I would like to know how to use the flow variables in the pivoting node? It is not straightforward to match the standard setting to the flow variable tab. At least, I need to overwrite the aggregation setting - Column to consider.
Hi @gbaudry and welcome to the KNIME community forum,
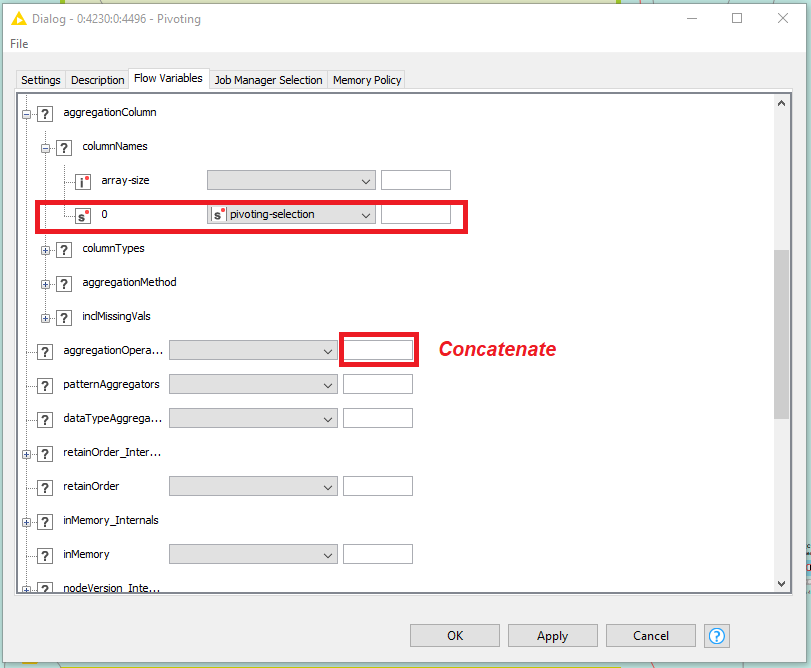
In the Flow Variables tab, you can find “aggregationColumn” category where you can set your desired configurations. Just notice you first need to add any number of columns that you need and then you can change them by flow variables.
For example, if you add a column for aggregation, under the category I mentioned, you can find the index number of 0 for the column for each option like column name. So if you provide a different column name for this index, the aggregation column will be changed.
I am sorry I do not follow your tutorial. I tried your commands but there is always a warning. I created a string flow-variable (which I called pivot-selection):
column1[unit]| colum2[unit]|…
for which the number of columns can change from one country to another (I have a loop per country). So, I want the selection of column to aggregate to be overwritten by the flow variable. My pivot is always the same.
Is this what you were talking about (figure)? Do I have to add the maximum number of columns in the manual aggregation tab even though I am overwriting it? Where do I put the aggregation method? Do I write manually concatenate in the aggregation operator setting cell?
The “pivoting-selection” variable must contain the name of the column on which you want to apply the aggregation method and it can be changed in each iteration of the loop.
Thanks. It clarifies the use of the empty cells that I did not used before, but not the rest. Is there somewhere a flow example to download in which a pivoting node runs on flow variable?
In this example, I have used flow variables to apply “Mean” aggregation on “column1” in the first iteration of the loop, “Concatenate” on “column2” in the second iteration and “First” on the rest.
What I did not get is even though you overwrite the setting, you need to set (in part) the standard manual tab before setting up the flow variable tab.
I see you have added [solved] to the topic title. This is ok but preferred way is to mark reply that helped you as a solution. Solution button is behind 3 dots…