Hi @chiashin ,
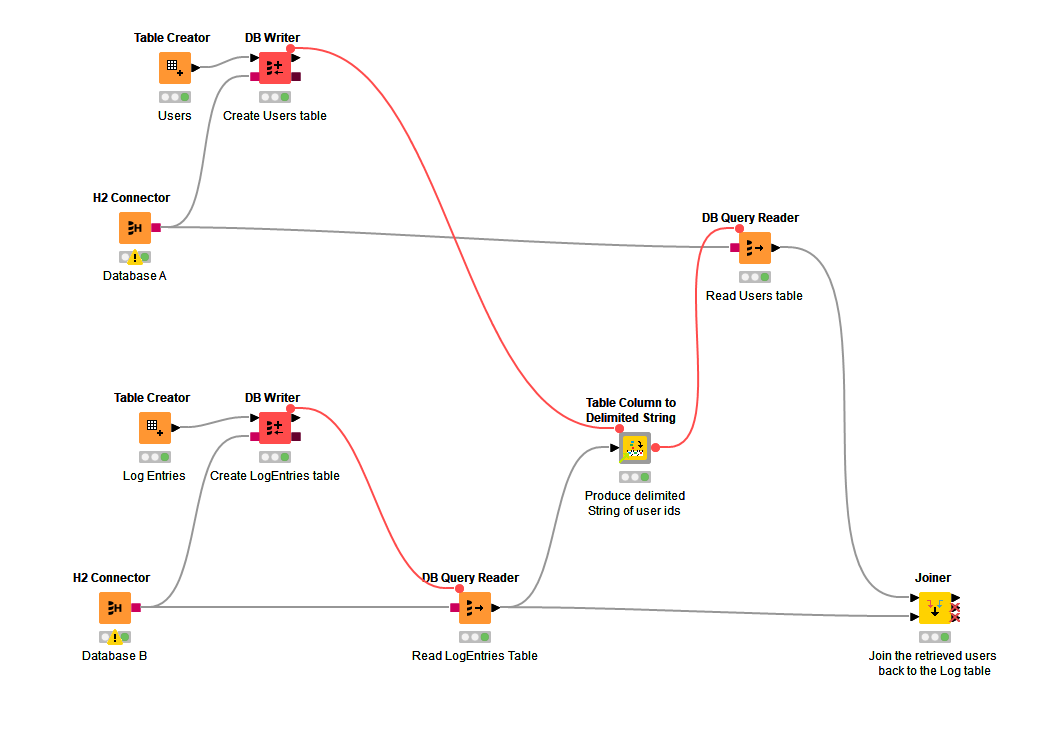
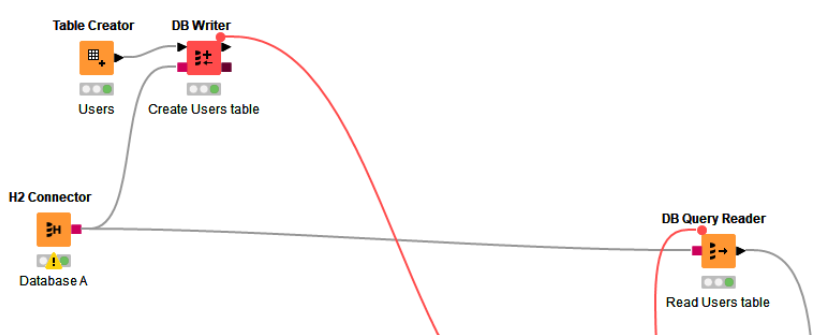
In the example, the DB Writers are only there to populate a sample in-memory database and provide some sample data, so apologies if they are causing some confusion. The purpose of the red flow variable lines between the DB Writers to the subsequent nodes are there purely to enforce the correct sequence of processing so that the demo works (They ensure that the sample data has been written to the tables before attempting to query the data using the DB Query Readers).
In place of the H2 Connectors, you have a DB connector to your two databases and the DB Writers would not exist, as your tables are already populated in the database.
I used DB Query Readers containing specific queries so that at no time does it pull back ALL the data from any table, but instead only pull back the data selected by the queries.
