I got the following problem; hopefully as you’re the forum-analytic gods you will be merciful with this poor guy’s problem.
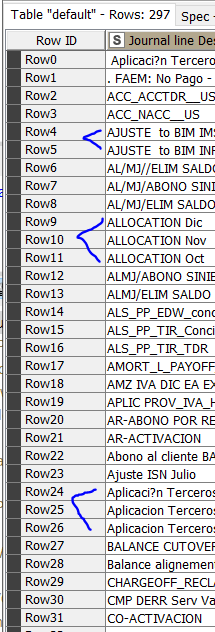
I got a big big list of string inputs (1000k+). These inputs should have been standarized and only should have been input only when chosen from a 1k options list but things did not go as planned and data is now a mess; writing each input with different characters, random digits, missing letters, words in different order, etc…
I need to narrow down the original 1k option list.
At first, thought fuzzy match would be my solution but i need the “dictionary”, or the 1k list so it can match the different inputs.
Now i think i need to string manipulate and get the 1k option list manually, checking the inputs 1 by 1. So far i’ve tried string manipulation to remove digits and specific words, groupby node but still, my selection is way too big to do it manually.
screenshot
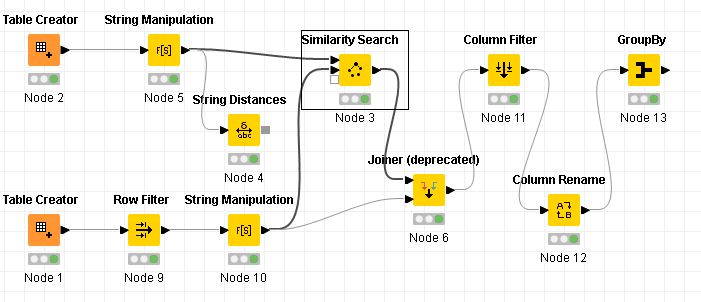
@jmanuelml21 here is an example of how you could identify duplicates and bring them together without having a ‘ground truth’. The workflow will try to determine the groups for itself.
Then you can do more address matching and deduplication with these examples:
many thanks for your input. This is greatly appreciated. I’m giving your workflow a try but looks like it’s not as simple as i thought. I will have to go over calmly and understand each step as i go over it. There are many resources which i’m not familiar with. I’lL let you know how it goes.
again, thanks!