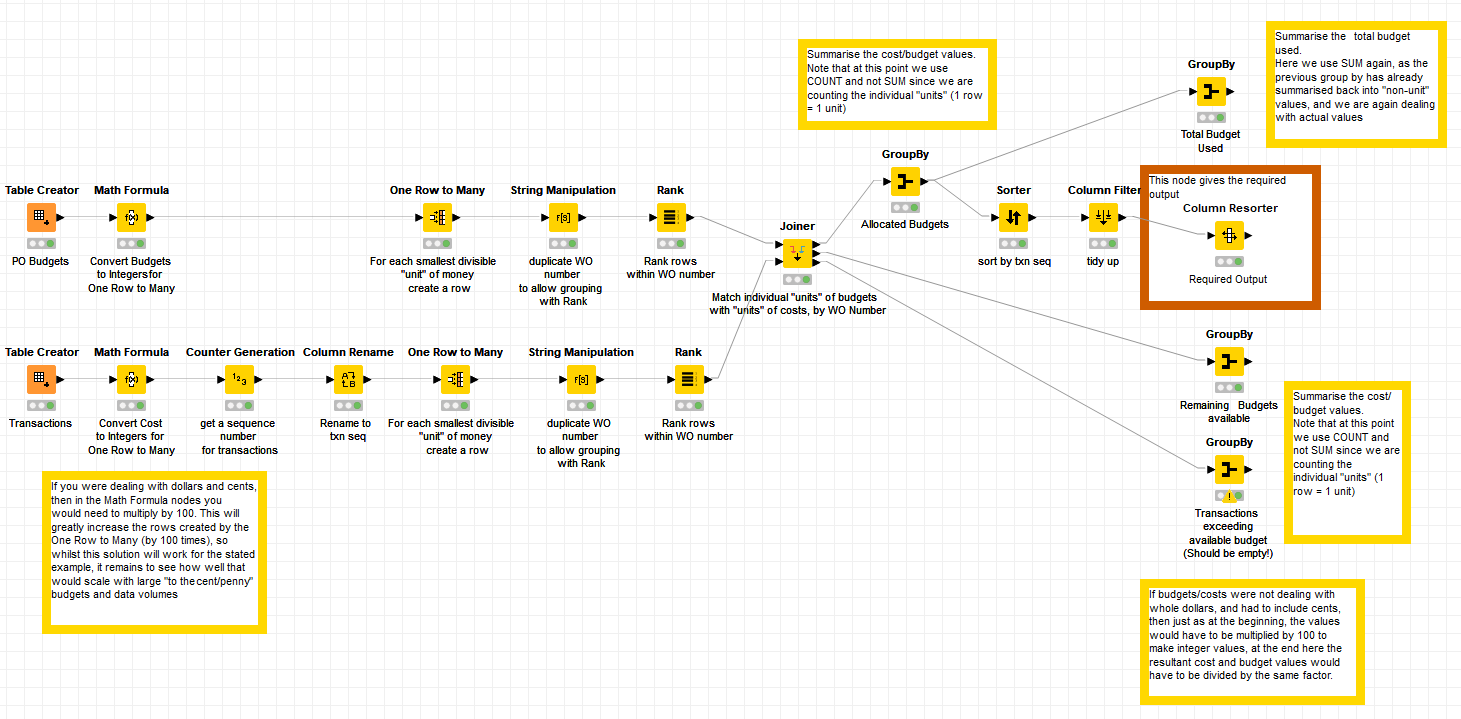
I wasn’t particularly happy with the solution above because whilst it works, it really would use large amount of resources if you had very large budgets to allocate, and it would be disappointing if I didn’t at least try to offer a “simpler” programming solution too.
As a result, I’ve fallen on my old friend the java snippet node, using my “favourite” technique where it can remember cumulative information as it proceeds down the rows from top to bottom.
