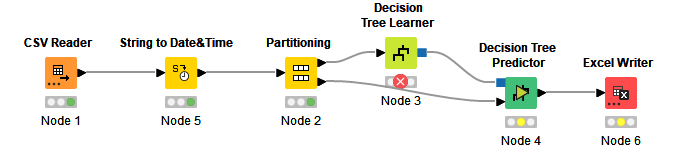
I have bee using both Decision Tree Learner, Predictor and String to Date&Time to predict the time. I have some dates, so that I use the node of String to Date & Time to convert. However, I have three main challenges below:
When I tried to increase the Relative (60% or 70%), it could potentially freeze the program while running the node of Decision Tree Learner.
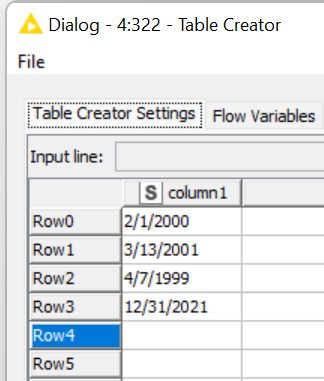
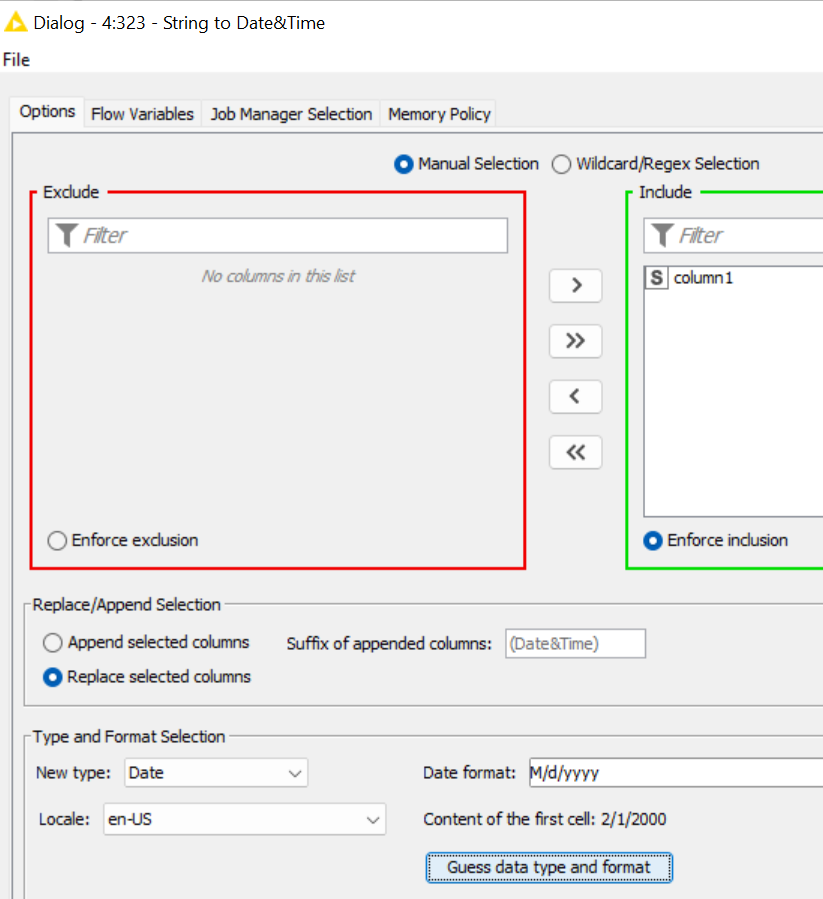
Once I selected “Guess data type and format” in String to Date&Time, it stated that “No suitable format found”. Alternatively, I have manually modified the date format to fit with the date format in the String to Date&Time. Then the error message stated in the console “Execute failed: Failed to parse date in row ‘Row0’: Text ‘2/1/2000’ could not be parsed at index 0”
Whenever the program got frozen there, I had to close the program. When I re-open KNIME, I have to re-configure the relative percentage in the node of Partitioning, the class column of Decision Tree learner, and the maximum number of stored patterns for HiLite-ing
Please let me know if any of you might have some tips or suggestion to share with me. Many thanks a lot in advance.
Could you share some sample data you are using?
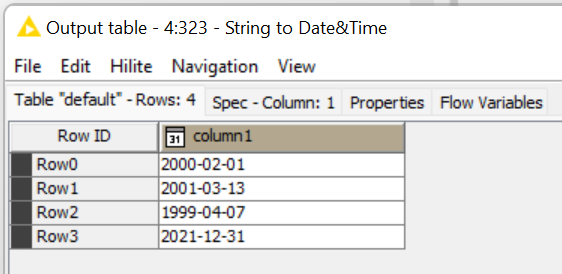
According to your post I have tried out these data type with the String to Date&Time node and it works for me:
Furthermore it is quite hard to answer why your AP is frozen during the execution at this point. It could be wrong settings, or the insufficient memory allocated to your AP.
Could you share more details? Maybe the part of your WF where you are facing this problem?
In the CSV Reader, the input file contains the order number, the order entry date, the order received date, lead time (the days spent from entry date to received date).
I want to predict the new lead time or the new order received date based on these historical data.
If i would select the both “entry date” and “received date” in the String to Date&Time node, i got “WARN Decision Tree Learner 3:3 Class column “Purchase order received date” not found or incompatible” in the console. If I would select only the entry date to be included in the String to Date&Time, then the node is working. It is really strange as both of the dates are in the same format.
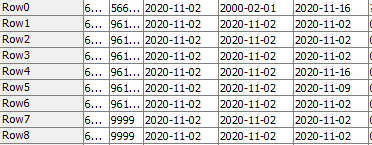
Here are some of my sample data:
If I would select either “entry date” or “received date” in the String to Date&Time node, I would not be able to select it inside Opentions-> General → Class column of the Decision Tree Learner. Also, i might have the message of “ERROR Decision Tree Learner 3:3 Execute failed: Cannot invoke “org.knime.base.node.mine.decisiontree2.model.DecisionTreeNode.getOwnIndex()” because “children[i]” is null” in the console.
The other thing is ‘predicting’ a future date. I do not think just using date variables as targets will do you any good since in the future dates might change. I think you will have to use and predict date/time variables in a relative way. Days-since-today / Days-before-today (or whatever your anchor date is) and prediction in the form of: days-until-next-sale or something. In this case you could try and predict a numeric (regression) value (Machine Learning Meta Collection (with KNIME) – KNIME Hub).
So you would predict the days until the next sale (?) and then derive a date by adding that number to your current (reference) date.
If you just have patters of sales (without further items/variables) you might try and formulate the whole things as a time series problem. You might have to do some research achieving that.
Thank you for your kind suggestion by introducing time series to me. It is really helpful to learn more about the tool.
However, our goal aims for predicting on the time to be spent (lead time) for the further orders. Each order has been placed separately and it is hard to conclude if any certain period could bring more orders place.
We have the historical data, the order number, the item number, the order entry date and the order received date. Using KNIME to predict the new order received dates to compare with the historical received date. We want to see how close they are so that we could know if the model is the right one to predict on the further orders and their receiving dates or lead time.
Can you get my point of trying the model? Do you think if the decision tree should be the right option to achieve the goal?
I believe your use case can be handled with KNIME, you are on the right place.
Speaking of right places, have you already taken a look on our Hub? There are many example workflows even in this topic as well for inspiration. (Here is a list of searching for ‘inventory’ giving an example.)
@ajatal my impression is that you have to put more work into understanding and setting up your data. What information is there that might influence the orders and their timing. Do you have any data about that. Is it seasonal? Would it depend on the customer placing the oder - and so on.
The next thing is the presentation of data to the model. As said before using fixed dates in a model would not make much sense since it would then only work for past data. You might be able to create something like a prefect model for the past which might be entirely useless for further predictions (if this is what you seek).
Maybe you could provide sample data representing your challenge without spelling any secrets. Sometime Kaggle might have a similar case you could adapt.
Thank you for the kind comment. Here is the sample data attached. There are purchase order number, item number, purchase order quantity, the order entry date, receive date, requested date and the lead time. Column G, Lead time is the result that the receive date minus the entry date (G = E - D)
So far I don’t have other data to reflect if the receiving date could be effected by other factors. I need to run a proper model based on these data, except the lead time (Column G) to get the new lead time. To see how the model think about the lead time supposed to be. Then I could compare the new lead time with the old lead time (Column G) to see how close they are. Then i could use this model to predict the further orders. Can you see my point? I don’t see the correlation with the time series or the trend as each order is placed separately. That’s why I chose decision tree.
Please let me know if you might have further suggestion to me. Many thanks in advance.
Regards
Maybe you can gather further data (features) for your model. Based on the screenshot I do not see many options for a model to learn a mapping function
br
as features
** an item number (which might contain additional characteristics you might be able to add or which might be there implicitly if you have enough cases and the items are stable)
** the order quantity (basic correlation might be: smaller quantity = faster execution. Or slower execution - larger orders might be more important and get priority treatment)
There might be some sort of correlation between the items and the quantity ordered if there is any systematic correlation between what that item is and how long it might take to produce/get it. If this is influenced by other factors as well you only might have seasonal information (holidays, weekends) to go with in your current dataset; or you could create features from past orders (have there been similar orders been fulfilled in the -recent- past which might influence the ability to procure the items).
All this will depend on what might influence your production/procurement. You will have to talk to the business people who might know about this. If the ability to produce the items is heavily influenced by outside factors (strikes, shortages with providers/workers, regulations etc.) you could try and get data about that also to enrich you model.
Currently it would seem that this can be formulated as regression problem. The expected quality might very much depend on the conditions mentioned. You might want to upload a sample file - it is hard to work with screenshots
Thank you for sharing your thoughts. I have attached and shared an example file with much example data, as item class stored in the different factory and mode of delivery .Though i don’t think they have much correlation with the lead time. Book2.xlsx (13.0 KB)
Our challenge is that due to the massive data, so far we could not conclude if there are any correlation between the lead time and the quantity or the mode of delivery. So we need to try with the different approaches to see which might predict the new lead time is much closer to the fact.
Please help me have a look and let me know your thoughts.
@ajatal could you explain which columns are features and confirm what column is the target (Lead time). Then you might want to define what role the date variables might play with regards to what I have said about them.
And maybe you try to comment on the remarks I had about your approach. You will have to think about what information your data might be able to provide.
You could of course just try and build a regression model with your data (without the date variables) and target but it might no help you a great deal until you have sorted out your data preparation.
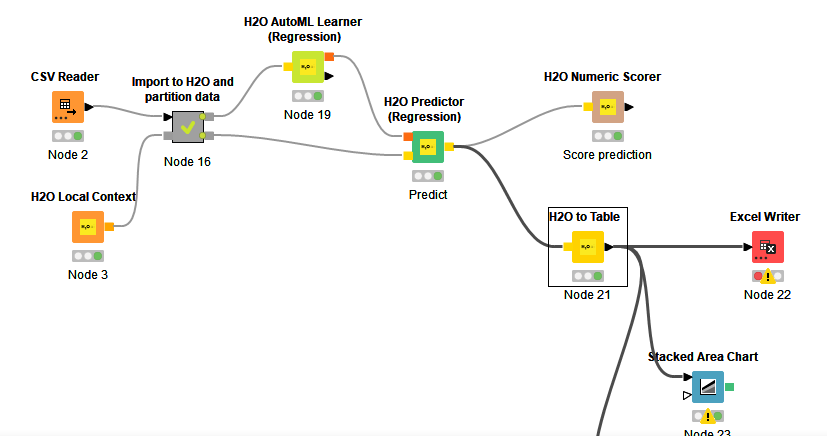
In the node of CSV Reader, I have unselected “limited data scanned” so it should scan the entire data. However, then view the result in the node of H2O to Table, I can see only 1/5 entire data. I checked all the rest nodes but I could not find anywhere else to config in order to view the whole results. Would you mind give me some suggestions to view the entire results?
I haven’t tried AutoML yet. Should I include it into H2O or it is the separate model type?
I assume this would be the 20% test data to validate the model where you would base the statistics on. I would suggest to learn about creating machine learning models in a broader approach so you might see which approaches could work for your business question.