I was looking to load my custom pyspark models from jupyter notebook through python node and i can see documentation that knime will only support jython and also is there way to save model as pickle format and loading of the model for scoring. Any help would be appreciated.
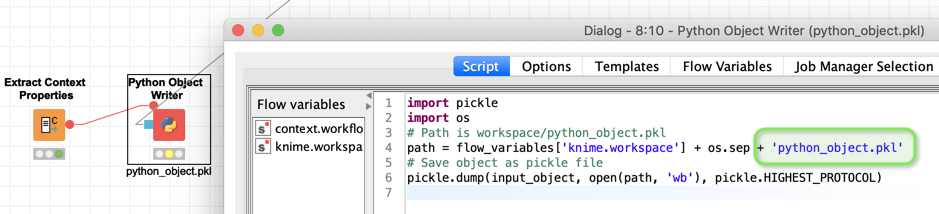
I think you can use pickle (.pkl) at any point within the the Python nodes in KNIME. You would just have to provide a path and a name. And you might want to automate the file paths in order to store the models where you would find them again - use the workflow path
Hi,
Thanks for your reply. can you please tell me whether the nodes support python or jython in documentation it is showing jython. Can you please share any workflow that save and load the model using pickle
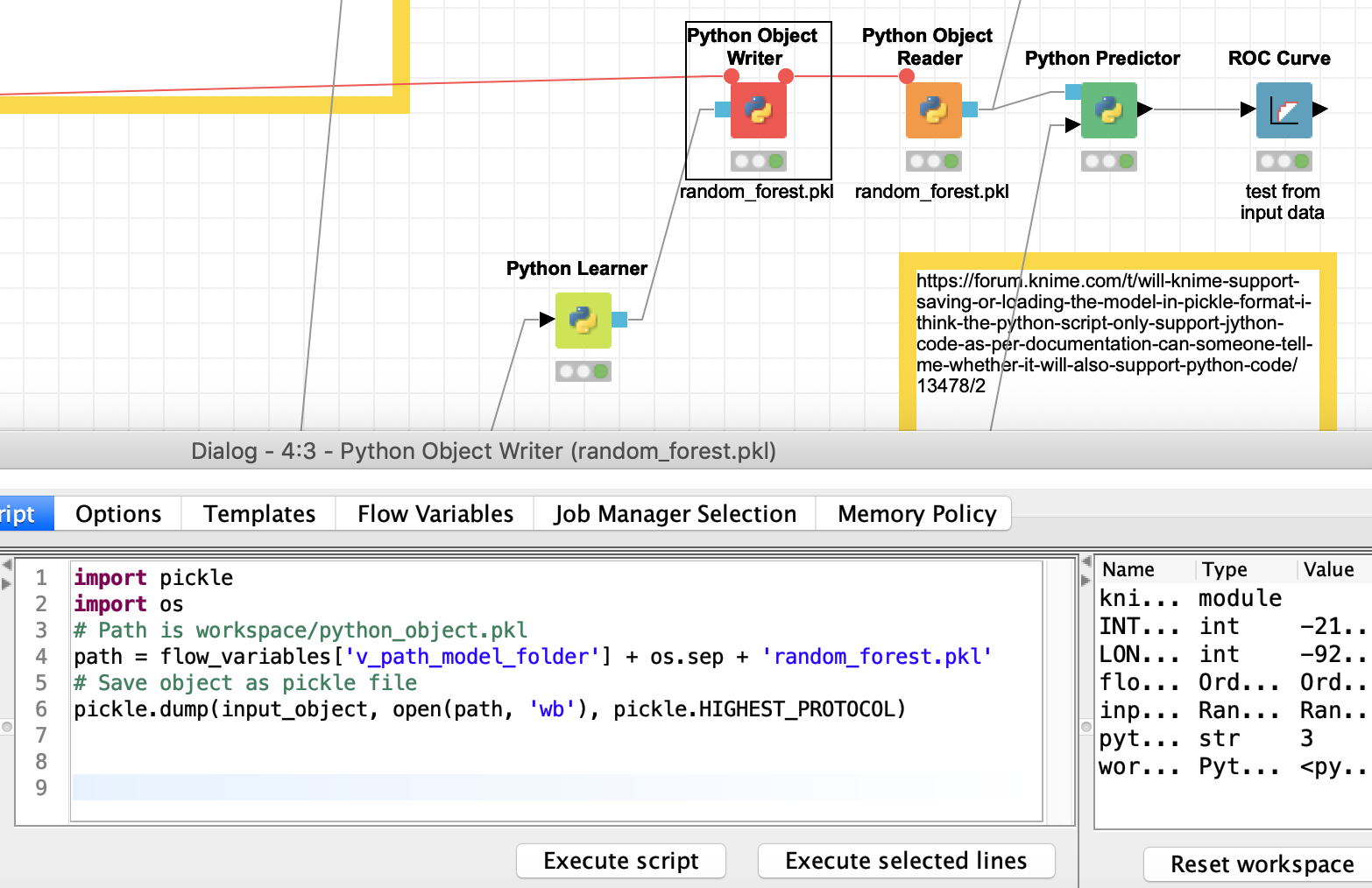
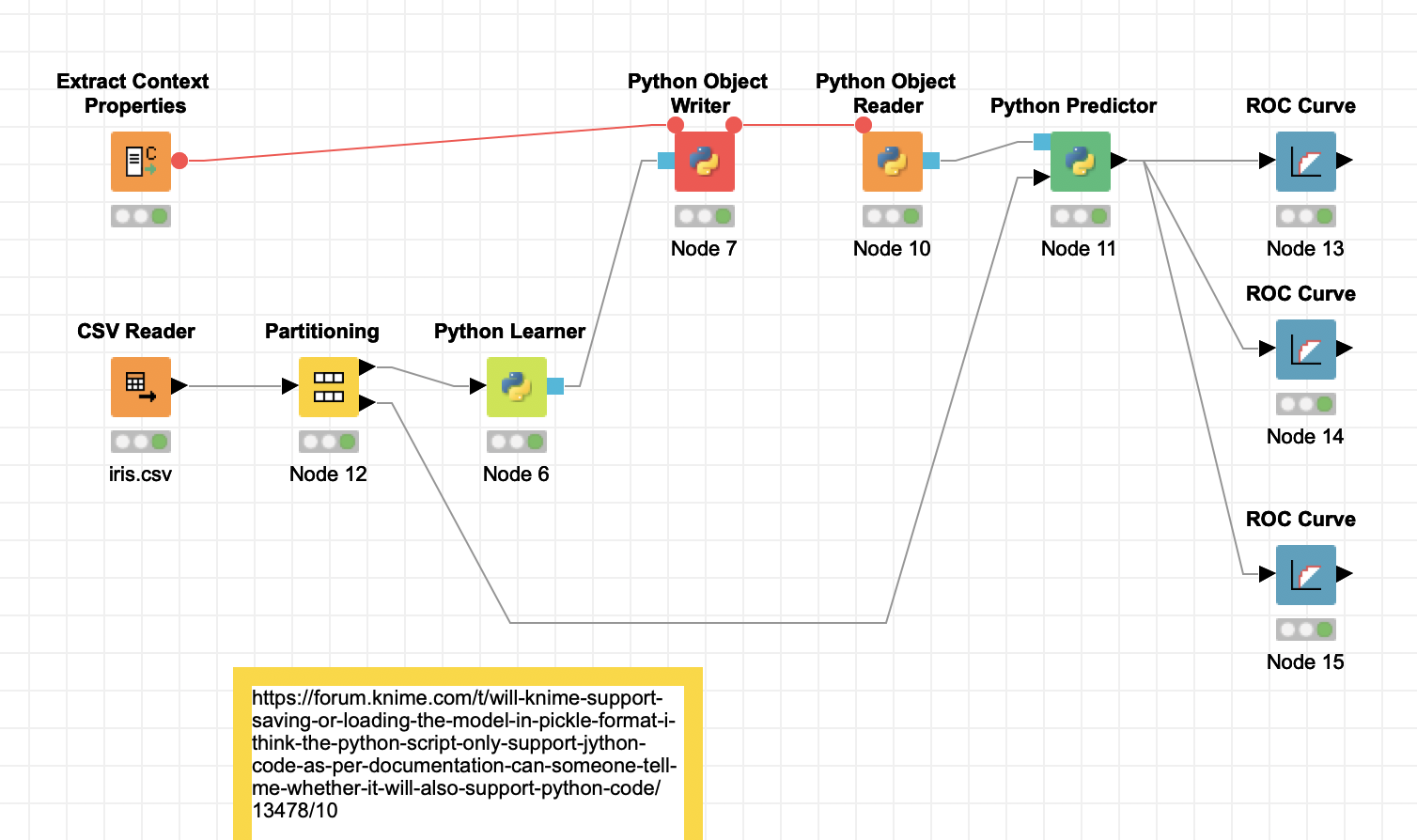
Yes I can. The attached workflow uses Python Random Forest Learner, stores the model as Pickle file and reads it again.
