Hi @jarviscampbell ,
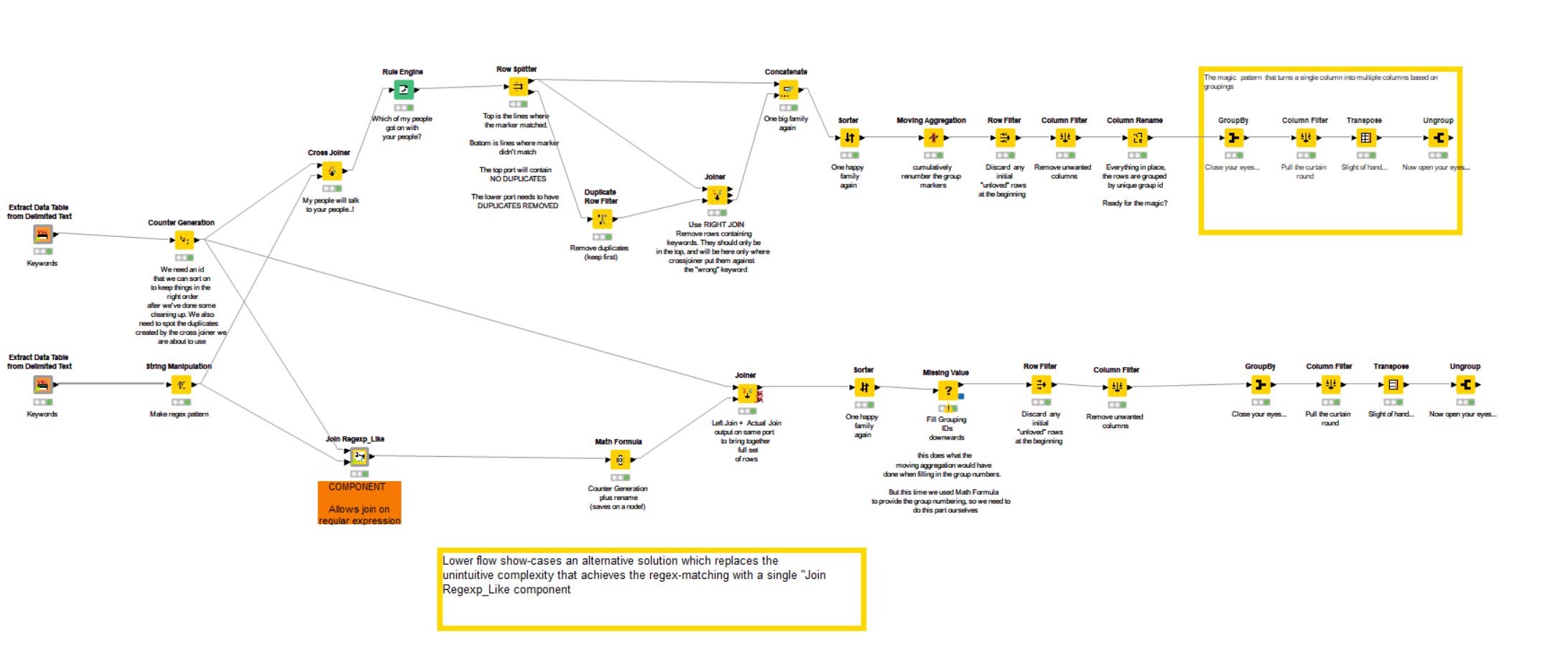
I thought I’d take this opportunity to show-case a new component of mine. One of the less intuitive aspects of the solution for this workflow is the mechanism to join using regex patterns. The standard KNIME joiner nodes do not provide a facility for non-equi-joins (e.g. wildcards, regular expressions and ranges).
After assisting with your workflow, I decided to create a set of components which use the built-in H2 database behind the scenes to help bridge this gap.
The attached shows how the Join Regexp_Like component can simplify that part of the workflow, making it more readable and intuitive.
I have left the old mechanism at the top, and added the new variation at the bottom
GroupBy-alternative with regex join component.knwf (165.1 KB)
There are some other minor changes as a result but hopefully you may find such a component useful in future. You can see the full set in my other post on the subject: