hello everyone,
I would like to create a sales forecast for a number of different drugs and have plenty of data to do so. My plan was to create a linear regression model. However, since it is a dataset with over 400 different groups (drugs), I wanted to first run a group loop that only forecasts each drug individually and then the feature selection loop start to identify the significant variables. Unfortunately, I get the error “Execute failed: 0 is smaller than, or equal to, the minimum (0)” within the regression learner whenever i run both loops.
It would be great if I could get feedback on my workflow. I am relatively new to knime and probably still have thinking errors everywhere…
The actual workflow with the whole dataset is too big to upload, so I saved only 10% of the actual dataset as a new table to be able to upload the workflow.
It looks like the data you provided still needs to go through linear regression preprocessing (checking for redundant variables, removing highly correlated variables, checking that you have enough unique samples per group vs the number of variables you have).
In particular I found a loop where all the variables you provided had the exact same input which causes the ERROR Linear Regression Learner 3:36 Execute failed: 0 is smaller than, or equal to, the minimum (0)
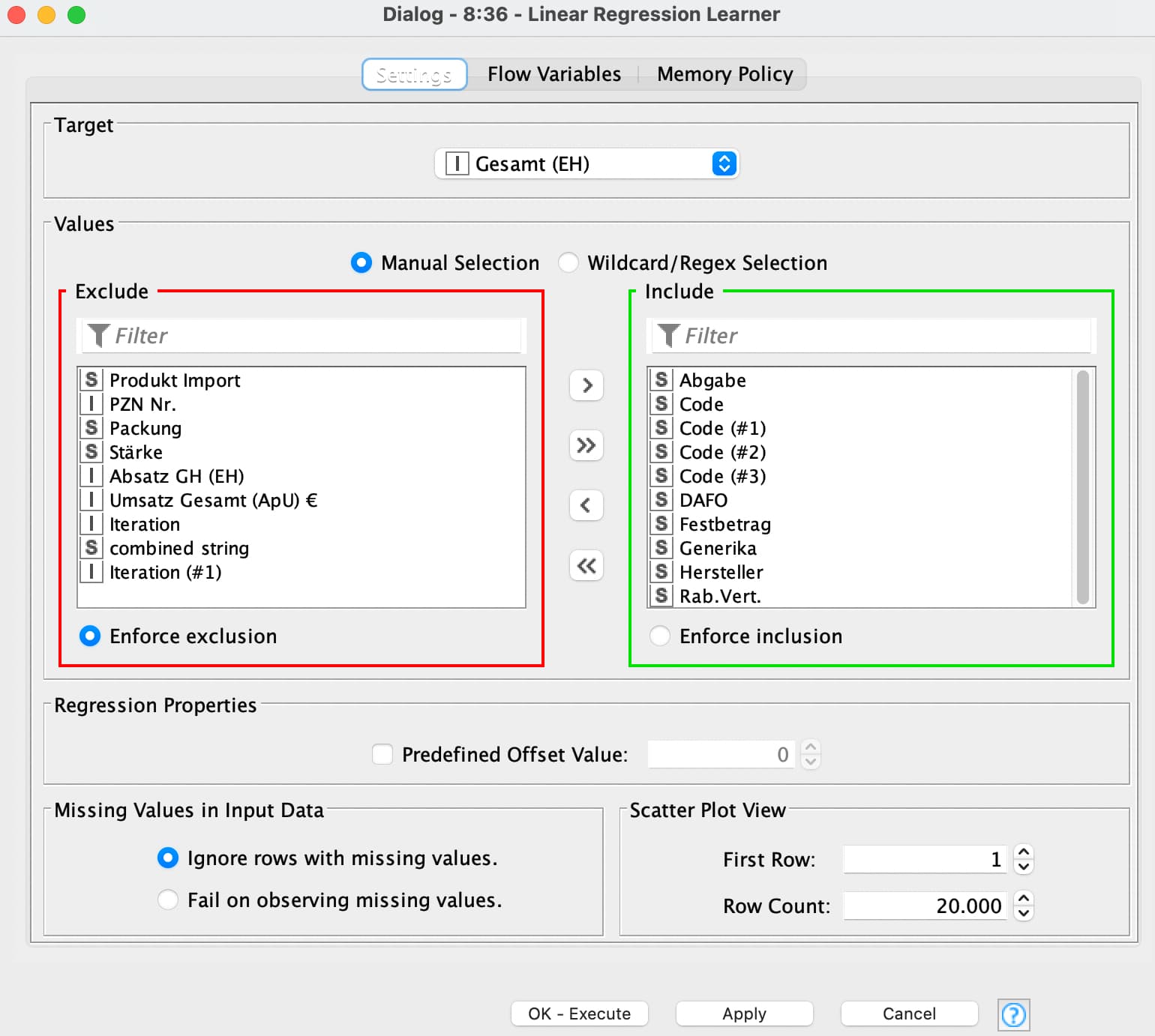
I probably made a mistake somewhere. My idea was/is to include the string data (manufacturer, dosage form, patent situation etc.) as well as the numerical data (offered price, manufacturer discount, etc.) in the regression model, but for some reason I cannot include these numerical values in the regression learner if they have already been inserted in the feature loop selection start node.
And I’m using linear Regression because the forecast should be about the sales number, if i have understood it correctly, with the tree regression i can only forecast a group/ category
I will add my general comment that I would really avoid the feature selection loops. They take way too much time to run if you do it properly. You would need to do a cross validation loop for each feature selection loop else you are just optimizing for one specific split which will not generalize well at all. And the more features you have the worse this gets. Essentially you are trying tens or even 100s of thousands of combinations which from a certain view point could be considered p-hacking (searching for accidental correlations)
What else should you do then?
Most important is to remove correlated features and constant features. If you think you still have too many features you could do a random forest feature importance and just keep the top N features. This will run orders of magnitude faster than a feature selection loop.
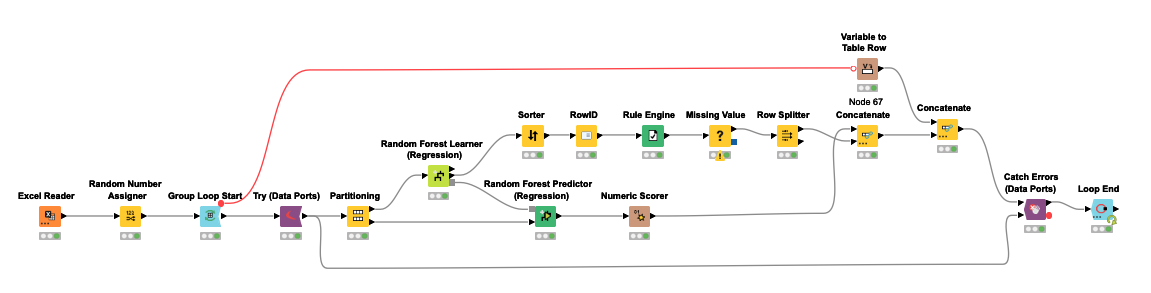
I used a try-catch paradigm to deal with the issue you have of loops breaking because there isn’t sufficient data (it is better to instead to check this beforehand and remove such issues).
I used a noise column to assess which columns perform as good as chance (i.e., don’t add much to our predictions).
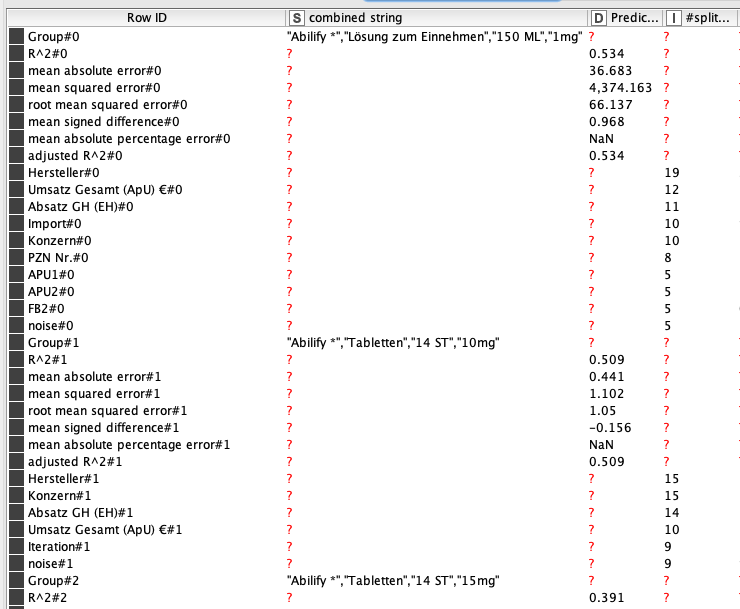
Finally I collected each loop within a group labeled by it’s drug. Notice the drug name and dose come first to mark each group, then the R^2, etc. scores, and finally a list of features by importance.
Just remember that feature importance is meaningless if the model is not performing well, but even when the results are great, still take the output with a grain of salt.
i used your workflow and ran it with my whole dataset (the dataset i put online has only about 10% of the data, otherwise it would be too big to upload) and got relatively “good” values, i will check the result again.
Basically this forecast is only theoretical, the company I work for will not use it, it only serves as a topic for my bachelor thesis.
if i read the model correctly, it aims to make a forecast for the total sales volume of a drug. can it also be applied to the forecast for individual manufacturers, even if the forecast is worse? (manufacturers = Hersteller)
And yes you should be able to group by manufacturer instead of drug to forecast sales.
If your thesis is published and incorporates KNIME, we may also be able to add extra attention to it on our website depending on the content. If you’d like that kind of network reach, let us know and we can talk about it through email.
Thank you for the offer Victor, but since I will hand in the thesis in the next two weeks, I don’t think it would fit time-wise. In addition, the thesis is in German and English is unfortunately really not my strength. I have to admit that I have no idea about DL and that I expected too much from myself. I will mention KNIME as my Tool for making all the forecasts, but not much more. I am studying business administration and my statistics lectures are also some years ago. I will try to make the best of it.