The structure with Object Writer is mainly there to follow a common KNIME structure. Technically it also does work to just do everything within a Python Script node.
Not sure about jython in that context. Pickle could be written as binary (“wb” write binary).
Hi,
Thanks for your reply. I was planning to make a workflow where data will be read from File reader and then trying to load jupyter notebook where there is a code for data_cleaning, one_hot_encoding and model building. can we use the entire process of the notebook and then save the model as pickle using python learner node. I was getting below error when i am trying to execute the python script node.
2019-02-19 12:44:45,772 : DEBUG : KNIME-Worker-17 : Node : Python Script (1⇒1) : 0:2 : Execute failed: Could not start Python kernel. Error during Python installation test: Could not find python executable at the given location: python3… See log for details.
org.knime.python2.kernel.PythonIOException: Could not start Python kernel. Error during Python installation test: Could not find python executable at the given location: python3… See log for details.
at org.knime.python2.kernel.PythonKernel.testInstallation(PythonKernel.java:370)
at org.knime.python2.kernel.PythonKernel.(PythonKernel.java:245)
at org.knime.python2.nodes.script.PythonScriptNodeModel.execute(PythonScriptNodeModel.java:85)
at org.knime.core.node.NodeModel.execute(NodeModel.java:733)
at org.knime.core.node.NodeModel.executeModel(NodeModel.java:567)
at org.knime.core.node.Node.invokeFullyNodeModelExecute(Node.java:1186)
at org.knime.core.node.Node.execute(Node.java:973)
at org.knime.core.node.workflow.NativeNodeContainer.performExecuteNode(NativeNodeContainer.java:559)
at org.knime.core.node.exec.LocalNodeExecutionJob.mainExecute(LocalNodeExecutionJob.java:95)
at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:179)
at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:110)
at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:328)
at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:204)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123)
at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246)
2019-02-19 12:44:45,772 : DEBUG : KNIME-Worker-17 : WorkflowManager : Python Script (1⇒1) : 0:2 : Python Script (1⇒1) 0:2 doBeforePostExecution
2019-02-19 12:44:45,772 : DEBUG : KNIME-Worker-17 : NodeContainer : Python Script (1⇒1) : 0:2 : Python Script (1⇒1) 0:2 has new state: POSTEXECUTE
2019-02-19 12:44:45,772 : DEBUG : KNIME-Worker-17 : WorkflowManager : Python Script (1⇒1) : 0:2 : Python Script (1⇒1) 0:2 doAfterExecute - failure
Please tell me the solution for the above and also share example workflow to use jupyternotebook code directly for datacleansing , model building…etc
Hi
I have resolved above i am facing below error when i am executing python node. ERROR Python Script (1⇒1) 0:2 Execute failed: Traceback (most recent call last):
File “C:\Tools\knime_3.7.1.win32.win32.x86_64\knime_3.7.1\plugins\org.knime.python2_3.7.1.v201901281201\py\PythonKernelBase.py”, line 278, in execute
exec(source_code, self._exec_env, self._exec_env)
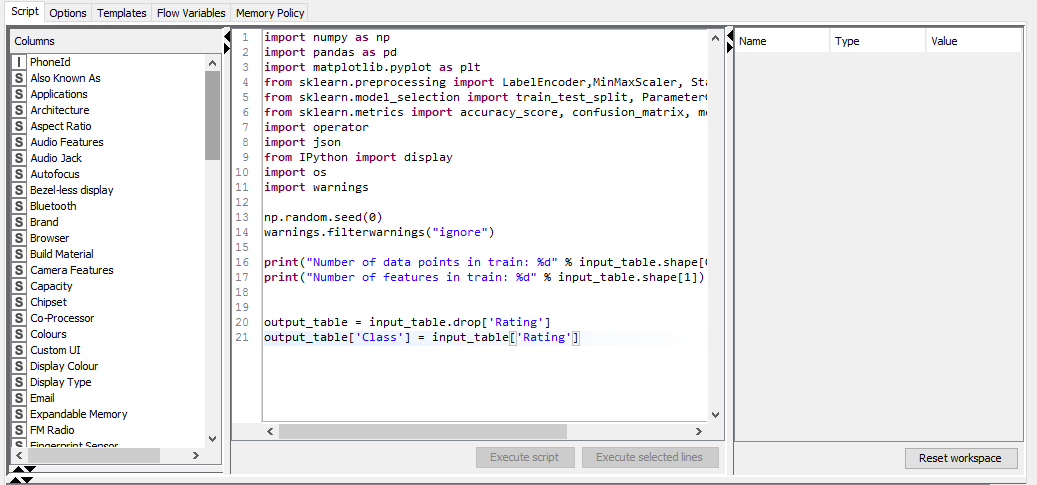
File “”, line 20, in
TypeError: ‘method’ object is not subscriptable
1.Can we write the data cleaning code in the script or the python script is only to provide jupyter notebook path??
2 I have loaded my train.csv file in the file reader and made connection between script and file reader when i am trying to take the input as train.csv it is showing as file missing even though i made connection between nodes. or name of data set will changed when we make connection between nodes??
As for the error, changing line 20 from ... input_table.drop['Rating'] to ...input_table.drop('Rating') should resolve the problem (note the round brackets instead of the square brackets).
Regarding your questions:
You can also put the data cleaning code directly into the script. Also note that Python scripting nodes are capable of importing external Jupyter notebooks and using their functionality directly, as explained in this blog post.
I don’t fully get that question. Could you please elaborate or upload an example workflow that illustrates your problem? The input data to a Python scripting node (that is, the content of the train.csv in your case) is made available to the Python script via the input_table variable (as you can see in the screenshot you provided).
Hi,
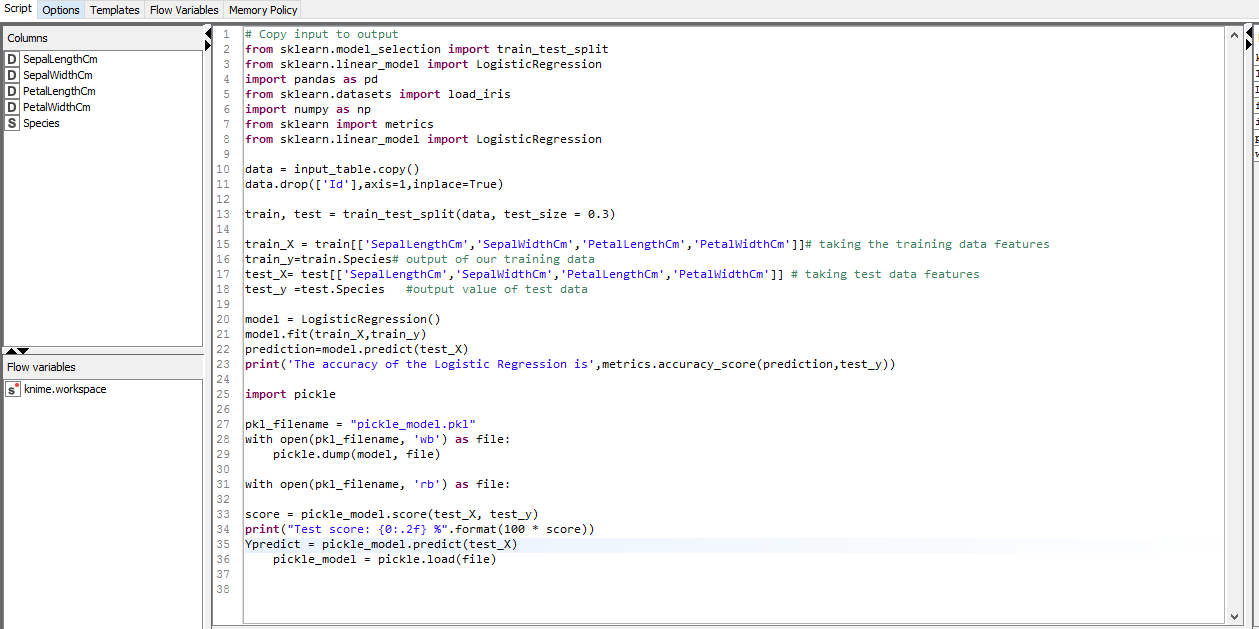
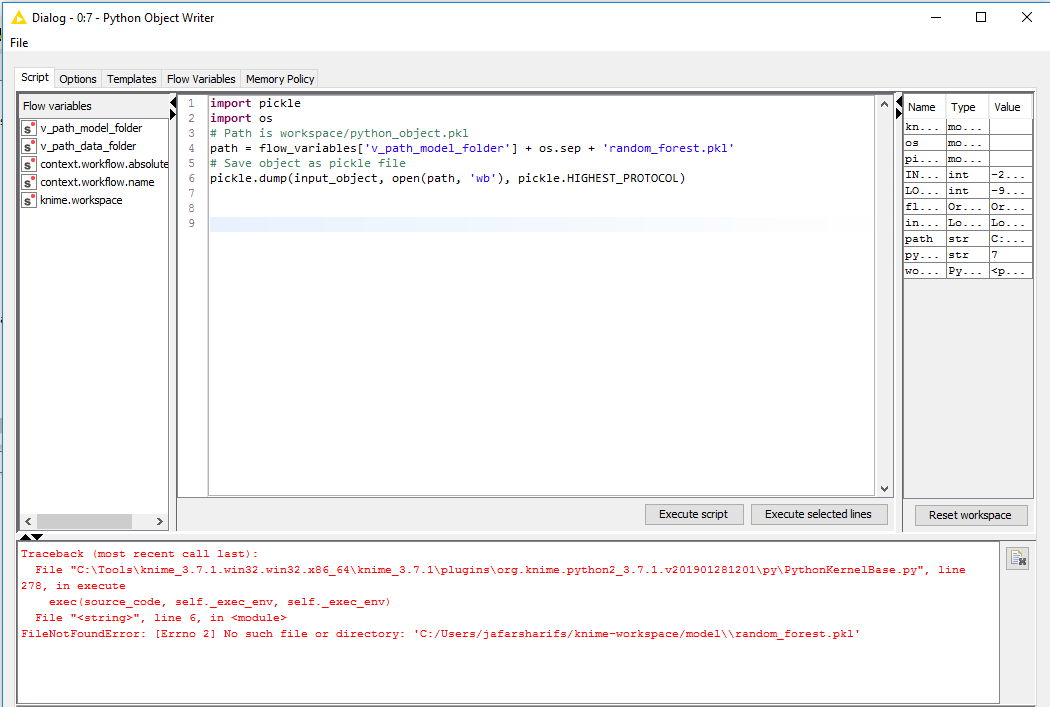
I am attaching the my ipub notebook and csv file used for it. I want to save that model as pickle and load the model and scoring on the test data with the help of nodes. please help with it. You can see entire code in the screen shot from model saving to model loading and let me know how to implement with the help of nodes… The data set is iris_data set.
Hi ,
I am taking your workflow as example and i am building my workflow i am facing below error in my example. how to share the workflow and dataset?? so that i can share it.
The dataset i used it iris dataset. Please let me know the changes to be done to make it work and also is it important to use extract context properties and java edit variable nodes??.. i was getting path error when saving and loading the pickle file
Does the “model” directory at “C:\Users\jafarsharifs\knime-workspace\model” exist? If not, you need to create it first as Python’s open(..) function does not do that automatically.
A few things. The paths seem to be different on MacOS and Windows so you end up with a path with / and \ which is not good (maybe the os.sep is not adequate). And your pickle files have different names (did not immediately spot that).
HI,
