Hello guys,
I would need some help with a regular expression extraction (RegEx Split node).
I have tried for days to figure it out but could not find the solution. Neither the KNIME examples, nor the (Java API) indications did help me.
I have a string (text) column from which I want to extract a number. The column it is not omogenous (structure), neither the number (by figures number).
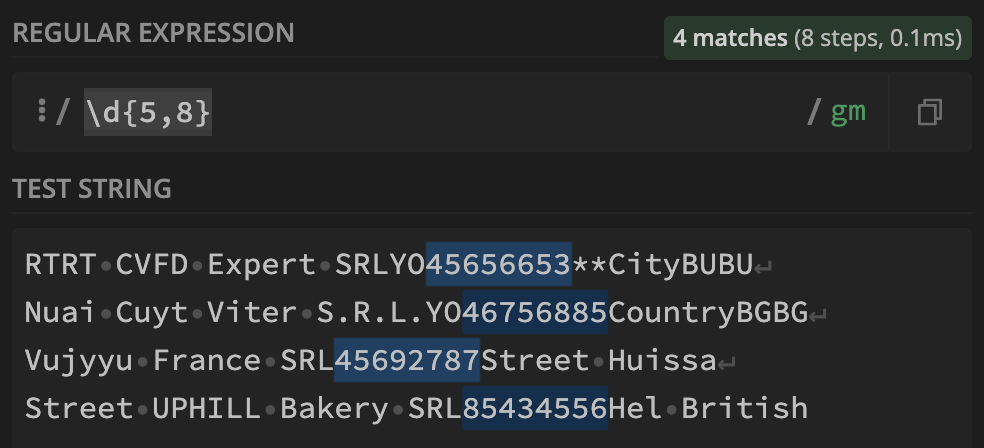
RTRT CVFD Expert SRLYO45656653**CityBUBU
Nuai Cuyt Viter S.R.L.YO46756885CountryBGBG
Vujyyu France SRL45692787Street Huissa
Street UPHILL Bakery SRL85434556Hel British
I need to extract the bold string (figures) by indicating in the RegEx that the figures come either after SRL, S.R.L., YO syntaxes.
It may be necessary for a multistep approach, but still, I need an idea how to start the process.
Thanks a lot @ipazin . It seems like it is working.
However, there are cases were there are two „YO” syntaxes and the result of the regex is the last one, when it should be the first. I dont know why it ignores the first YO.
A simpler approach to this problem would be to match all number sequences of N digits or more. This may or may not be feasible depending on the rest of the data in the text blob.
For instance, the regular expression \d{5,8} matches any number sequence between 5 and 8 characters long.
It’s difficult to handle all of the variations and possible typos in RegEx alone if you are dealing with unstructured (a.k.a., “free-form”) text blobs. You might want to preprocess the text before extraction. Preprocessing steps that apply here include (but are not limited to):
Normalizing all letters to lowercase
Removing all special characters
Normalizing N spaces (two or more spaces in a row) to single spaces (" ").
By applying simple transformations such as the ones above to your data, you can drastically reduce the amount of possible scenarios you must handle with your RegEx. There are a couple related components in my public space on KNIME Hub for text processing if you’d like to check them out.
Here’s an example I used Python for the RegEx extraction step, but there are a few other options. I also used two components which are available in my public space on KNIME Hub:
Also worth a look is the “Regex Extractor” node which will make regex extraction as easy as one of those fancy browser-based tools – but right inside node. More information is available here:
 I used Python for the RegEx extraction step, but there are a few other options. I also used two components which are available in my public space on KNIME Hub:
I used Python for the RegEx extraction step, but there are a few other options. I also used two components which are available in my public space on KNIME Hub: