once a while I happen to encounter a very nasty data issue, caused by copy & paste i.e. form Excel (iso-1252?) to a web editor (utf-8). Issues can manifest in corrupt data being saved (broken CSV) to processing in Knime coming to a complete halt.
In this particular case it’s an Zero Width Space Unicode Character <0x200b> which only becomes visible when copy & pasting the cell at fault into an editor like sublime. Though, you must be very lucky picking the exact cell or tediously reduce the data set to gradually narrow it down.
The question is, how would you deal with that issue? I even struggle to properly phrase it. Is it an encoding discrepancy or something entirely else? Thanks for your feedback!
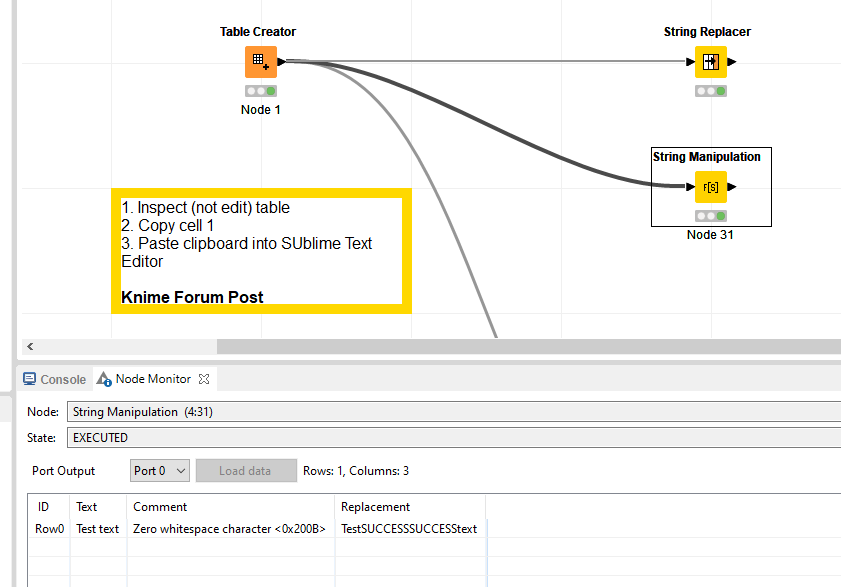
Thanks for the suggestion but my case is slightly different as the character I am talking about is not visible per se. I tried search and replace but no approach can actually find the characters in question. Here is the workflow.
Not, though, I could only reproduce it since I found another occasion but I never was able to deliberately cause that kind of data issue by manually creating the text myself.
Thanks for your suggestion @ArjenEX. Albeit it shows that Regex can target these sort of characters this RegEx is slightly too generic creating the possibility of false positives. Wonder, if matching
Exact RegEx for unicode doesn’t work means it’s interpreted
Searching for RegEx any whitespace \s doesn’t work
What possible character the zero with space could match to in RegEx
However, that would not help to circumvent any non-compliant character being present. Maybe the issue must be tackled from a different angle … will give that some thought over the weekend.
@mwiegand can you provide an example of such a special character in a UTF-8 file or something (edit: I might check your example). And the I think like in the thread @badger101 mentioned that maybe defining a positive list of characters and eliminating all the rest would be a good way forward. Since if your data might throw such Unicode characters at you more often you might easily miss one by just going after the one.
I tried to put together a collection of such characters for English but have not yet found a sufficient string for: European characters with reasonable special characters (Blanks, punctuations …) but no hidden blanks, ascii blocks and so on … that would be the challenge by going with a positive list.
Looking up this specific character, it falls into a class of unicode characters termed “Formatting”. I was recently investigating how to strip emoji and other characters from strings, and in the process discovered some quite useful info.
In regex, there are a set of regex patterns describing unicode “classes” or “categories”. Once you know the class you wish to find or filter, you can then use these patterns.
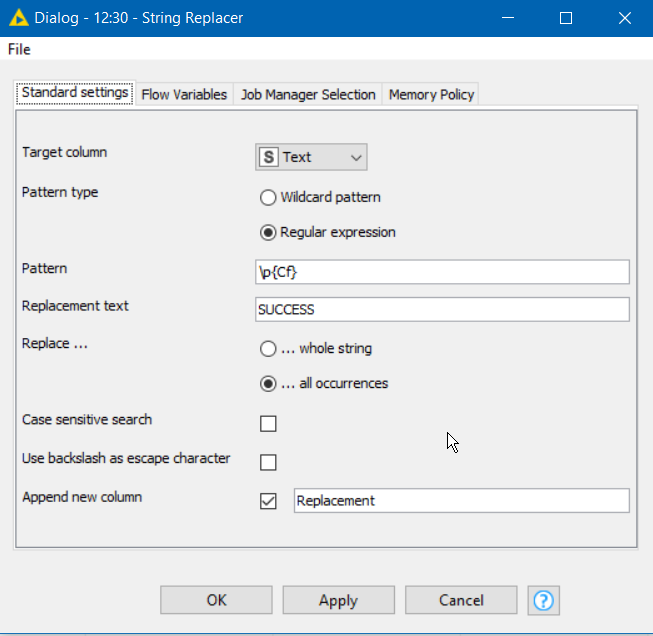
The pattern for this particular Formatting class is \p{Cf} , so if you replace your regex “SUCCESS” node to look for that class instead, you will find SUCCESS!
I had a go at putting together a component for filtering based on these classes, with some success. It can be found here, and is useful if the aim is simply to remove characters of particular classes.
(If the config screen for the component only initially has a small number of classes listed, try executing the component to “refresh” it. I probably need to fix something, but not quite sure where.)
Some information about the different unicode categories, such as the “formatting” category can be found here:
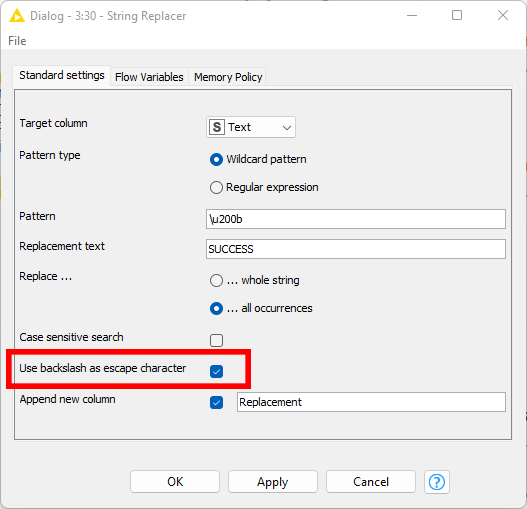
You can use the string replacer node to remove Unicode characters.
You need to enter the value as a escaped Unicode character \u200b and check the ‘use backslash as escape character’ checkbox. This will detect the character as required.
My previous (deleted) post was pointing the finger at KNIME not identifying Unicode characters correctly. Whilst, KNIME does identify escaped Unicode characters in the String Replacer node, it does not identify Unicode characters in the String Manipulation node. If you enter the formula `string(“\u200b) in the string manipulation node then it returns the text “\200b” rather than the Unicode character. Note, that if you enter string(”\n") in the string manipulation node then it does escape the character correctly. It is only Unicode support that is missing in the String Manipulation node - which is a bit of a nuisance.
You are correct to the extent that, if you use regexReplace and double escape the Unicode character \\u200b, the character will be substituted by the replacement text. However, the normal replace function does not work with either single or double escaped Unicode characters.
Double escaping in strings is not a good implementation within KNIME. Personally, I would consider this an undesirable implementation and regex strings should be consistent with other programming languages (i.e. only one backslash is required to escape a character). It is also inconsistent with other fields and nodes in KNIME where double escaping is not required. As a tool which is aimed at the low-code community lack of consistency within the software and with other software tools is a nuisance which is difficult to explain to new users.
A wonderful good morning! I love this community …the nastier the problem, the more likely you are finding some enthusiasts with great ideas. To conclude / recap:
@takbb found it’s a class of unicode characters called “Formatting”
Note: I found with his help this comprehensive overview (section Unicode Categories)
Several interesting issues related to Knime nodes processing these characters differently / inconsistently were noted by @DiaAzul (namely String Manipulation Node)