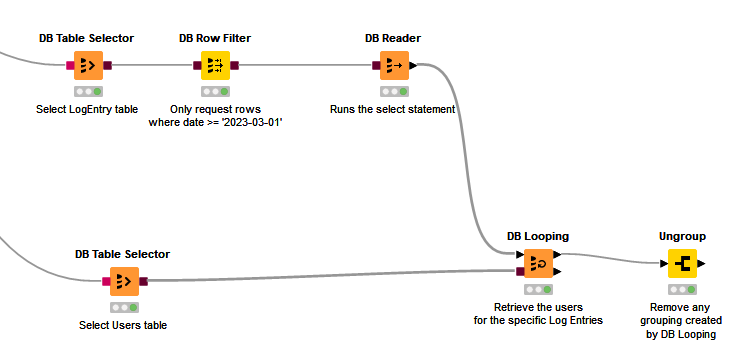
OK, so let’s look at how this would work with (Connector) → (DB Table Selector) → (DB Reader)
The DB Table Selector works collaboratively with other “in database” db nodes (those with the brown square connectors) to filter the data being returned. The data is only returned to KNIME when you use the DB Reader which has the black triangular output.
If your DB Table Selector is configured to reference a specific table (not a custom query), and is then attached directly to a DB Reader, it will return ALL rows from your table to KNIME, which is clearly what you are trying to avoid.
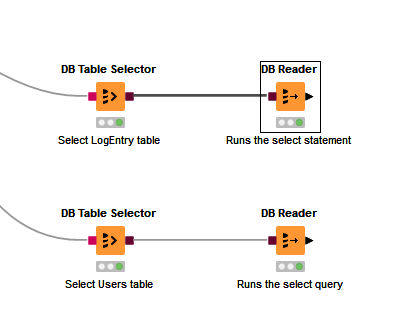
This configuration simply returns all rows from both tables
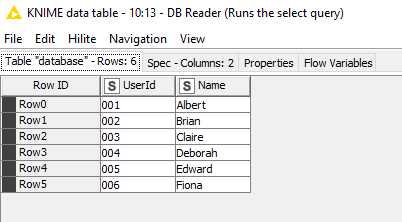
So what do you do to filter the rows being returned?
What you can do though is place other “in database” connectors between the DB Table Selector and the DB Reader to modify the query that will be executed by the DB Reader. (It is the execution of the DB Reader that actually runs the query against the database)
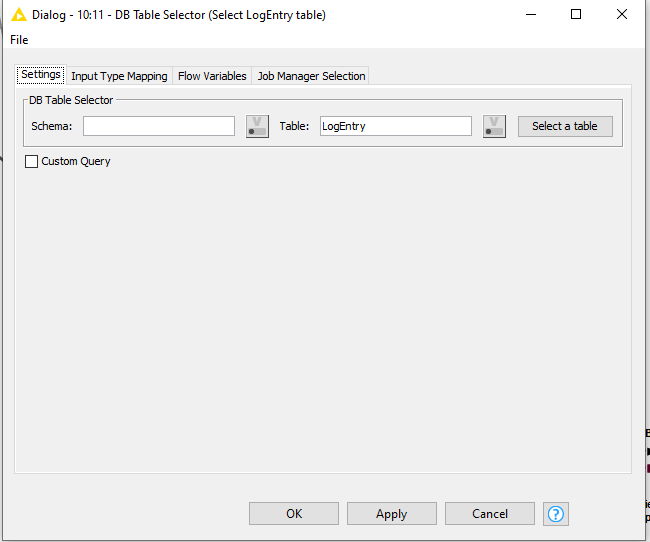
I don’t know how you are choosing your data from your first table, but in this demo, the LogEntry table is a table consisting of 6 rows, but we could imagine it being 6 million rows. I want to return Log Entries that are on or after 1 March 2023. In my original demo, the DB Query Reader was used to simulate this, and it was given a sql select statement
select * from "LogEntry" where "Date" >= '2023-03-01'
Now, this could be replicated directly in the DB Table selector, by re-configuring it and providing this as a custom query, instead of simply telling it a table name, but we can also do this by including a DB Row Filter
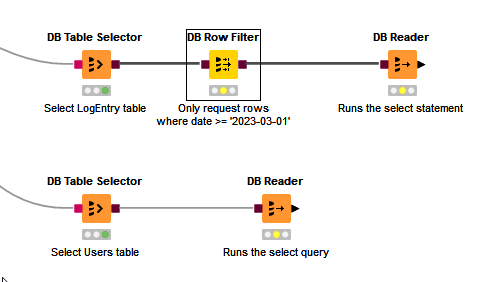
The DB Row Filter doesn’t actual select any rows, and when it is executed, no data is returned to KNIME. It’s purpose is to modify the query that will be executed by the DB Reader.
