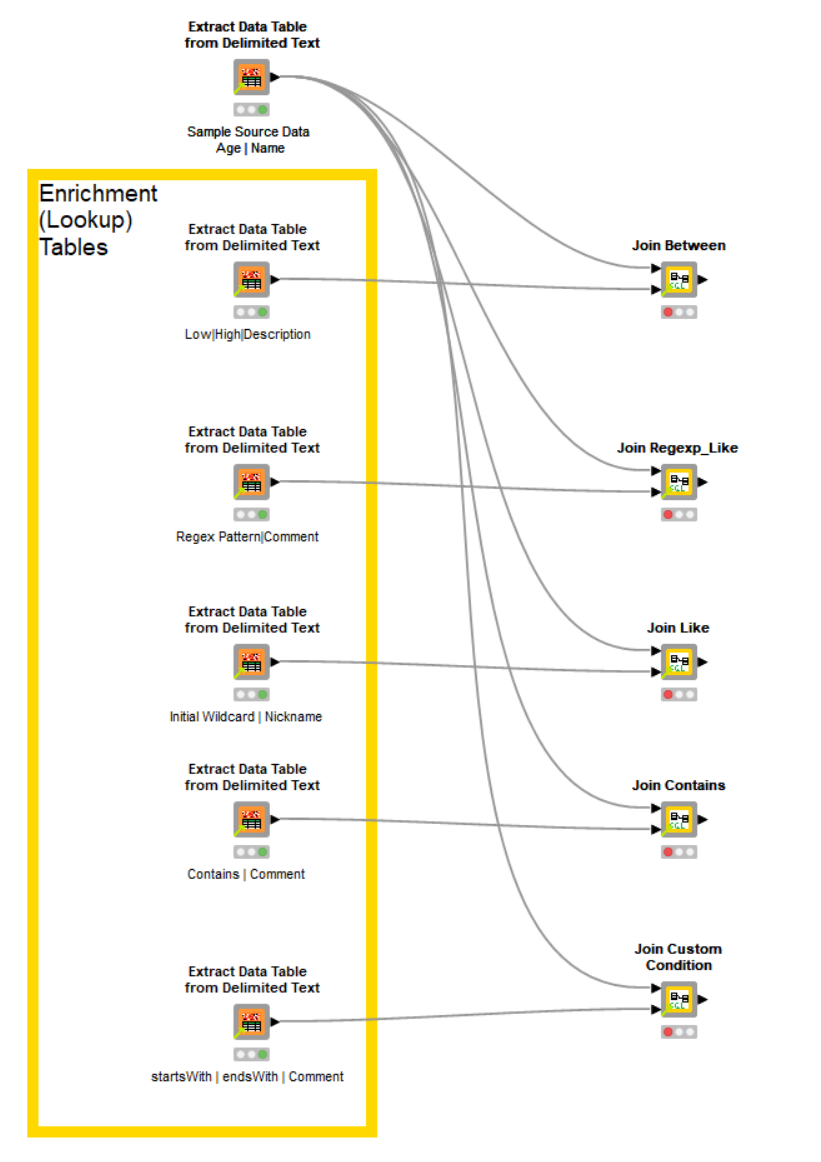
Workflow demonstrating the use of the Joiner Components The joiners provide the following functionality:
This is a companion discussion topic for the original entry at https://kni.me/w/4_eVfOR3f-EMpo2s
Workflow demonstrating the use of the Joiner Components The joiners provide the following functionality:
Something that comes up from time to time on the forum is the ability to provide joins between tables where the join isn’t an exact match. For example, the ability to join one table to another based on a date range, wild cards or regular expressions.
There are a couple of general ways of achieving the required results.
One is to use a cross joiner to match all rows with all other rows, and then use a Rule Engine to see which rows actually meet the required condition, and then applying a row filter to keep only those selected by the Rule Engine.
A second option is to make use of a database, such as H2, to temporarily store the contents of both tables, and then make use of the SQL features to perform the query and return the required joined results.
I have previously written a component using python (my PandaSql Join) component which uses python to join two input tables using PandaSql and return the result, which is similar to the H2 option but requires Python to be present and installed.
