This week we’re exploring a topic that we didn’t give much attention to in the past: clustering! This very powerful, unsupervised type of learning should be used this week to segment customers into groups with similar patterns.
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason2-2.
Need help with tags? To add tag JKISeason2-2 to your workflow, go to the description panel to the right in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
And as always, if you have an idea for a challenge we’d love to hear it! Tell us all about it here .
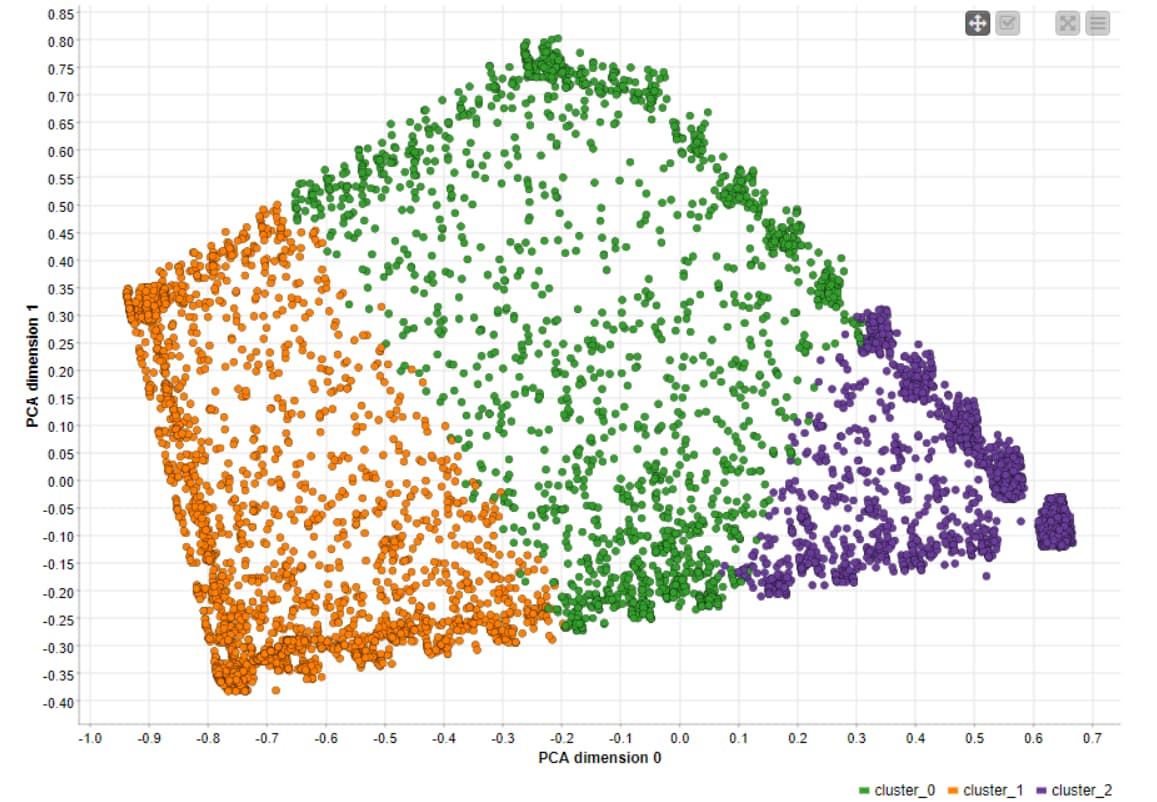
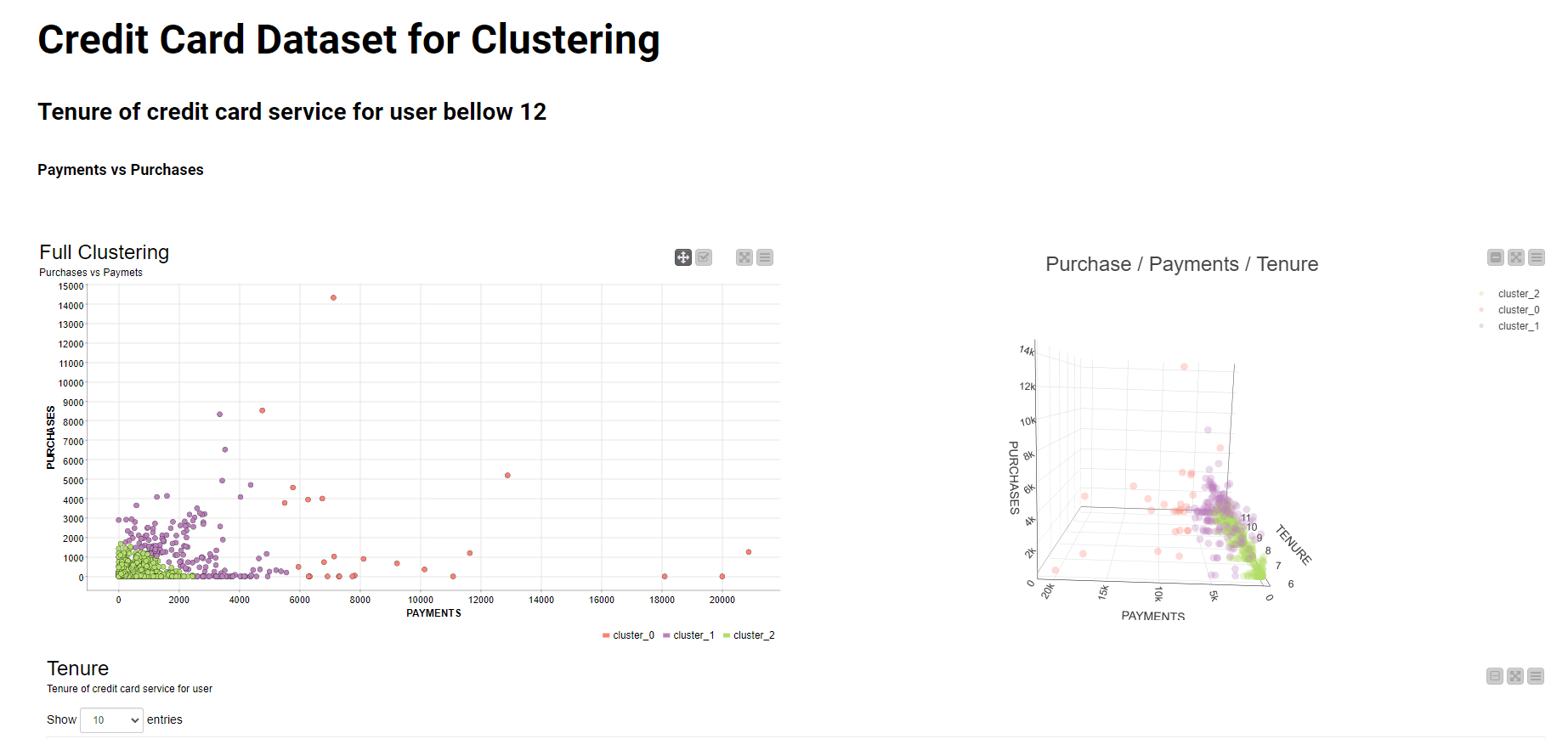
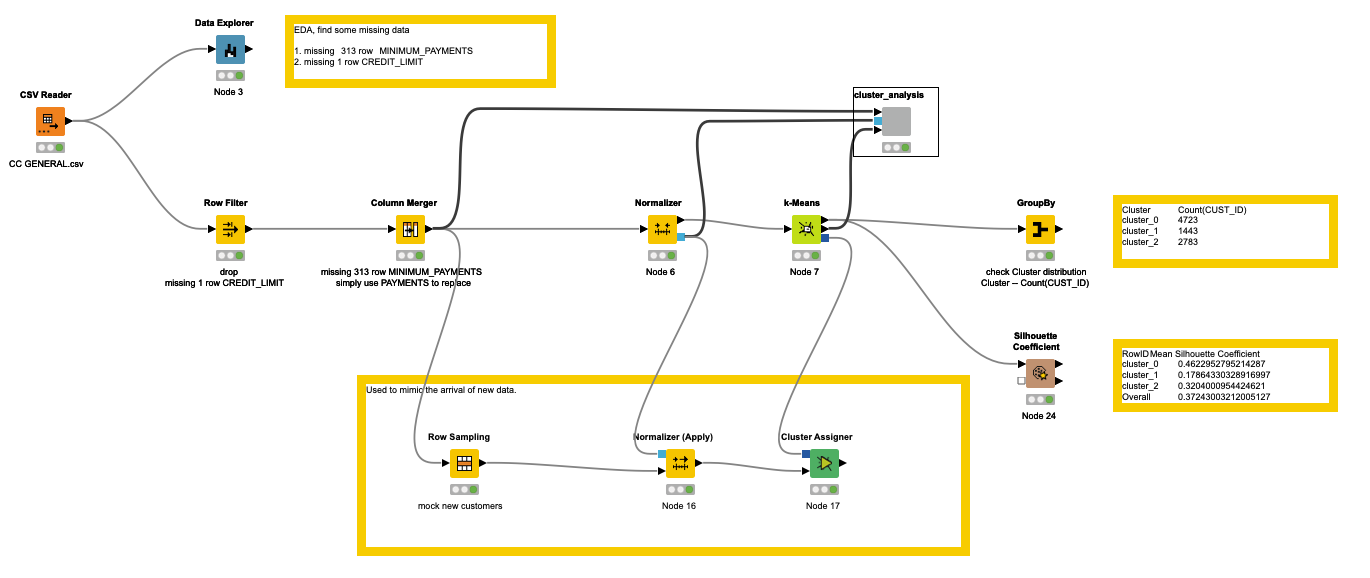
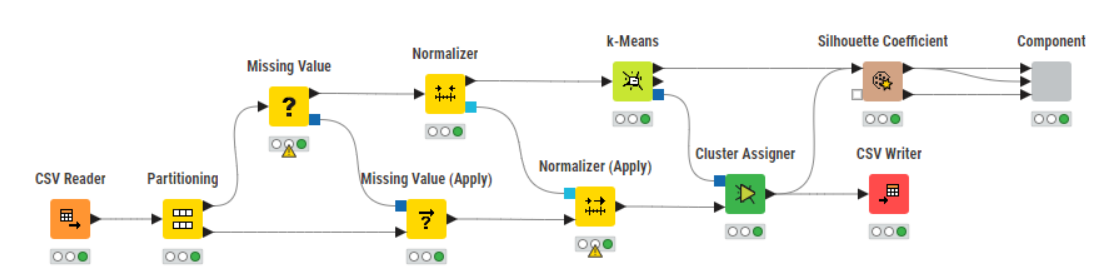
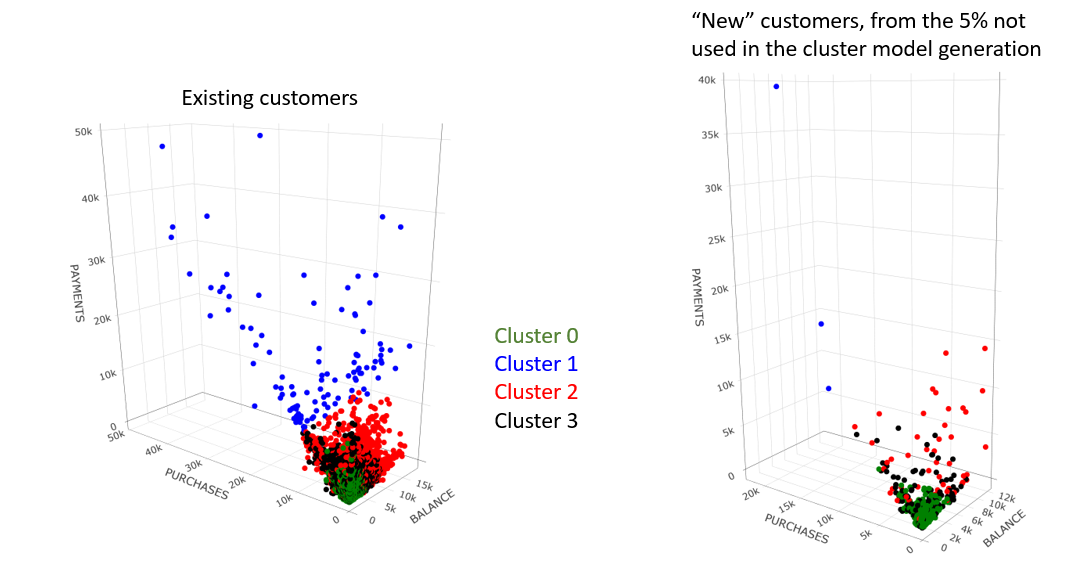
Here’s my solution. Couldn’t quite understand what “new customers” meant in the challenge post. I parsed out the IDs with a six month tenure and used those as the new customers. Also, I couldn’t figure out how to denormalize the data in the modeled part of the workflow for the new customers. Other than that, I think I’ve covered eveything. The clusters are fairly consistent between the two groups. Roughly speaking cluster 0 are the low spenders/users. Cluster 1 is in the middle and cluster 2 are the high spenders with a wide variation. I didn’t play with the parameters much. I’m sure they could be improved. The Silhouette Coefficients aren’t spectacular, but they’re not horrible.
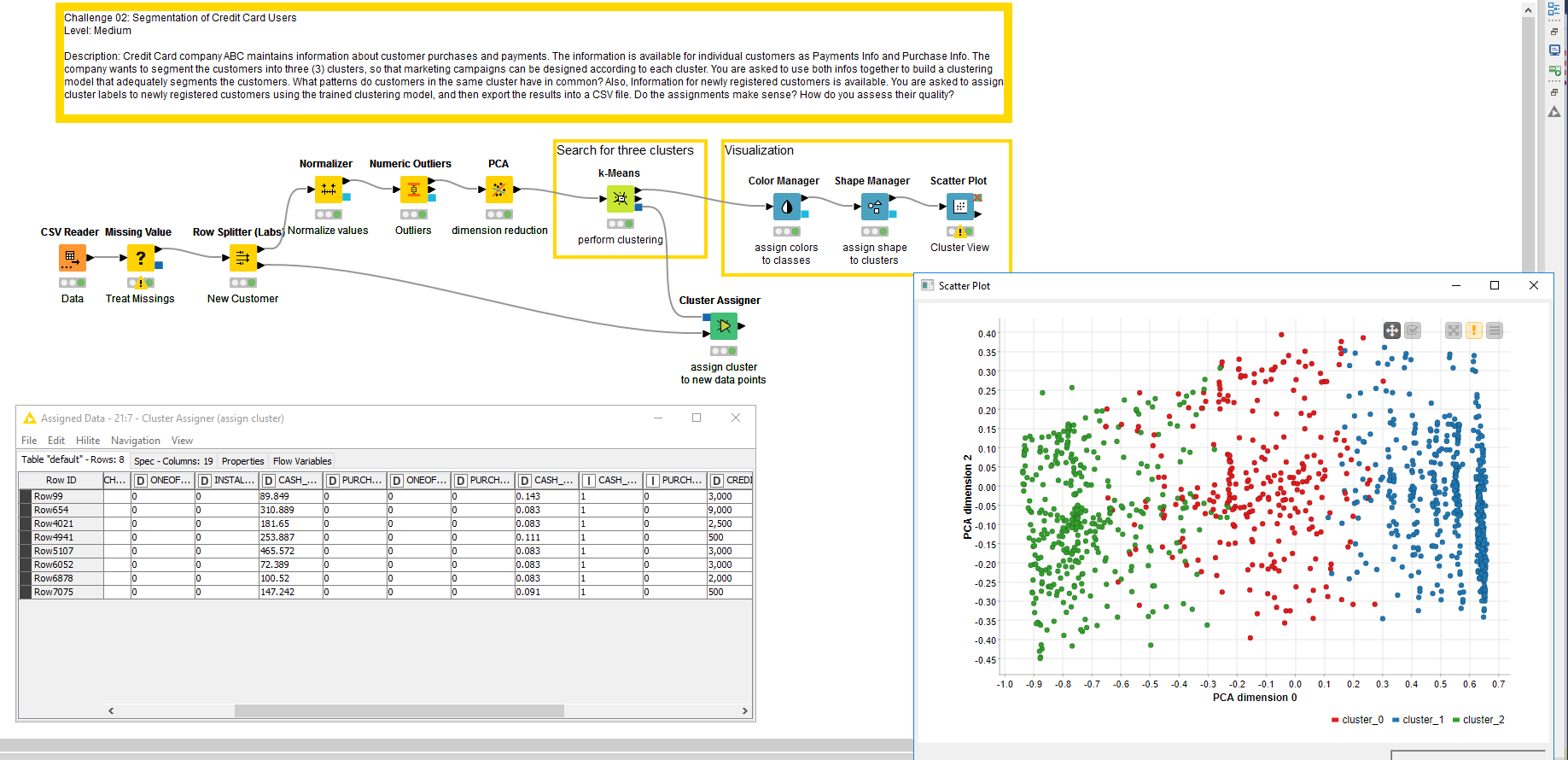
My Submission to the Challenge 2 of season 2.This is a real life challenge where you have to encounter many data fields /dimensions and need to find the relevant one. I have tried to decipher the new customer definition , seems in line and accordingly used the definition for cluster assigner.
Here is my solution.
I tried to use several clustering methods: DBSCAN, OPTICS and k-Means. The first two are running quite slowly, so it is impossible to optimize their parameters in reasonable time. So k-Means seems to be the algorithm to go despite all its drawbacks.
That’s why I sampled 1500 clustering iterations (overkill, I know) to find out if there are any stable cluster centers. Unfortunately I could not find a way to get really stable and robust cluster centers, so I took the best and applied the same clustering model to the new data, assuming that rows with missing missing payments are new.
And getting back the task questions:
Clusters can be roughly interpreted like this:
customers who have quite big balance with small amount of purchases with average credit limit
customers who have quite big balance with big amount of purchases with high credit limit
customers who have quite small balance with small amount of purchases with small credit limit
The quality of the clustering is quite low based on the silhouette coefficient, visual analysis for t-SNE and PCA projections and clustering optimization, when the are a lot of possible scattered cluster centers are available.
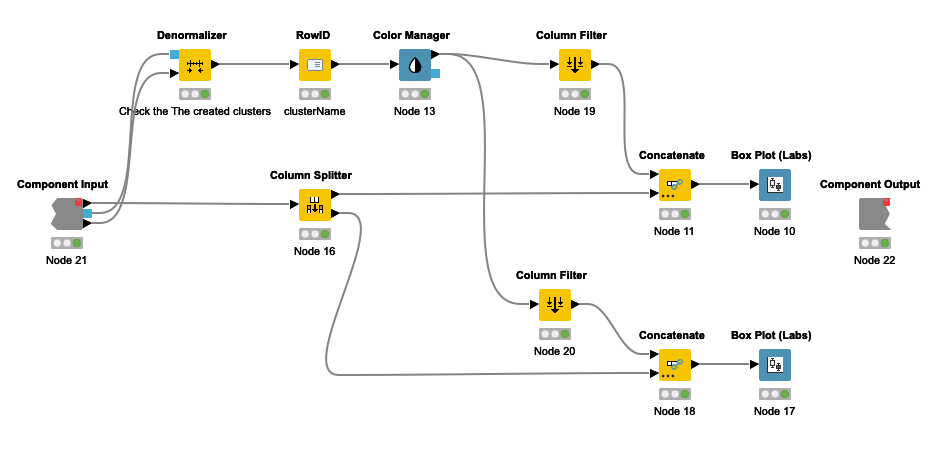
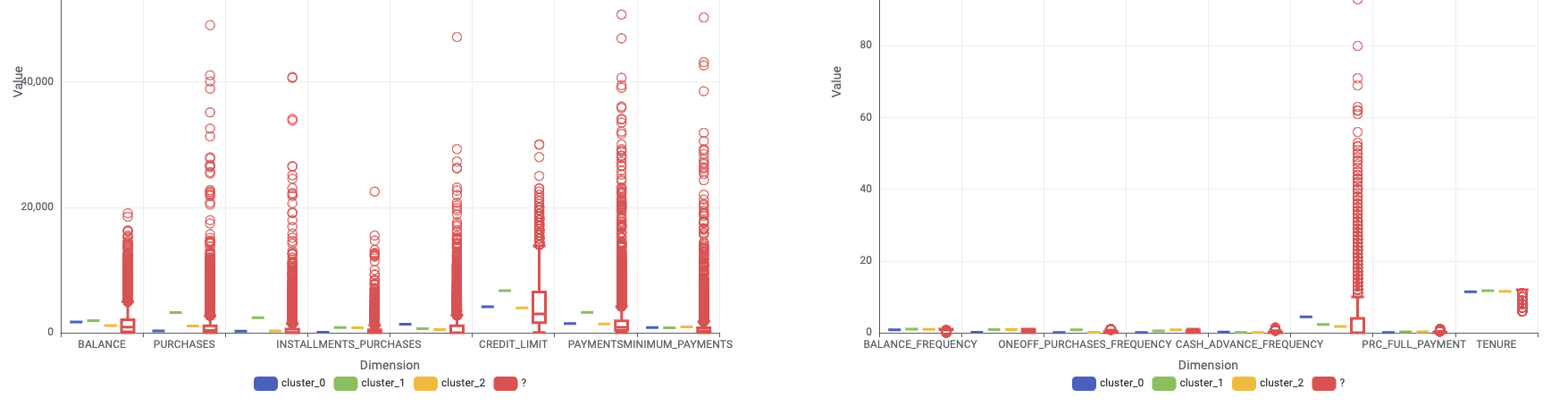
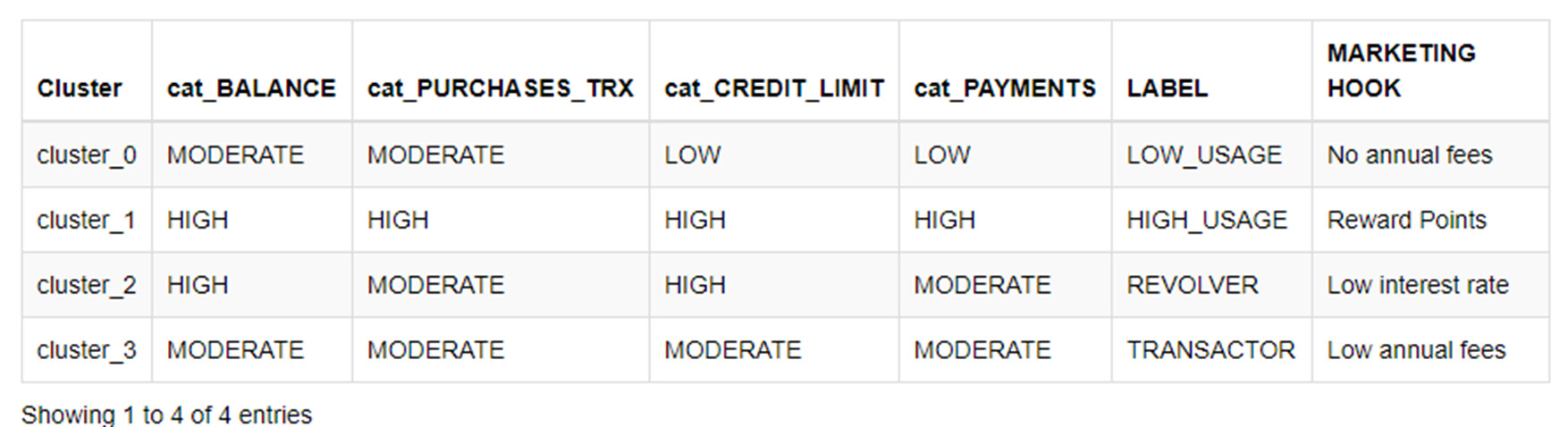
This section discusses the denormalization of the cluster center using the denormalizer node and color-coded identification. Additionally, the categorization of data features are based on size ranges and are illustrated in the two Box Plot.
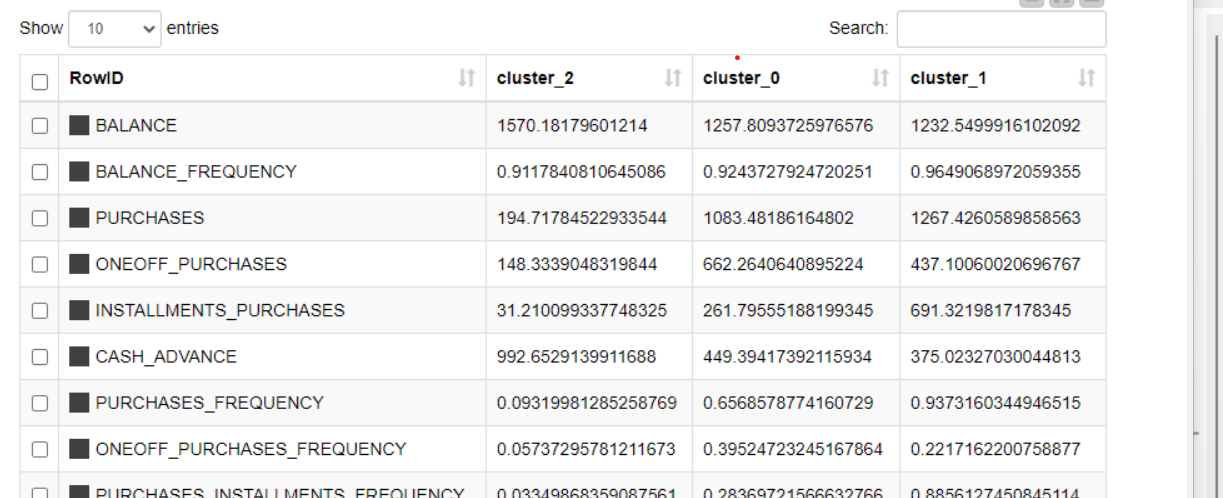
For instance, cluster_0 indicated low purchase and installments, but high cash advance and transactions. In contrast, cluster_1 showcased higher purchase, one-off purchase, balance, credit limit, and payments. Cluster_2, on the other hand, is more average, and requires more in-depth analysis.
The analysis suggests that cluster_0 users primarily use credit cards for cash advances and less frequently for purchases. For credit company, the next step should include methods to encourage credit card use for purchases. On the other hand, cluster_1 features high-value users that require additional features or personalized interests to retain them.
More work needs to be done to refine the analysis, such as exploring features like the balance-to-credit-limit ratio, purchase-to-balance ratio, and employing more advanced clustering algorithms. However, for this challenge, this is sufficient.
I am the author of the second challenge, sorry for the confusion caused by the term “new customers”.
The “new customers” here could be assumed as the customers we keep out during cluster training, this could be done with partitioning node. Use the majority partition to train the data and treat the minority partition as new customers.
Alternatively, I have seen many interesting ways in which you have defined “new customers”, all interpretations are valid.
Hello KNIMErs
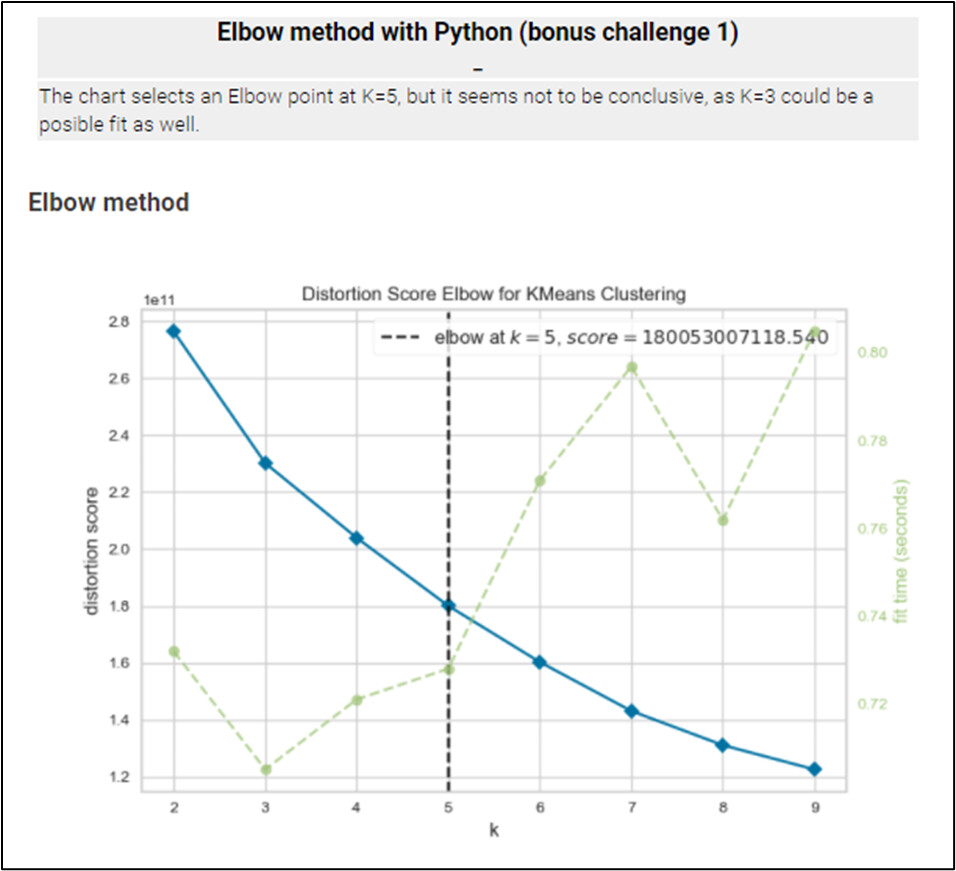
This is my try for the challenge 02. I’ve been playing around with Python, aiming to validate Credit Card company ABC’s decision on K=3 clustering. Elbow and Silhouette Score charts have been tested, however k-Mean clustering applied from KNIME node:
