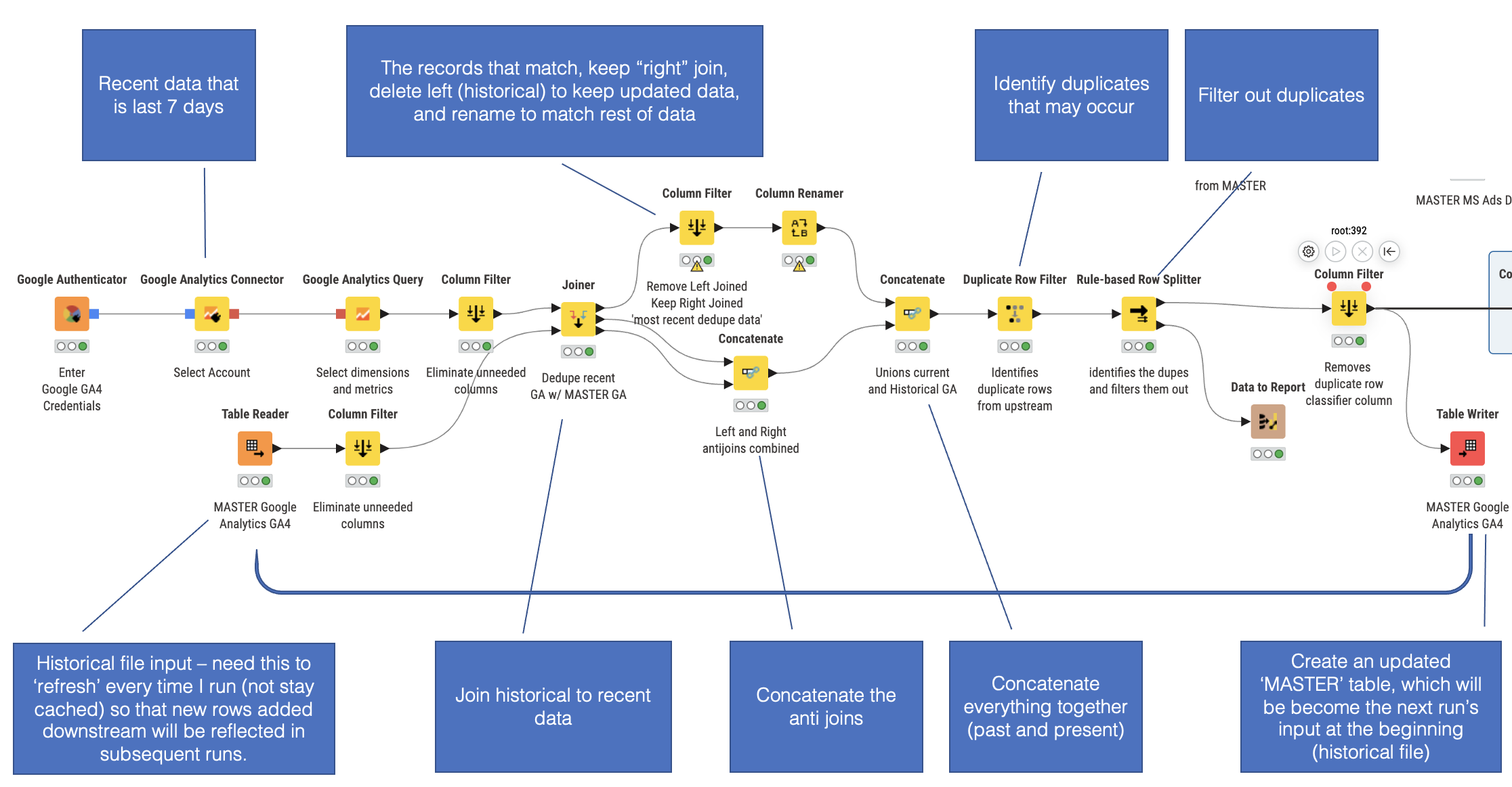
I’m creating a dedupe mechanism where I’m pulling in recent data from a source, using “last 7 days” and joining to a ‘historical’ .TABLE file stored locally. I’m joining on a couple of fields, including date. I want to keep the most recent in the event values have been updated in the last week. In the joiner columns, I"m concatenating the left, right, and joined fields - filtering out the ‘historical’ last 7 days and keeping the most recent, then writing to a table writer, which becomes the next day’s "master input table’. The problem is that once the reader node is executed, the data is cached all the way through the workflow.
So the question is, how do I configure the ‘master table’ to run every time i run the workflow? I appreciate that the data is cached for quick processing, but I need the file to read the new data each time without having to manually go into each reader and resetting them. I’m using .csv, Excel, and .TABLE files and have a handful that need to run.
don’t know how you start your workflow but connecting Google Authenticator node with Table Reader node using flow variable connection should do the trick.
For recent data I pull in through Authenticator, but to get history for past couple of years, I merge that flow into a .TABLE file to avoid sampling of data and only pull in recent data and blend with the history table. I’m the image I posted, the Authenticator is coming through the left join, the history table from the right. I’d like the .TABLE mode to reset every time I run workflow because I have upwards of 10 work streams that follow this pattern and I would prefer to not have to manually reset if possible.
You can save the workflow in an unexecuted state and then “call” it from another workflow. This leaves it in a ready state. If a generic version can be customized for all 10 uses by passing the necessary info, then it can be incorporated into a larger series run from a main workflow via a loop, or incorporated into many different workflows.
@mlauber71 Just a heads-up: Mentioned node is also available as part of the free NoOp Nodes. As we got a few requests for this very specific node, @qqilihq was so kind to fork it from the Selenium Nodes and make it available for free.