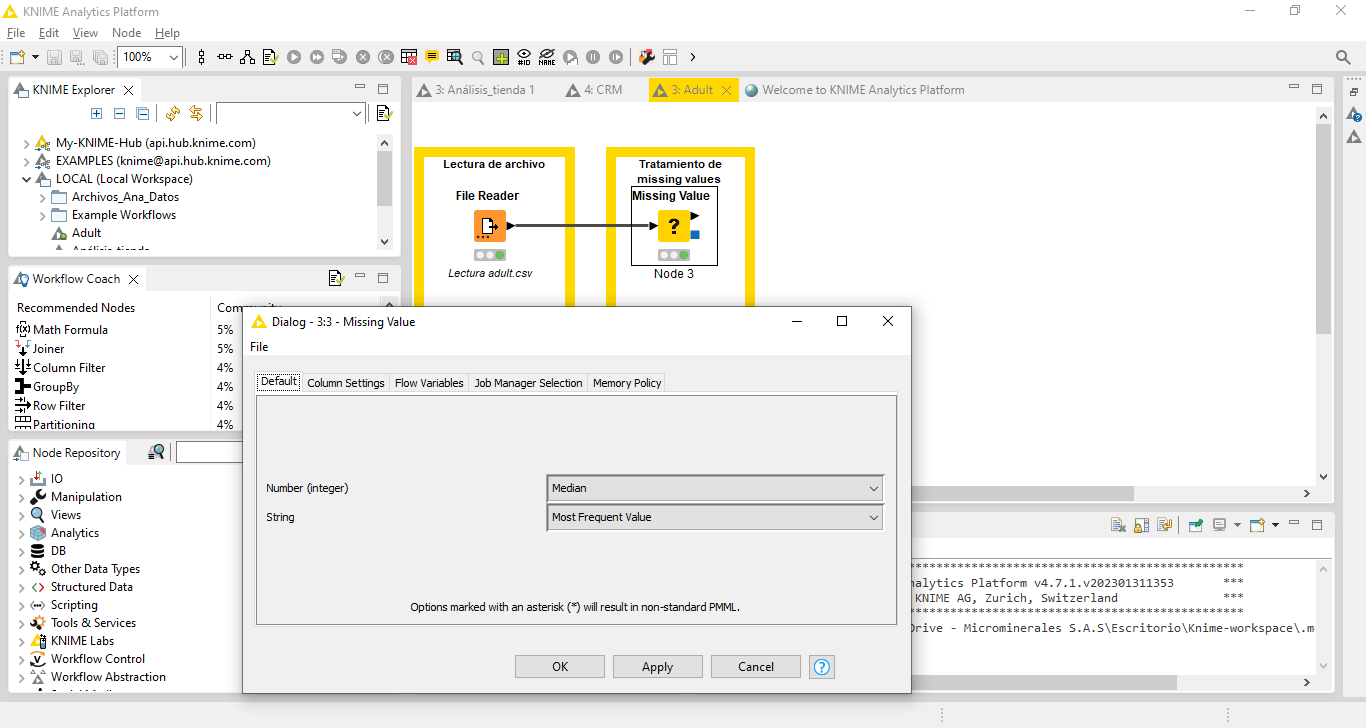
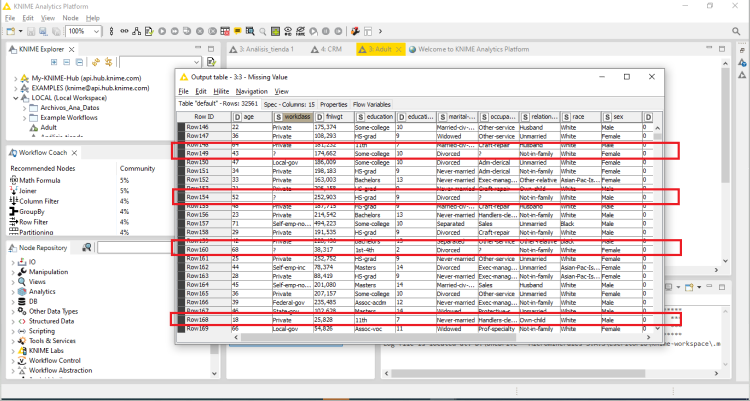
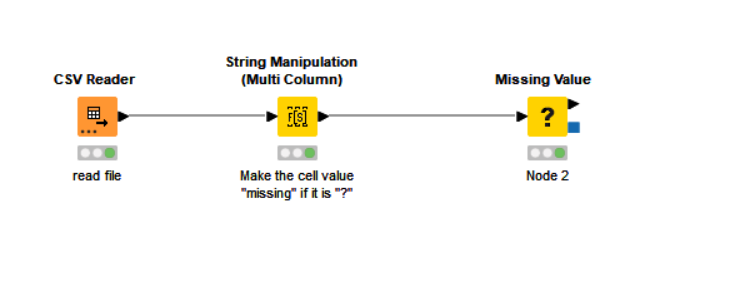
Using Missing value node in my workflow, after setting with Median (for integer) and Most frecuent value (for string), I verify through output table that does not replace the “?” signal in my output, in few words there was not change. Beside, there are not yellow or red alert in the node. Please, check my attachment.
It is difficult to tell from your screenshot, but are those definitely missing values and not simply “?” question-mark characters in your data?
I’d expect the question marks to be displaying in red but they don’t look red to me, although that may just be the poor resolution of the uploaded screenshot.
To get help with this, I think it would be better if you could upload a workflow with a small sample of data (with any confidential information removed/changed) that exhibits the problem, ensuring that the sample csv data file is included in the workflow’s data folder so that it gets uploaded too.
As already mentioned by @takbb and @denisfi with a sample we could provide a more accurate answer
Nevertheless looking to the pictures , seems to me that you are trying to replace values in double variables and configuring the node to replace integers.
If I am correct , all is needed is you change the variable type before the missing node replacer . It can be done with table manipulator
Or alternatively see the options for replacing doubles.
Hi @clos , I think from looking at the screenshot of your csv file [EDIT: that is now in your post that follows this one as the original was deleted] that it actually contains physical question marks.
KNIME does not treat question marks as missing data but it displays missing data as red question marks in KNIME tables, to differentiate them from non-missing data. So if you have actual question marks they won’t be changed by the Missing Values node.
Missing data in a csv file should normally be represented by simply placing no value between commas rather than including a ‘?’. Do you have any control over how the csv file is being generated?
My workflow is not finished. I did a pause when I got this issue.
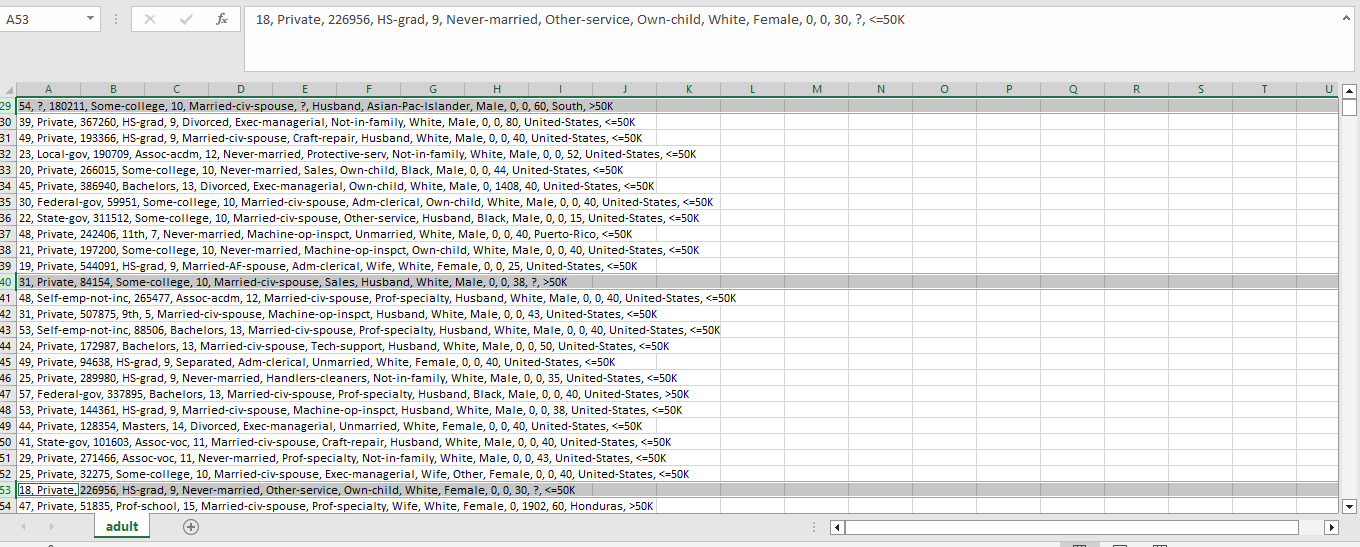
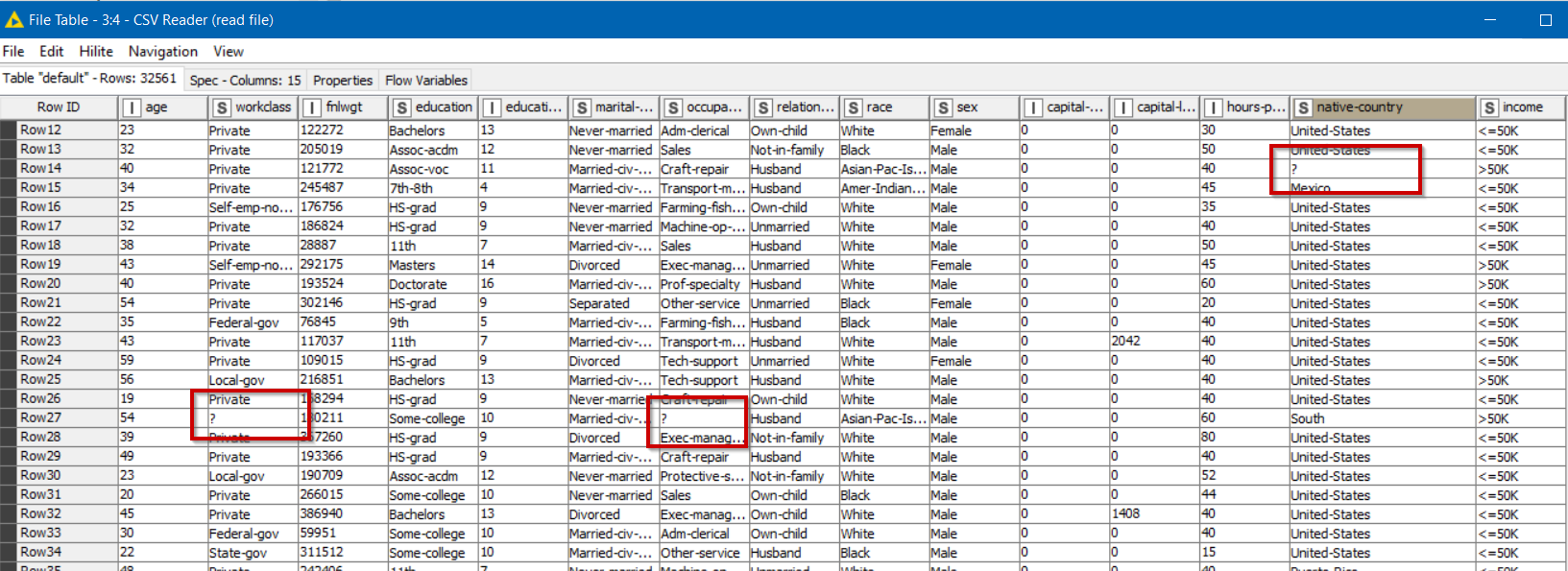
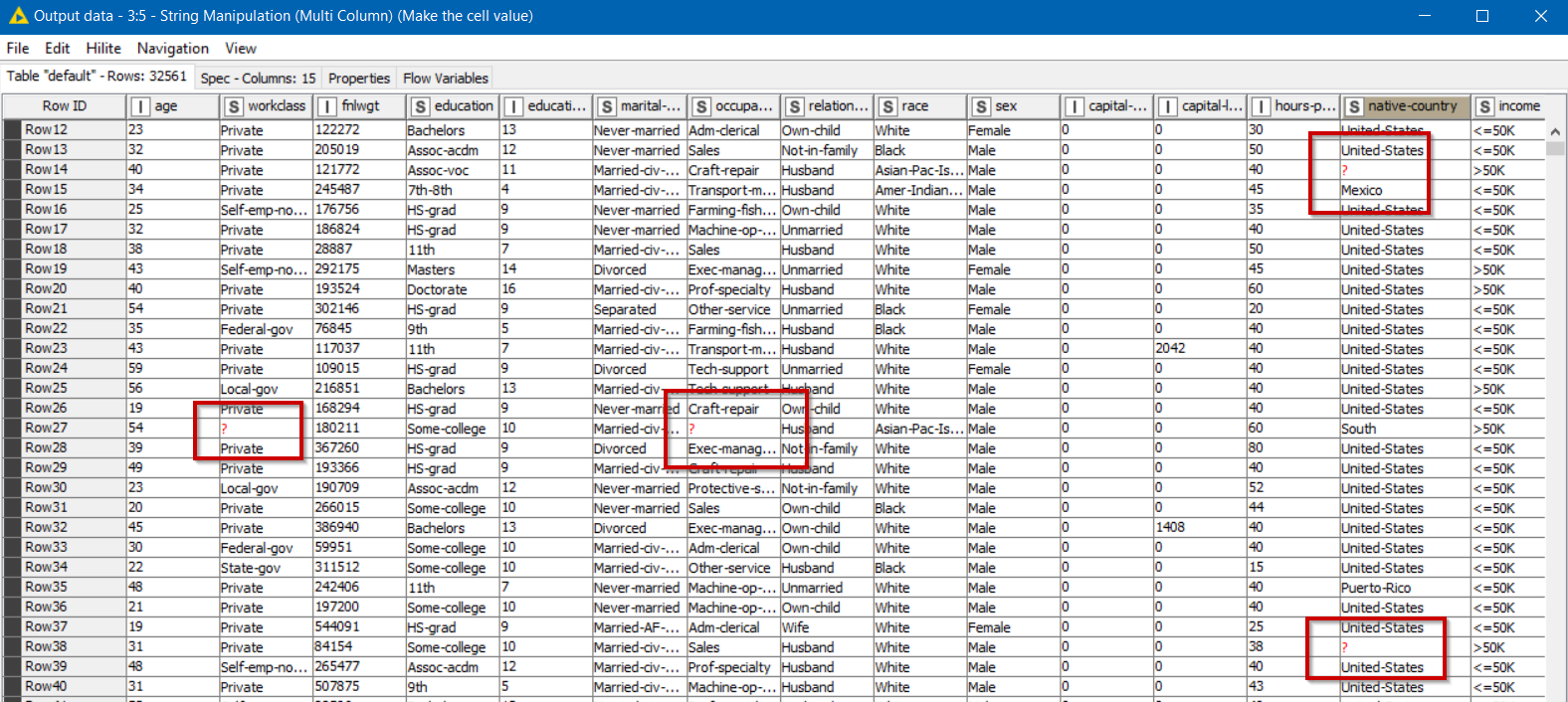
To be expedit , I attach a scrrenshot of my data (csv file). As you can see, rows 29, 40 and 53 contains “?” signs. There are more rows with more “?”, of course.
Hi @clos, can you upload an actual sample of the csv file please (not just a screenshot). That way people can assist you with your specific problem. As I wrote above, I think your problem is that your data actually contains question marks, but only by seeing the physical example of the data can we be sure. Thanks
Hi @clos,
As @takbb wrote, a question mark is a perfectly valid, normal string value. If you had a column “My favourite punctuation mark” with contents like !, ?, ., etc., how could KNIME distinguish between a ? that is meant as missing value and one actually having a meaning? This means you need to process your data with a different node than the Missing Value node. One possibility is the Rule Engine node with a rule like:
This will replace all “?” by “replacement” and keeps all other values the same, if you set the node to replace the column “yourcolumn”.
Kind regards,
Alexander
Hi @clos, I had forgotten there is a restriction for csv files, and I don’t know why there is, but if you rename the extension to .txt, hopefully you can then upload that. thanks
As a the Rule Engine node works on a single column basis. You may want to deploy it in a column loop. Otherwise you will end up with a 15 Rule Engine nodes workflow, as the number of columns in your sample file.
Hi @clos
Thank you for uploading the file. Yes this confirms that it does indeed contain the literal “?” as data items, rather than having missing values. See how in the following output from the CSV Reader, they are black.
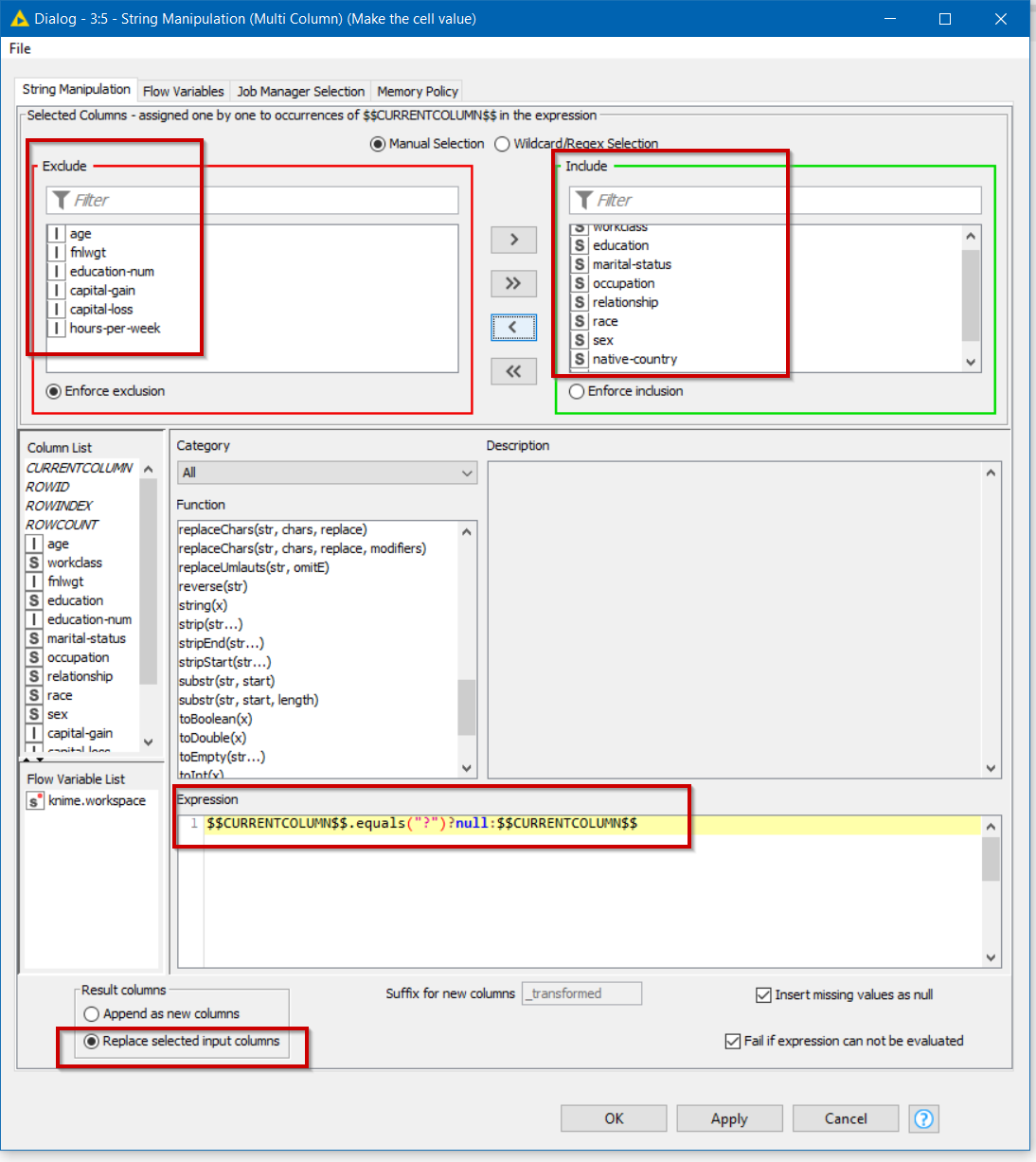
You need to specify all of the String columns that might be affected by the presence of “?” values, as the function will work only on string columns, but that should be ok since numeric columns cannot contain a “?”.
Once that runs, the output will look like this, and you can see that the ? symbols are now red. As mentioned before, these cells no longer contain “?” but instead KNIME is displaying a red question mark to signify missing value.
Interestingly, having just looked back at that post I mentioned from 2 years ago, there is a suggestion that the File Reader node could handle this. Except that I just looked, and it can’t. So I was curious about that because from experience, @ipazin is never wrong about these things!
And it appears that the current File Reader node no longer has this “missing values pattern” option. I wonder why.
See reference here to the deprecated version.
and what I have also just noticed is that this post also refers to the “adult.csv” file… this file is apparently in the KNIME example data sets (in the data folder of knime/Examples – 34_GDPR_examples – KNIME Community Hub), and has “?” as a placeholder for null !