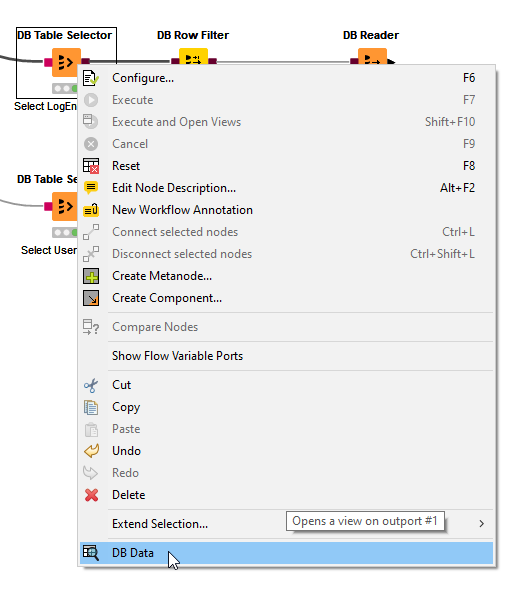
You can inspect what is happening. Open the output port on the DB Table Selector
And then click on the DB Query tab
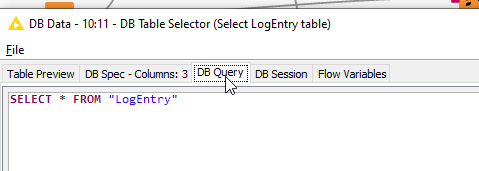
You will see the select statement that would be executed if a DB Query node is attached and executed.
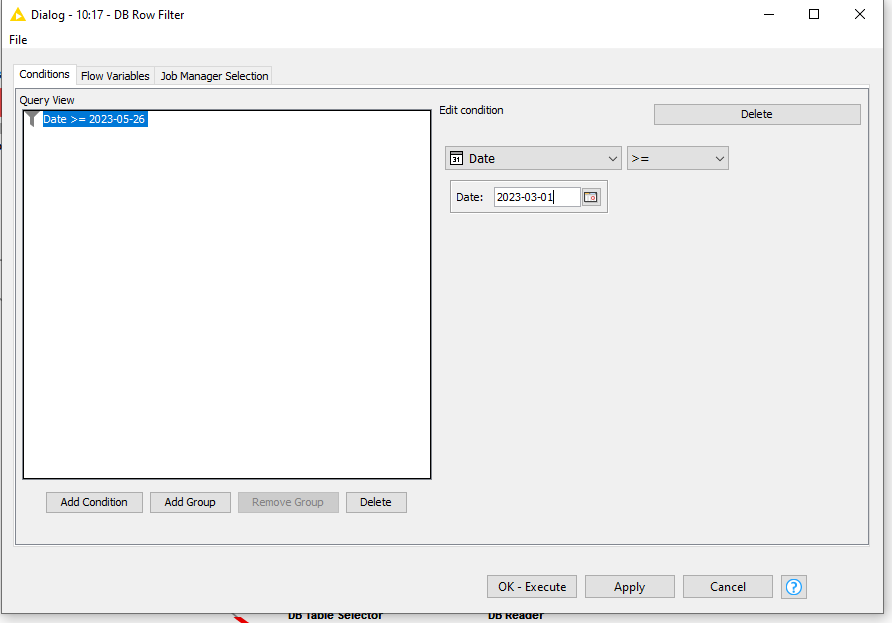
Now do the same on the DB Row Filter:
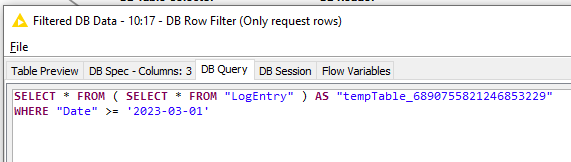
You can see that the query has been modified so that it contains a condition.
Whether that generated SQL statement is particularly efficient will probably depend on your particular database and one reason why I prefer to write custom queries instead… However, that discussion is not the purpose of this demo 
Note that at this point the query has still not been executed. The brown-square nodes are chained together and modify the query until such time as the DB Reader is executed. Only then is the data returned to KNIME.
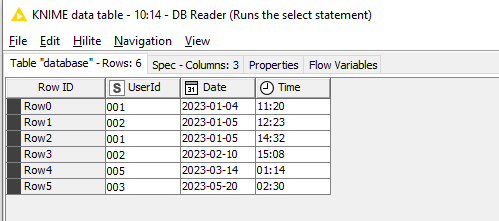
When the DB Reader is executed, the select statement returns these rows to KNIME:
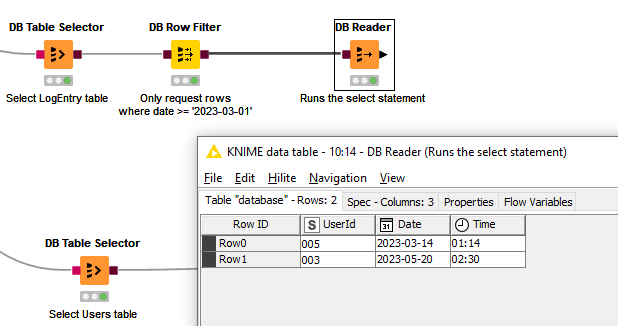
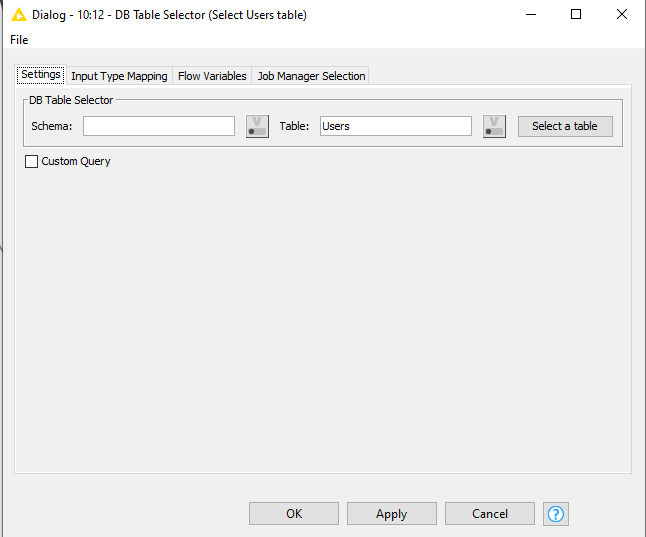
In this demo, I then want to find the Users for those particular Log Entries, and my Users table is (slightly weirdly maybe ) in a different database. So we want to select only those rows from Database B that apply to the specific users.
If we were writing the sql manually we would use
select * from "Users" where "UserId" in ('005','003')
The mechanism that KNIME provides for this is the DB Looping node (the node I forgot about when writing my initial response, but is actually perfectly suited for this job even though I’ve actually hardly ever used it)
Like the DB Reader, the DB Looping node also connects to a database using the brown connectors, and when executed, returns data to KNIME, but unlike the DB Reader node, it executes a specific SQL Select statement defined within its own configuration.
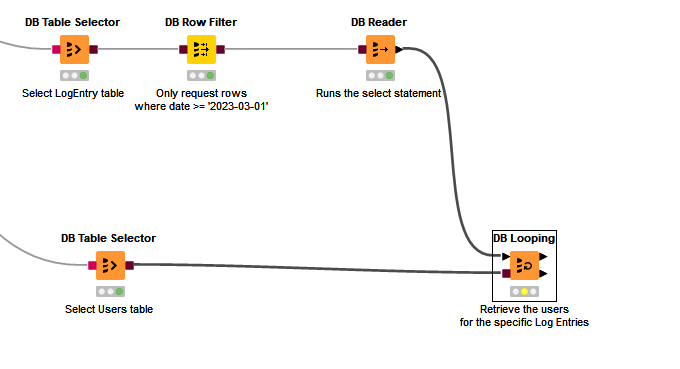
It takes an input data feed which can come from anywhere, but in this case will use the output of the “Log Entries” DB Reader.
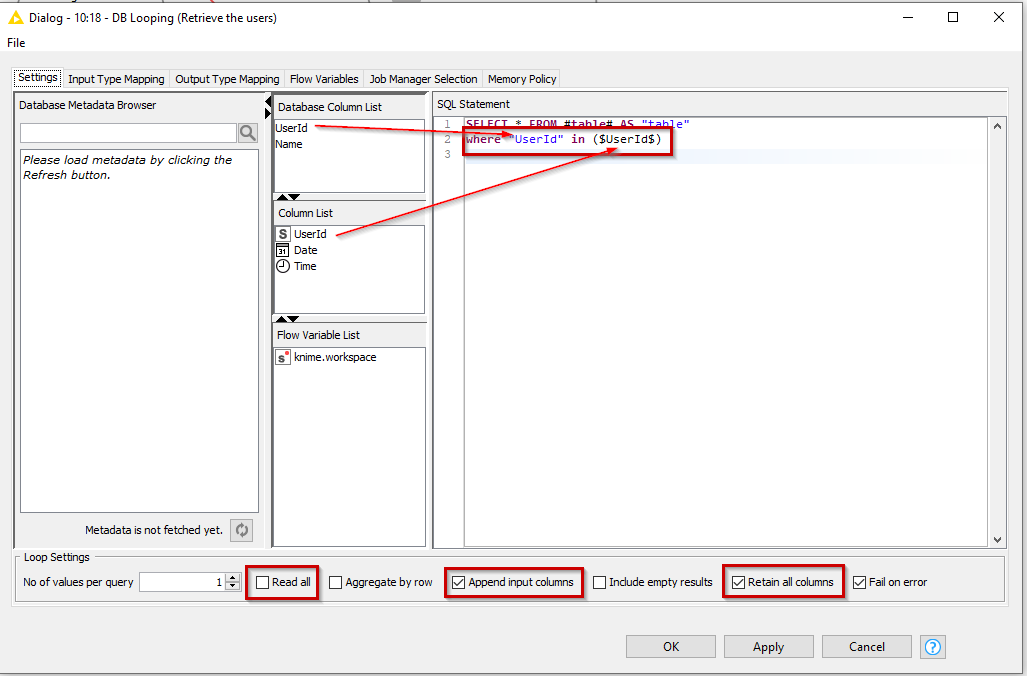
Within its configuration, you specify the select statement you wish to use, and modify it with the specific conditions, based on the incoming data port.
The upper panel “Database Column List” is the list of columns available on the database connection (i.e. the “Users” table in this case).
The centre panel “Column List” is the list of columns on the incoming data port.
So we modify the SQL Statement to include the condition as shown here which causes the DB Looping node to supply all the values of UserId which are on the incoming data feed, as a comma-delimited list which can be used inside the IN clause:
A couple of other things to note:
By ticking “Retain all columns” and “Append Input Columns”, the output will contain data from both the incoming data feed (the “LogEntry”), and the augmented data from the “Users” table.
In this case, you should Untick “Read All”, because otherwise you will find rows are matched incorrectly. I haven’t experimented to see under what circumstances “Read All” should be ticked or unticked. According to the help it is ticked to “Execute a single query with all values of the selected columns from the input table”. Anyway, for this demo, unticking it is the required option!
Additionally I’ve been lazy with using “Select *” whereas of course you may choose to select the specific columns to be returned.
The result was this data table, where you can see the effect of the DB Looping node was to generate “collection” elements.
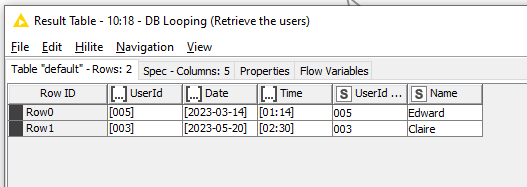
These can be resolved by adding an Ungroup node
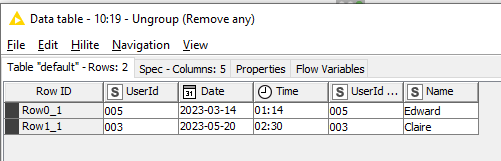
Attached is an updated version of the previous workflow with this example. When you look at the workflow, ignore the red flow variables attached to the DB Table Selector nodes. (I left them out of the above pictures as they aren’t relevant.) As mentioned before, the red flows are purely to make the demo work, as it has to pre-populate some database tables before it can then query them, and they serve here purely to ensure the correct order of execution of the nodes.
Querying database based on values from another database v2.knwf (64.0 KB)
I hope that helps.