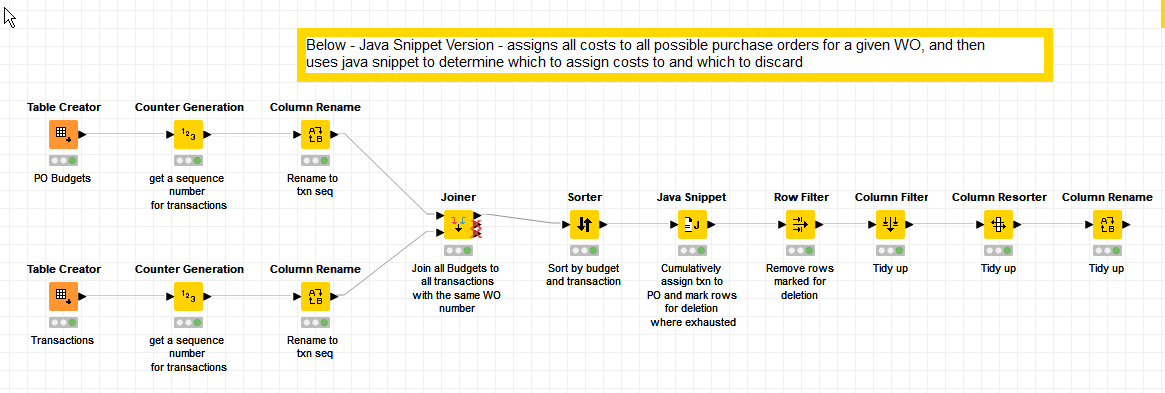
So a combination of KNIME standard nodes to do the grunt work, and then a java snippet to provide the refinement and rules, resulted in the following workflow which I have attached along with the original workflow
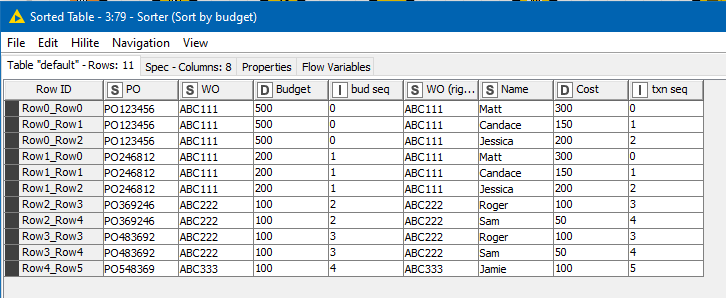
Here, the joiner brings together all cost rows and joins them with all possible purchase orders for the required WO, and this is then sorted in PO and transaction sequence order, resulting in the following table of “possibilities” that need to be processed
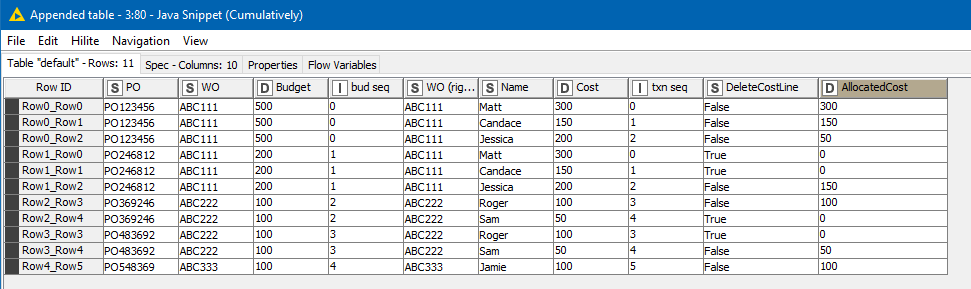
A java snippet is then used to run down the list, keeping track of PO and WO budgets, along with the amount “remaining” on each transaction as it is processed. Where a PO runs out of money, or the cost of a transaction becomes fully allocated, rows are marked for deletion.
(Note that it doesn’t actually do anything with the tracked “WO” budgets, although it keeps a track of them, and it wouldn’t generate any errors if a transaction is not fully covered by the available POs. That eventuality could be a potential improvement, or you can use simple aggregations to find if this ever occurs, but this workflow assumes that all transactions have sufficient budgets!)
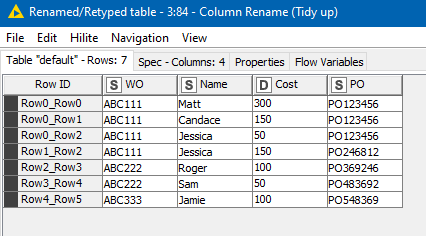
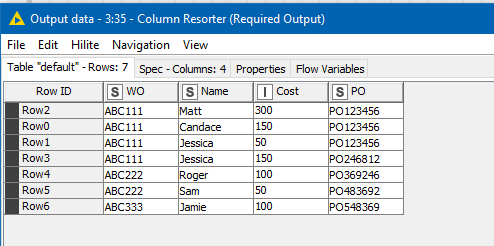
The required deletion then occurs, and following some tidy up of column names and ordering, the result is returned:
As this is not a “brute force” solution like the previous offering, this should scale happily with budgets and costs of any size, but of course it should undergo additional testing, as it contains hand-coded script and therefore has plenty of scope for the introduction of bugs.
Allocate txn to budget 2.knwf (72.9 KB)

 , and by the time I’d reboot, + did not save the workflow (I know, one of the most amateur move
, and by the time I’d reboot, + did not save the workflow (I know, one of the most amateur move  ), I went to sleep instead.
), I went to sleep instead.
 The stumbling block I had was the iterative nature of breaking up an individual cost across the different budget lines. It was “kind of” ok (though I never found a solution) if the cost as in the “Jessica” example had to split on two budget lines, but then what happens if we then find it needs to be split across three, or four… or… and that’s when I finally ditched that approach in favour of the first flow. (I couldn’t propertly make it work in the simple case and I had no idea how to make it work in the complex case).
The stumbling block I had was the iterative nature of breaking up an individual cost across the different budget lines. It was “kind of” ok (though I never found a solution) if the cost as in the “Jessica” example had to split on two budget lines, but then what happens if we then find it needs to be split across three, or four… or… and that’s when I finally ditched that approach in favour of the first flow. (I couldn’t propertly make it work in the simple case and I had no idea how to make it work in the complex case).