The trouble with the Cross Joiner method is that for large tables it can result in an excessively large intermediate step (the product of the rows of both tables when all joined with each other).
The trouble with the database method is that it requires the user to spend time adding a load of additional nodes to the workflow, and know some basic sql syntax to achieve the desired result. Possibly their whole reason for using KNIME is to avoid understanding SQL!!
I decided though that this comes up sufficiently often that a component solution was in order, so I have created several “joiner” components which make use of the inbuilt H2 database to facilitate joining using SQL but (mostly) not require SQL Knowledge, and not requiring the manual and laborious addition of multiple nodes to the workflow.
They each do what they say on the tin.
The joiners provide the following functionality:
Join Between: source column BETWEEN values in two lookup columns
Join Like: source column LIKE a wildcard pattern in a lookup column
Join Contains: source column CONTAINS a value in a lookup column (lookup is substring of source)
Join Regexp_Like: source column matches a regular expression pattern in a lookup column
Join Custom Condition: write a sql where clause to join two tables. This is useful for more complex/multiple conditions but this one does require basic sql syntax knowledge, but is good when you cannot achieve the result easily using the other methods.
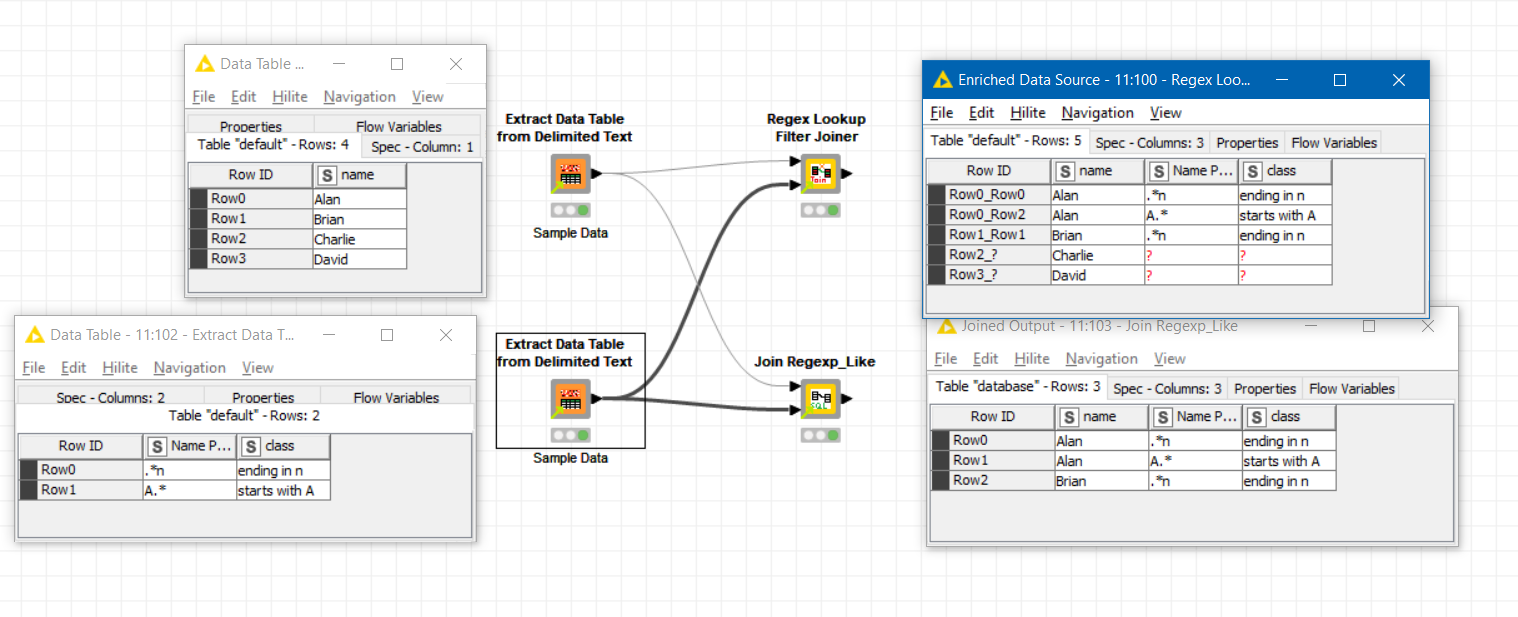
EXAMPLE - JOIN BETWEEN
Source Data
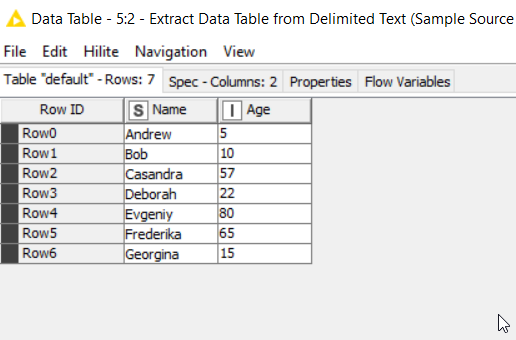
Enrichment / Lookup Data
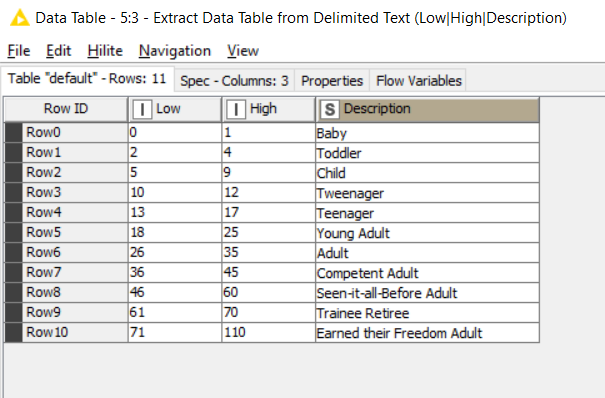
Join Between
Result
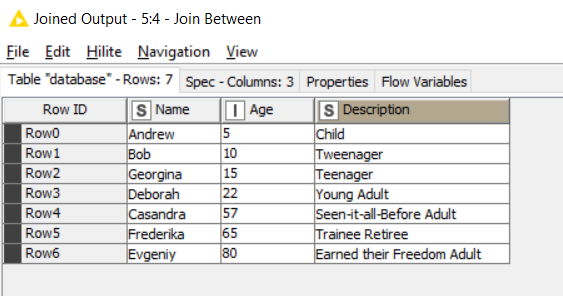
Have a good weekend one and all! ![]()
Hi @takbb
Impressive and very useful collection of joiner nodes. Thanks a lot for such a great contribution and work ![]()
![]() !
!
Cheers
Ael
Thanks @jarviscampbell
I’ve now added a new “joiner” to the mix. It is another regex joiner, but unlike the other joiners here, it returns the JOIN and LEFT OUTER JOIN of the two tables. See screenshot that shows the difference in the return
The other thing about this “Regex Lookup Filter Joiner” is that it doesn’t make use of a database, and nor does it ever cross-join every row of the two tables. Instead it uses a loop to do a single pass through the “lookup” table, and uses a row filter on the main table to find the joins which are then collected as a single result set and returned, along with LEFT table rows that didn’t match.
This provides I think a balance between performance and memory usage since its memory use will be nothing like that of the Cross Joiner solution with large tables, and also doesn’t require the loading of all data into an H2 database table. The use of a loop will slow things down for very large lookup tables, but should be reasonable for smaller lookup tables (and by their nature, lookup tables are generally small).
I’ve added it into the demo workflow mentioned previously.
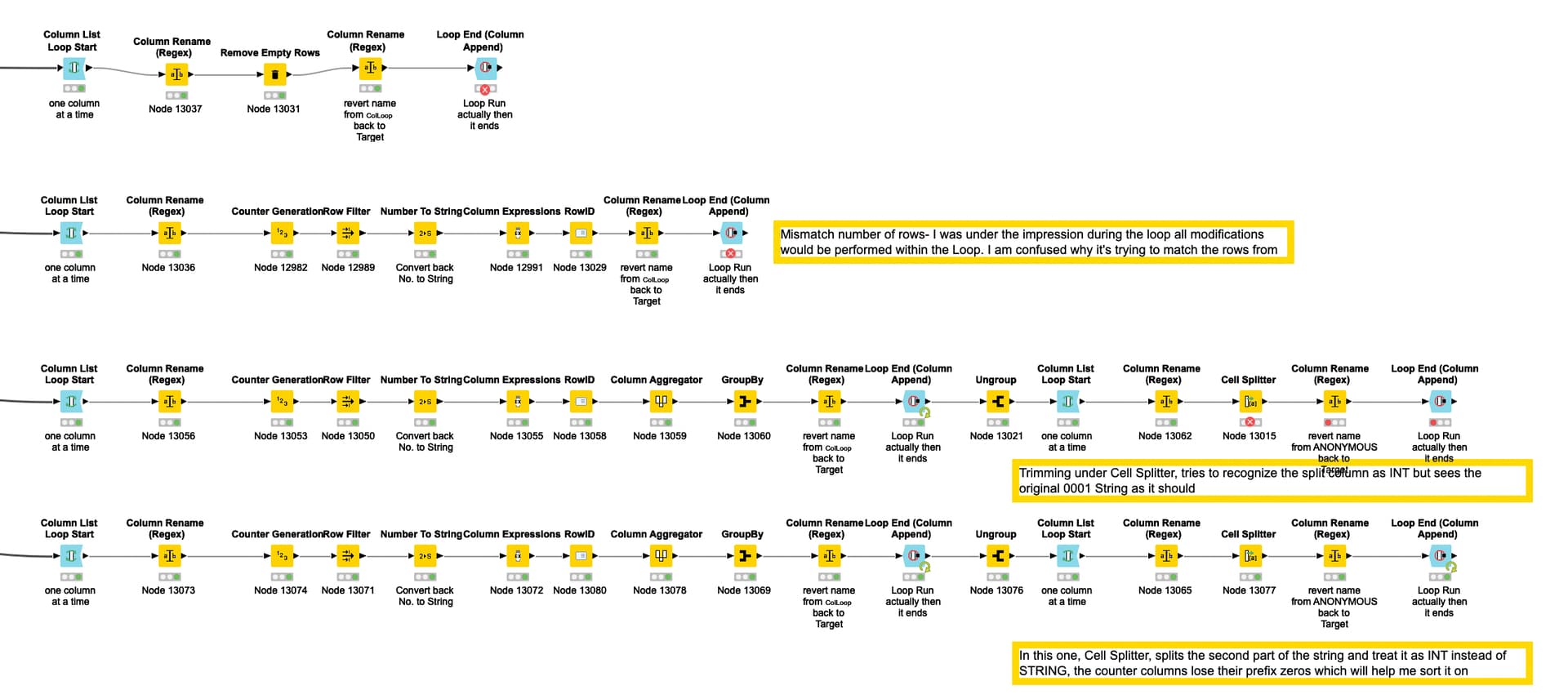
Hi @takbb, before you’ve created these cool Lookup Filter Joiners, I was fiddling around w some nodes and hit a few snags on the way, could you tell me in each one of them why it didn’t work? I was trying to simply re-create the ‘delete shift cell up’ in Excel function.
excel delete shift cel up.knwf (700.2 KB)
Also @takbb it seems to me to that the ‘Regex Lookup Filter Joiner’ still returns the missing cells, while the ‘Join Regexp_Like’ doesn’t. Is that the case? If so, the Joiner would be better because it doesn’t make use of the online DB, which is great btw, is that the case?
Second question is. On this workflow, you have gone from a 15 node workflow to a 20 node workflow and getting the same output, is that correct?
How could the new Node ‘Regex Lookup Filter Joiner’ benefit more than the older ‘Join Regexp_Like’ in that same workflow model? Thanks.
Hi @jarviscampbell , ah so you are trying to remove the empty cells in each column? ![]()
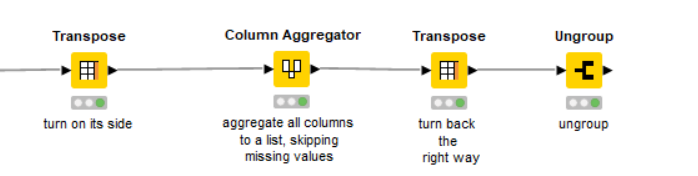
ok, so in the column append loops, the row count for all columns appended at the end of the loop must be the same, so removing say 5 rows from 1 column and 3 from another isn’t going to work.
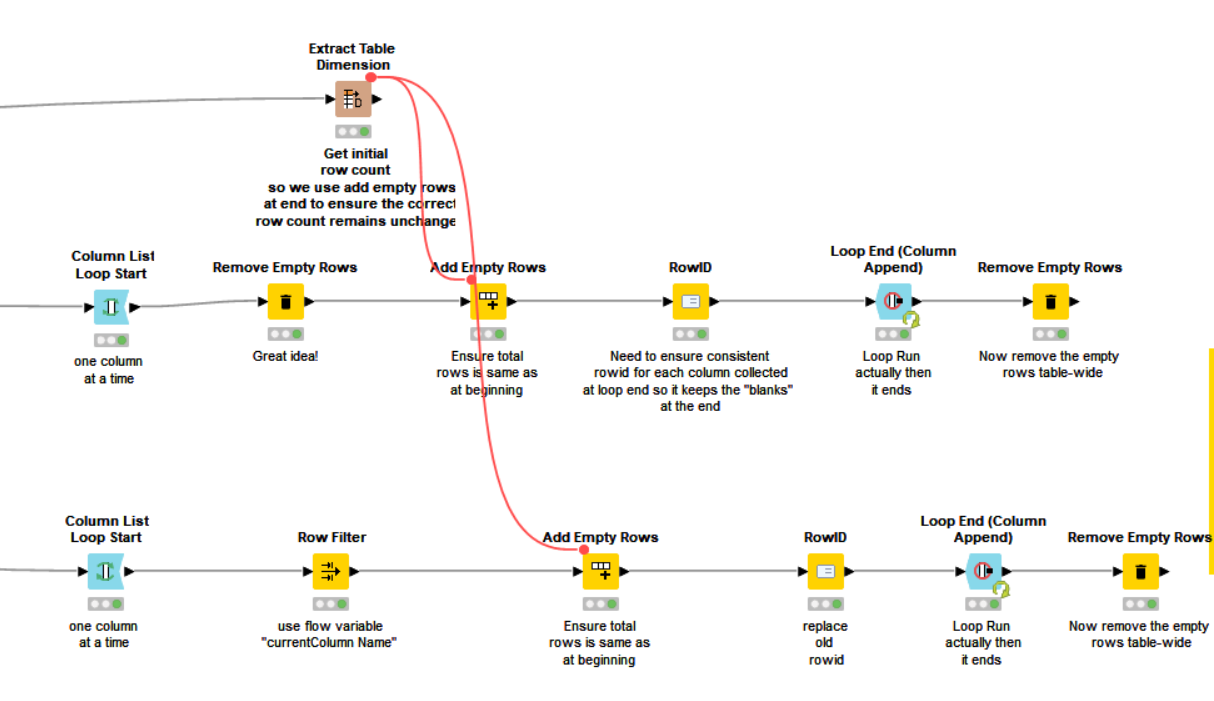
However, what you can do is prior to the loop start, use “extract table dimensions” to give you a flow variable “Number Rows” which will be the total rows for the table. If during the loop, immediately after removing the unwanted rows you add the required number back using “Add Empty Rows”, it will be happy but make sure you give each column the same set of ROWIDS so that it matches the rows in the correct sequence across all columns. Yes there is method in the madness of deleting empty rows, and then adding them. The added ones go on the end. After the loop, remove all the empty rows for the entire table and you have what you want, I think
There is a shorter way, still involving a loop:
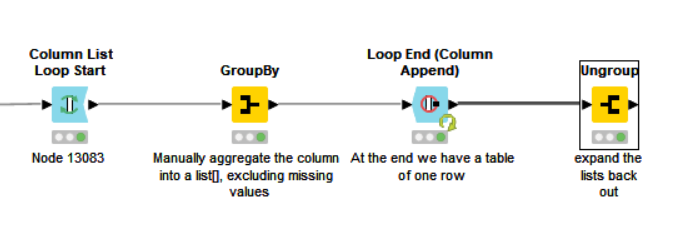
[Edit] And I just thought of a method with the same length, but without a loop:
I’m sorry but I haven’t been through your remaining loops to see where they go wrong. I got a bit lost with what you were doing with these but that’s probably as it’s getting late here now. Anyway hopefully the above gives you some ideas.
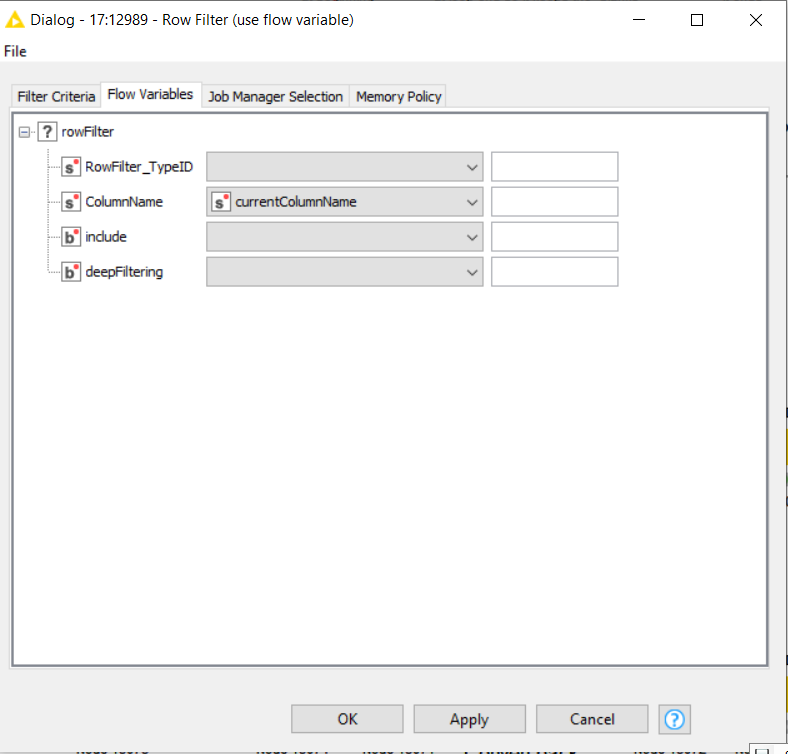
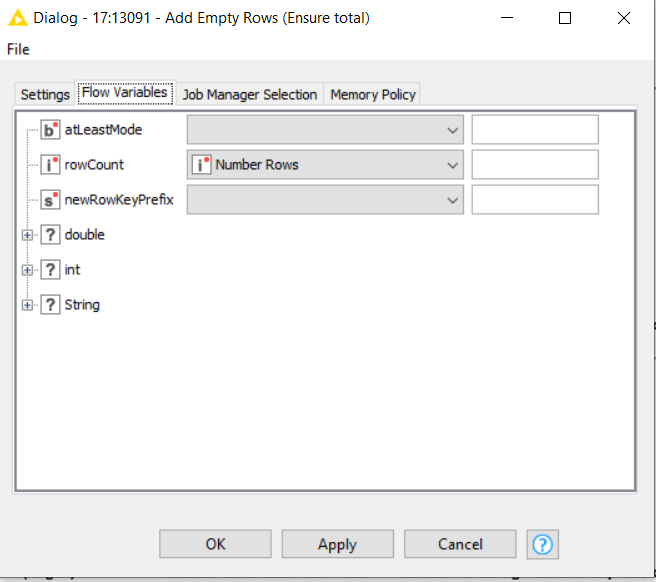
Oh, and one thing to note - you can avoid the column renaming that you were doing. Just use a flow variable called “currentColumName” that the column list loop generates (look at the flow variables tab), and with RowId there wasn’t a need to use a Counter Generation, although I guess you may have had a reason for doing it that way.
e.g. on your Row Filter:
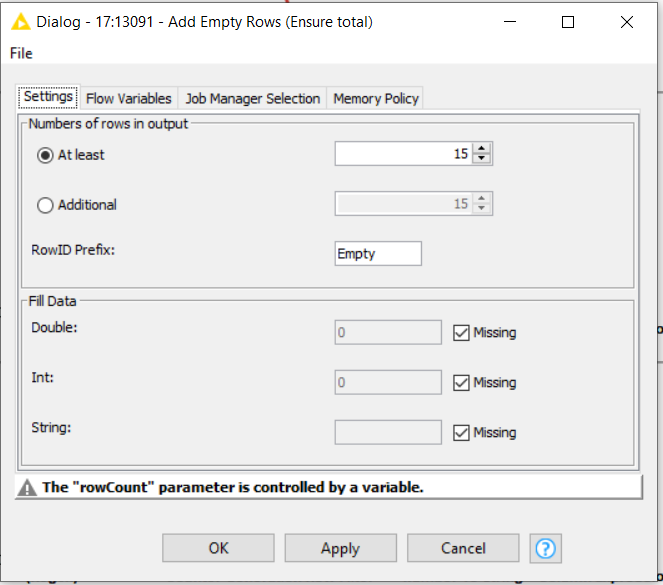
and on the Add Empty Rows node, to ensure that the column ends up withthe required number of rows:
forum- excel delete shift cel up -modified.knwf (295.3 KB)
I hope that’s of help.
[quote=“jarviscampbell, post:8, topic:48880”]
it seems to me to that the ‘Regex Lookup Filter Joiner’ still returns the missing cells, while the ‘Join Regexp_Like’ doesn’t. Is that the case? If so, the Joiner would be better because it doesn’t make use of the online DB, which is great btw, is that the case?
So many questions… so little time … ![]()
Yes the ‘Regex Lookup Filter Joiner’ returns all rows from the main (top) table and tries to return a match with the lower table if it can find it. If it finds more than one match in the lower table, it will return the row from the top table more than once (in this last bit the Join Regexp_Like behaves the same). As you say, it means it returns “missing” rows (unmatched rows). I might in future make that an option on all these join components (i.e. whether to return the LEFT OUTER JOIN which is what these “unmatched” rows are).
It’s possible that the Regex Lookup Filter Joiner could be worked into the workflow and be an improvement overall, but there would need to be a few changes simply because it returns the rows that the workflow is already coded to pull in, in a different way. Personally, for your data I would stick with what you have that works. I might have a play though and see if there are advantages. If I see any I’ll let you know. By all means give it a try though. I often try things on a “duplicate branch” while working on something, just so I can check if the end result is the same.
Yes the number of nodes increased, I haven’t counted them. I believe the data set remained but the additional nodes were there to condense the number of columns from the original solution (I think). Possibly the number of nodes could be reduced by modifying an earlier part of the flow, but as we already had a working output at that point I decided to transform it from there rather than rewriting the previous part.
I’m not totally sure it will benefit it. As I said, I’d be inclined to stick with the one that works. I did this new “Filter Joiner” component because I wanted to find a way that didn’t involve huge cross joins or use of the H2 database, because both of those things have impacts. This joiner will have different impacts under some circumstances but it just gives another option and I don’t think any one of the methods is always the best.
Some of my answers are a little vague but without spending time trying things out, it isn’t always clear which way the answer will ultimately go.
Hi @takbb Thanks for the effort. Sorry been out for work last week.
I confirmed that it works in all ways offered. I appreciate that along w all the explanations behind it.
Thanks again.
Hey @takbb
I am trying to dig into your “Join Custom Condition” component, but I don’t have an SQL background. Can you give me an example of the syntax that I would use to add some standard column = column style join conditions to your custom join in your sample? Do I need to use parenthesis to group clauses?
t1.“Name” like t2.“startsWith” ||‘%’ or t1.“Name” like ‘%’|| t2.“endsWith”
Nevermind. I was able to pickup the syntax to do some highly complex joins. What an amazing tool! The expanded conditional capabilities of your DB to memory join approach has been an eye opener! It was the breakthrough that I needed for the forensic accounting audit that I am working on.
Thanks as always for sharing such awesome solutions @takbb
Hi @iCFO , thanks for the kind words. Apologies for not responding to your previous question but I’ve been away and as a result had loads on with work so hadn’t ventured onto the forum. I’m glad you managed to find what you needed, but if you need any assistance I’ll do my best to answer.