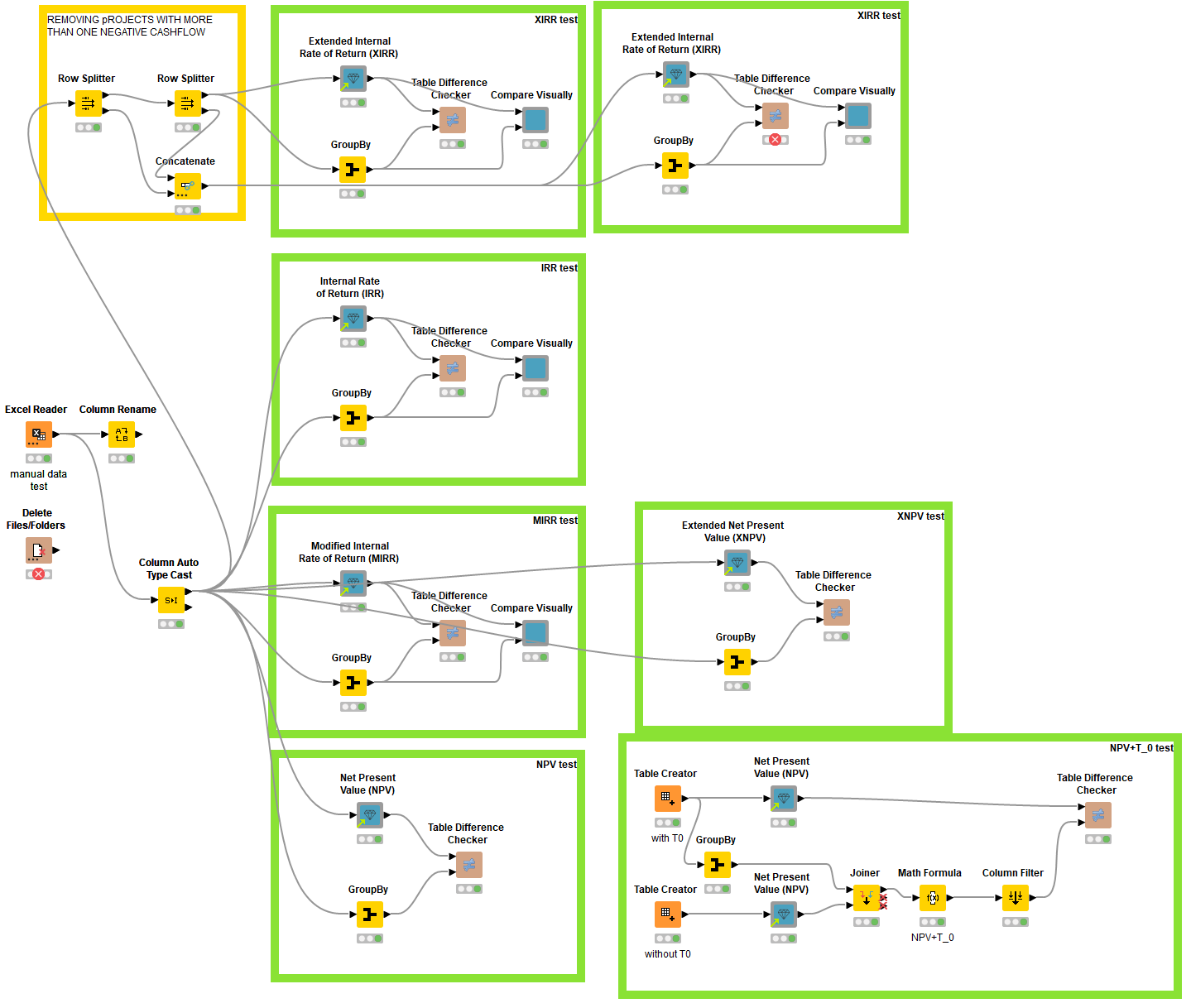
First off, thank you Christian Rastasanu and Paolo Tamagnini (@paolotamag and whoever else involved) in the creation of the Financial Calculation verified components and its training materials.
Use Case:
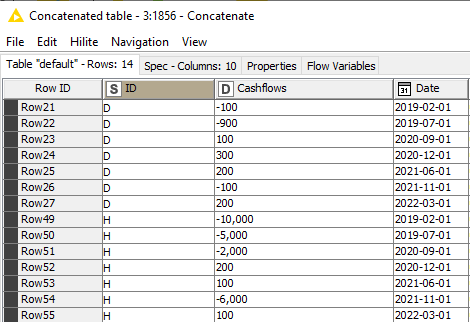
I have a set of “scenarios” for which I have cash flow records I generated myself as a control group for testing of my workflow. Therefore, I know the interest rate I used to generate them, along with other important factors such as compounding period.
Example Scenario:
- $100k investment/60 equal monthly payments in arrears/interest rate of 8%
- Day count convention is 30/360 – leading to 12 compounding periods a year.
- Resulting payment amount is $2027.64 due the same day of the month, every month.
Issue:
I have tried the XIRR node. The speed is amazing. My baseline group using “Parameter Optimization Nodes” took 3 minutes, and my baseline group using XIRR was done in less than 5 seconds. However, I am unable to produce the same results. I get 8.3% IRR (instead of 8%). I am not able to recreate this result through other calculation methods.
I have tried to research the calculation in the “Java Snippet – XIRR(de campo)”. However I am not a developer and I don’t understand java or how to navigate it in GitHub. Can someone help me either speed up my “Parameter Optimization” loop, or understand why the XIRR is not producing my desired results?
Desired IRR method
I am calculating the IRR in accordance with “Appendix J” of the “Truth in Lending Act”. It is your standard textbook IRR formula which considers compound periods, and partial periods as well. At the moment I am only interest in monthly compounding, but will soon neither other frequencies.
I have used the goal seek function of excel to validate the reverse calculation (meaning, I have used the cash flows and their characteristics such as compounding period with the formula mentioned above to solve for IRR), and have achieved the desired results.
I have used Ivory’s “Supertrump” (an industry leader in pricing applications for equipment finance), and validated the results as well.
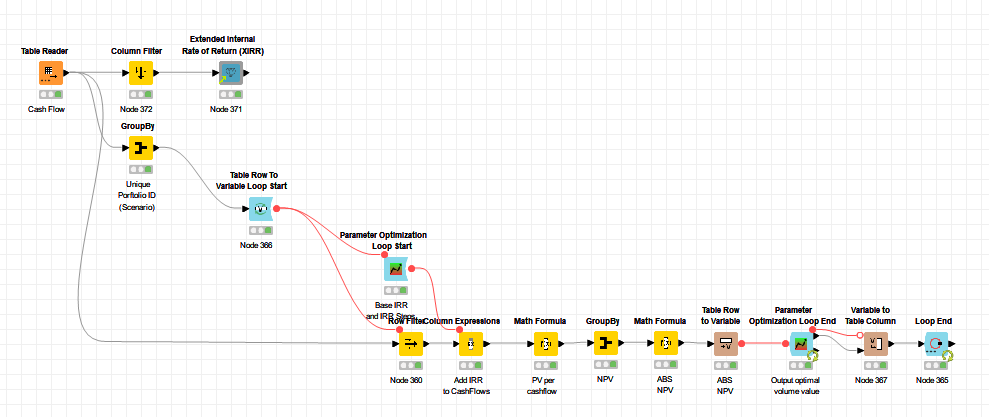
I have recreated the goal seek function of excel in KNIME using “Parameter Optimization Nodes”. Here I also get the desired results. My challenge here is the speed. I have 100k scenarios, each with up to 120 cash flows for which I want to solve IRR. Right now it is taking me about 30 seconds per scenario.
My desired outcome would be able to pass additional cash flow parameters (see appendix J, section 8) into an XIRR like node and obtain the IRR with the same speed as the XIRR node does now. The node would have defaults to choose from if certain parameters were not supplied. With recent federal and state regulations requiring more and more companies to adhere to the “Truth in Lending Act”, this would become a very popular node.

KNIME_IRR.knwf (414.7 KB)
IRR.xlsx (27.8 KB)
For reference:
NPV Formula for which to solve IRR
Appendix J - NPV Formula Definition
Parameter Optimization Loop:
KNIME - Parameter Optimization Loop
Financial Calculations in KNIME: