I have used Random forest classification for the prediction of accident severity (Class Variable) for the data available with me for road traffic accidents, Now I want to find which features are important in terms of predicting accidents severity,
I want to know how I should find the features that are important (scoring of variables)?
I am attaching the data set and KNIME workflow for reference?
@Haroon_954 this article about automated machine learning also has a passage about variable importance, currently if you want to have the power of feature importance with H2O Automl you would have to use R or Python.
Also most H2O.ai model nodes have a generic feature importance output (like GBM)
Thank you so much mlauber71 for your kind and detailed reply to my query, I definitely will look to this solution you mentioned, hopefully, it will solve my problem**
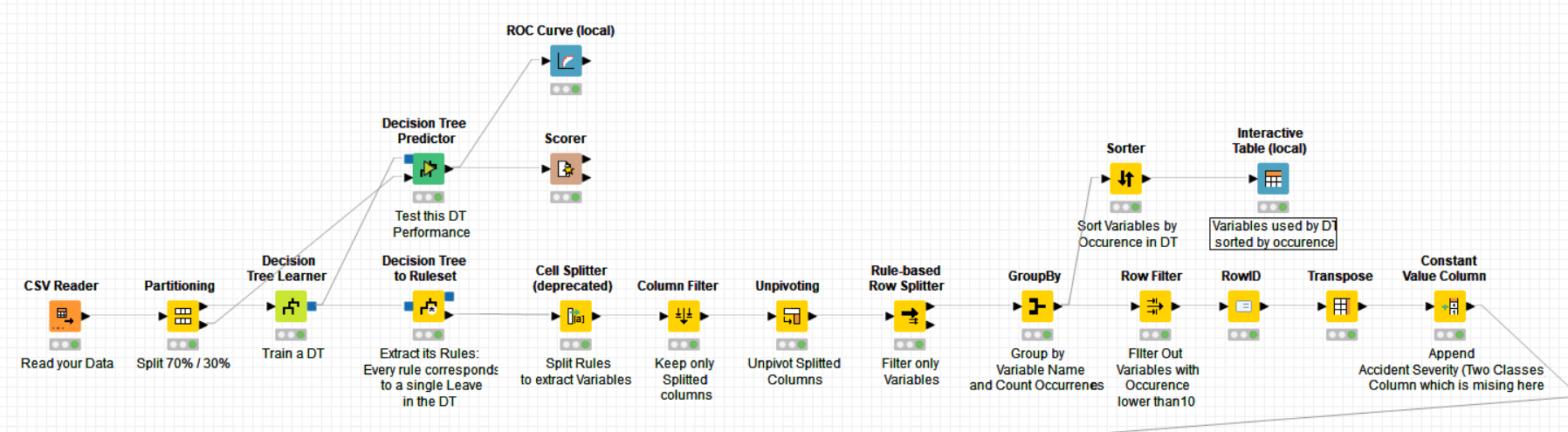
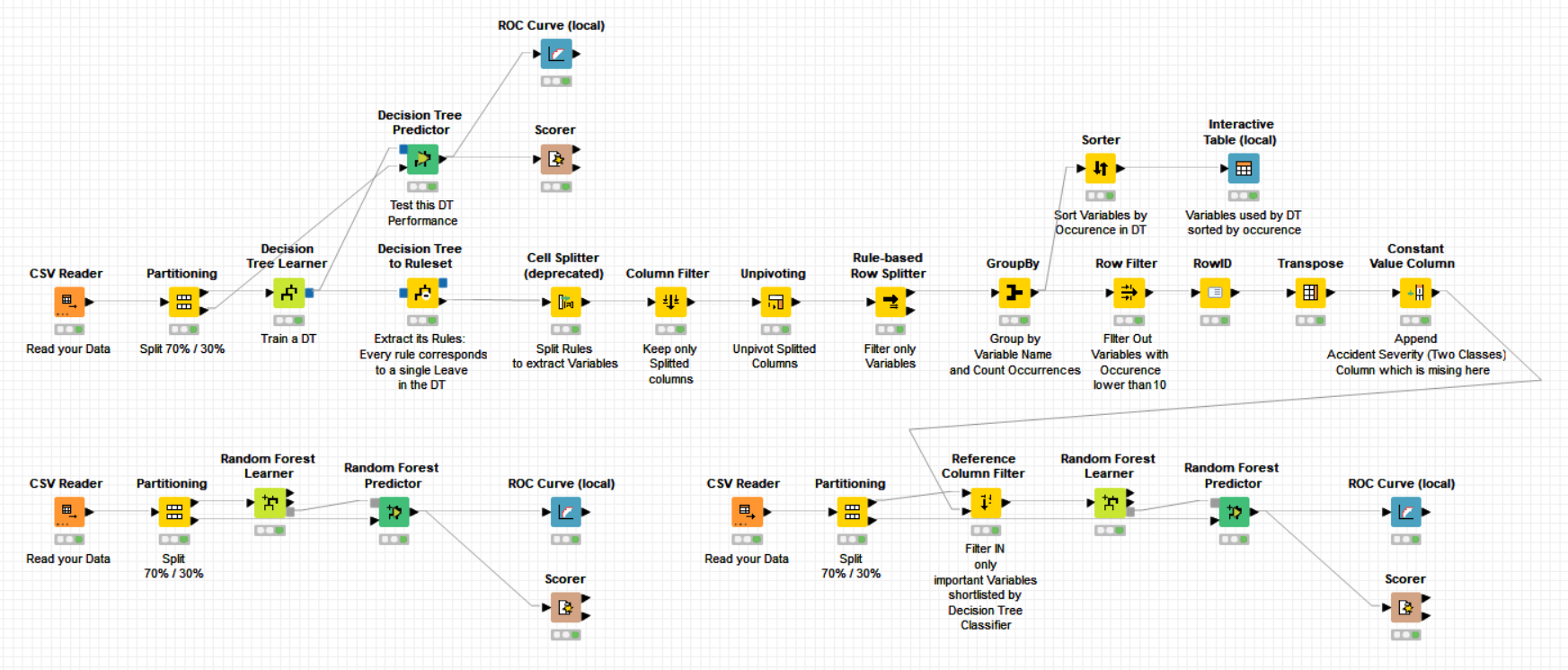
Complementary to the information provided by @Iris and @mlauber71, I have added to your workflow a simple way of doing variable selection based on a Decision Tree. I guess what you need too is to understand how a DT in particular and a RF in general do variable selection but for this, I believe it is good to start with a Decision Tree since RF are made of Decision Trees.
Taken your data and trained a DT using your data splitting (70% / 30%)
Extracted Variables from the DT rules using the -Decision to Tree Ruleset- node
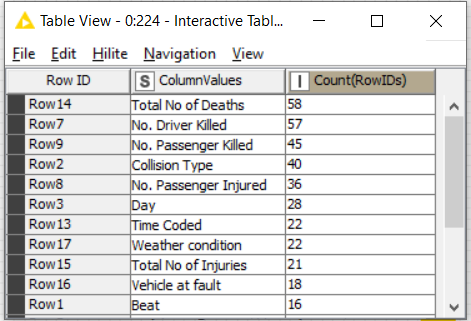
Counted how many times every variable was employed by the DT. Usually people determine DT variable importance based on at which DT branch level it was used, the highest the most important. It turns out that there is a strong correlation between variable branch level and eventually # of variable occurrences in the DT rule set. Thus you can determine variable importance based on variable occurrence in DT rule set too
Filtered out variables with occurrence less than 15. This threshold here is set arbitrary but could be estimated too. I’m not adding threshold estimation here to provide you with a first simple solution that you could easily understand to begin with.
Using this variable selection, you end up with 11 most important variables in terms of rule set occurrence:
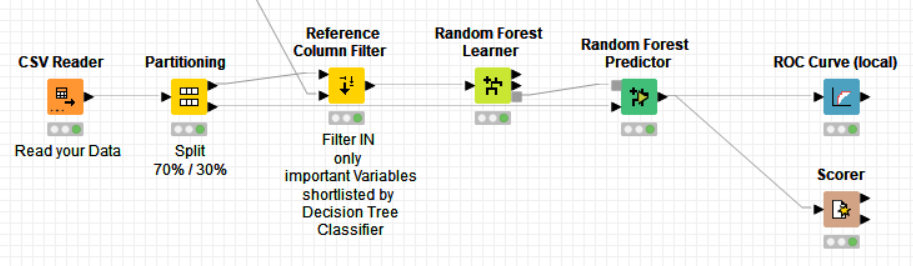
In a second workflow, I filter IN only selected variables to be used to train your RF classifier.
This approach can be extended to do Variable Selection using Random Forest instead of a DT but my aim here is to provide you with an example on how to easily achieve variable selection based on a DT, how to extract this information from the DT tree and how to reuse it in a RF.
Hey, @aworker, Thanks for this detailed explanation for getting important features for the Decision Tree. It was really helpful. I am trying to use and compare different models on the same dataset, and I have used the decision tree and got features that are important for that model. I am also trying to use SVM and Naive Bayes. Could you help me know if there is a way to find important features for Naive Bayes and SVM?
Thanks for your comments and compliments.
It is good you found this old thread with the solution I posted for RF variable selection and that you tried it.
However, you are posting here in parallel to your more recent post related to the same question:
I will hence reply to your question in your more recent post to avoid thread leakage in this one