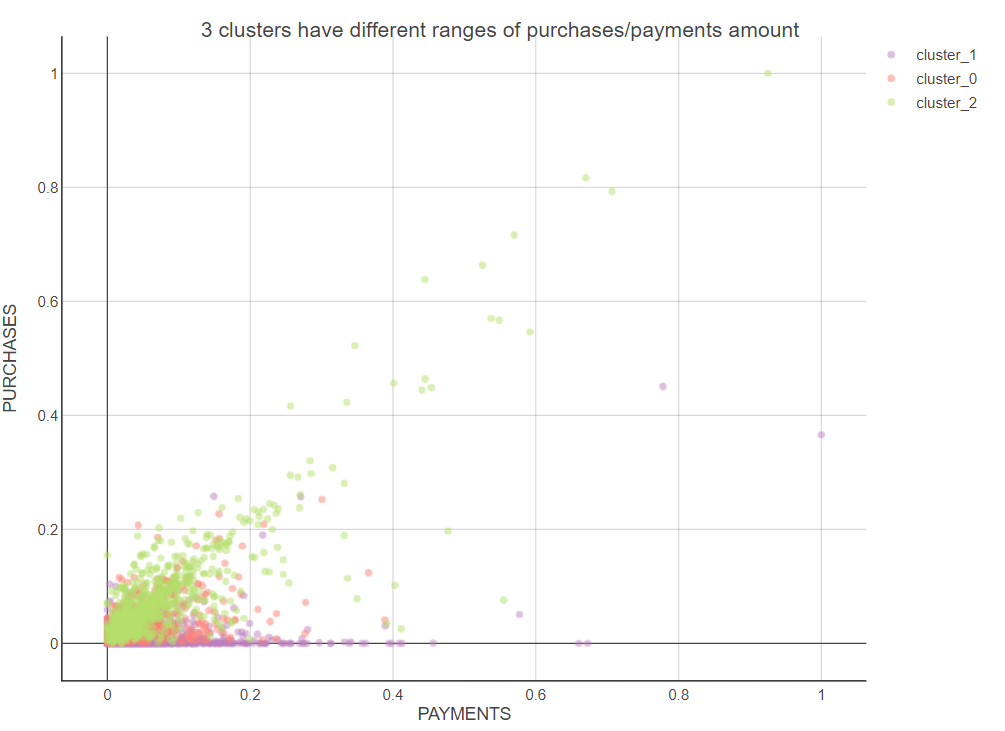
@MoLa_Data Very Nice Solution, but I wanted to know if there is a reason behind scatter plot graph being built on normalized purchases and normalized payments,
In my opinion building the scatter plot on original data with cluster labels can help in us cluster interpretation, let me know what you think.
As always on Tuesdays, here’s our solution to last week’s Just KNIME It! challenge.
As @Mpattadkal mentioned above, different interpretations for “new customers” can be used (that is, what is available as new customer data may vary depending on how you interpret it). We just used a small partition of the given dataset.
I hope you found interesting patterns for the customers in the clusters!
Also: would you folks like to tackle more clustering challenges? Maybe also other applications of unsupervised learning? Let us know!
Thanks for your participation and we’ll see you tomorrow for a new challenge!
Better late than ever. Since i learned a few things i thought i would post my solution as well.
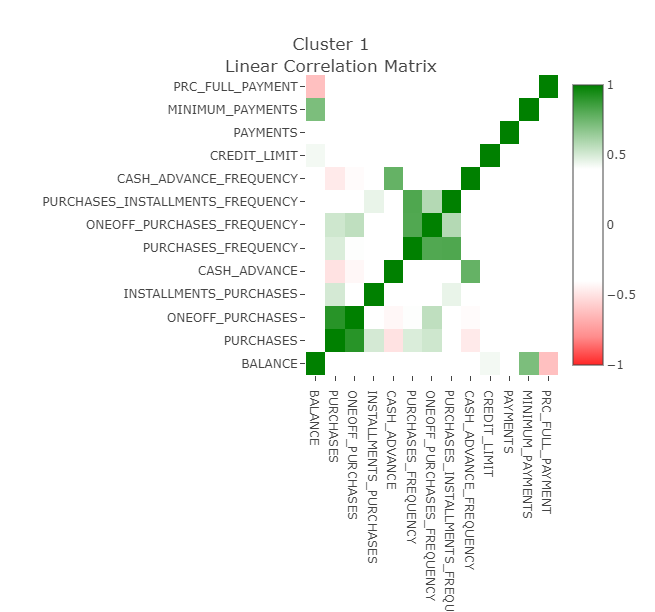
I havent read all the solutions yet, but maybe a distinction is that i used linear correlations to establish trends in each cluster, which were represented in heatmaps: