Hi knimers,
suppose we have a table with may rows and many similar columns. How does one efficiently apply an operation to every individual cell?
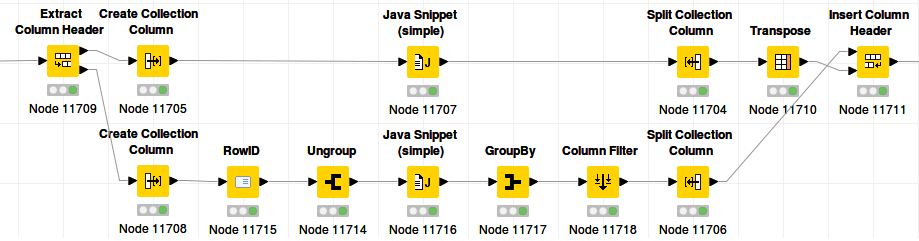
For example, suppose we have a 2000x500 table of Doubles. We want to multiply every cell in that table with 2. We could use a multi-column math node, but let’s try to avoid that node for now. We put our multiplication in a Java Snippet to make the solutions perfectly general. A beginning Knime-user will likely go for a Column List Loop:
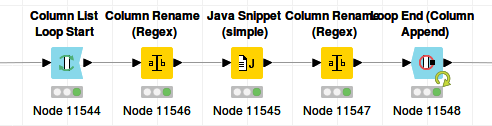
It works, but it is very slow. On my pc, it needs 201 seconds, more than 3 minutes.
If we put the Column List Loop inside the Chunk Loop, the whole thing is a bit faster:

This one is done in 51 seconds.
A more efficient option is to loop over the table row by row, but then the row needs to be transposed within the loop, and then transposed back after the operation. To get our original row IDs back, we have to apply some node gymnastics:

Much faster: 25 seconds. But kind of ugly. Alternatively, we can assume that the table consists of single-member groups and use a Group Loop. The name of the group is our rowID.

It looks somewhat more elegant, but is slightly slower: 28 seconds.
What if we put all the values in a single column using an unpivot node, apply our operation, and then pivot again?
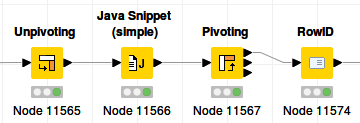
Done in 30 seconds. It also looks quite elegant. Can this be made faster by using chunks?
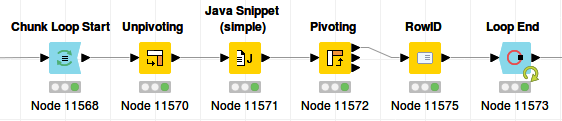
Apparently yes: only 17 seconds.
The slow step in the unpivot - pivot method seems to be the pivot step. If we can replace this with some GroupBy sorcery, we may be able to speed it up even more:
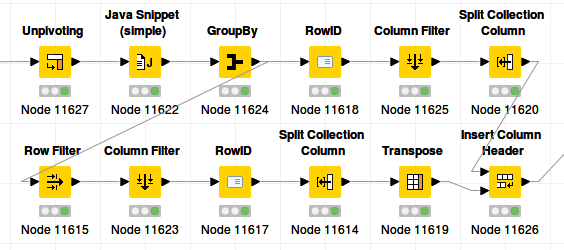
Done in 11 seconds. With chunking:
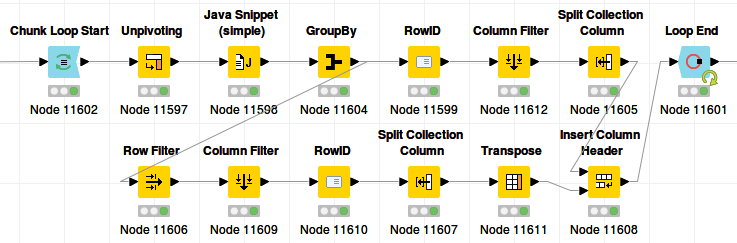
…we can reduce this to 8 seconds.
So this is pretty fast, but it also looks pretty ugly. Remember, we are trying to do something very simple: apply an operation to each individual cell of a multi-column table, so it would be nice if this simplicity has a simple representation in the workflow. Using Group Loop is easier than a GroupBy node and looks more elegant:

Elegant, but not faster: 28 seconds.
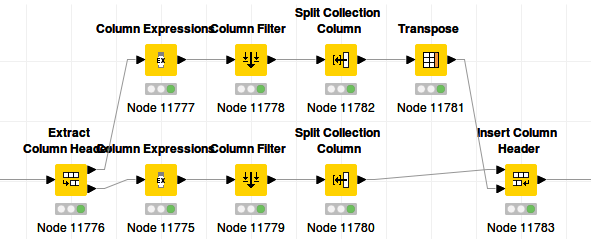
The last option combines all columns in a list/collection cell before applying the multiplication. This requires us to rewrite the code in the Java Snippet to operate on an Array instead of single values:
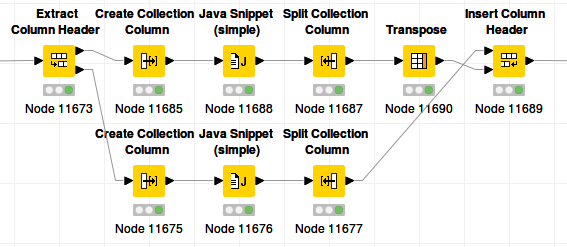
Java snippet content:
Double[] tbl = $AggregatedValues$;
int n = tbl.length;
for(int t=0; t<n; t++) {
tbl[t] = tbl[t] * 2.0;
}
return tbl;
This is the fastest solution by far: 2 seconds.
How does this compare with the Math Formula (Multi Column) node? Surprisingly, this is significantly slower than our optimal method: 14 seconds!
Best,
Aswin
p.s. the workflow with all the different methods:
KNIME_project.knwf (285.1 KB)