Thank you i have resolved it without using Extract context Properties. I have a question i am able to save the model as pickle.
Will knime support saving the model using pyspark…In case of pyspark model is saved as folder??
I want to implement models as branching one after the other one model output is input for other model Nothing but an hierarchial of models as shown in below figure.
3).Will python learner support sprak mlib libraries/pyspark models and can we execute pyspark models using python learner node?
Hi @jafarsharifs
I am not sure I get what you are trying to do, but let me try to answer your questions:
Will knime support saving the model using PySpark…In case of PySpark model is saved as folder??
I assume you are relating to a ml/mllib model that was created in a PySpark snippet node. Currently the PySpark nodes to not support the output of a model via a KNIME Port. But you can save the model in the HDFS of the Cluster. It is as easy as calling model.save(sc,“path in hdfs”). You are then able to load the same model in another snippet with ModelCLass.load(sc,“path in hdfs”).
Some models can also be saved as PMML PMML model export - RDD-based API - Spark 3.5.0 Documentation which could then be used in any KNIME node with PMML input.
I want to implement models as branching one after the other one model output is input for other model Nothing but an hierarchial of models as shown in below figure.
My first idea, here would be to use three spark rowfilters, that filter the needed rows after the first model and then use it in the corresponding PySpark snippet.
Will python learner support sprak mlib libraries/pyspark models and can we execute PySpark models using python learner node?
I am afraid I do not understand what you want to do here. My best guess is that you would like to PySpark within the normal Python node and then have a pickled object of the ml/mllib model? What is the use case for this?
Hi Jafar,
sorry for the late reply I did not noticed your replied.
Here is a Workflow that saves and loads a model in PySpark in this case in a local Big Data environment.
You might have to change the path in the save and load nodes to fit your system. The path is the path in HDFS, for local Big Data this is your local Filesystem which might not have a “/tmp” folder.
can a model be converted in pickle format only if it is written in python learner node? which means we have to manually code entire model in python learner node?