it–with zero changes to the data or the regression–and each time I get very different results.
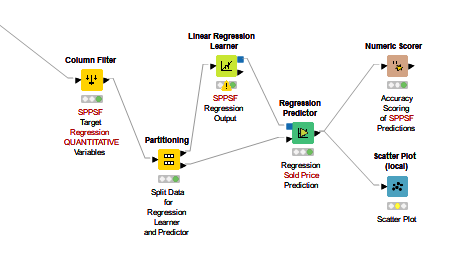
the data was the excel file i posted on the chat earlier. here is the portion of the workflow i was testing the regressions on. i was going back and forth with the same data using different regressions to see what would work best on my data–and stumbled on each regression R2 changing each time i ran the data by accident. then i noticed it happens on all of my regressions. I must have set something up wrong.
You’ll see two regressions series: 1) my full data, 2) a subset of just ranch style homes (the marketplace values them differently from the others, so that’s what i was experimenting with.
just in case my data did not come through with the wf, i also posted the excel file here.
There are other missing excel files that prevent the workflow from being run.
In your previous post, you talk about disconnecting the data node then reattaching it. It’s still unclear to me what this means.
If I were to hazard a guess, I’d say the problem is that you’re creating branches of data and doing a random 70/30 split before each of your regressions without electing to use a random seed. Therefore, the results of each of your 70/30 splits will be different every time the nodes are executed, and since each regression node is operating on a different set of training data every time it is run, the regression results will be different.
when i state “disconnecting”,…once i suspected i was getting non-repetitive results I would simply disconnect the data node from the first step in the regression series (delete the connection), then simply reapply the connection.
I will have to investigate the random seed set up. I’m not a data scientist, so you are likely correct in my error in setting up the experiments. thank you
Just FYI: i researched the partitioning options further; based on how I prepared my data for other tasks before the regression series, the “linear sampling” appeared to be a good option for me. thanks again for the help.