I would like to ask for some help with a text search.
I have some long PDF files in which I would like to search for words.
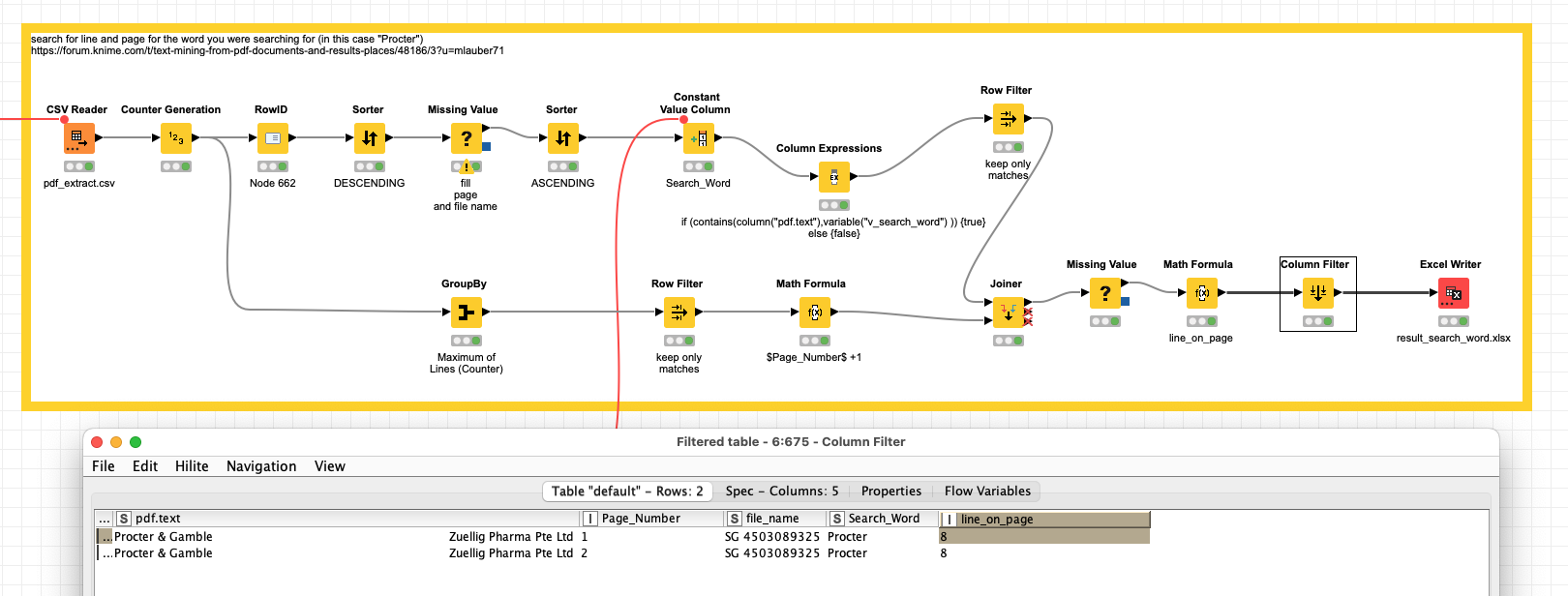
Is there a way to export the places/rows results of the search?
I would like to see which page/row the results are on.
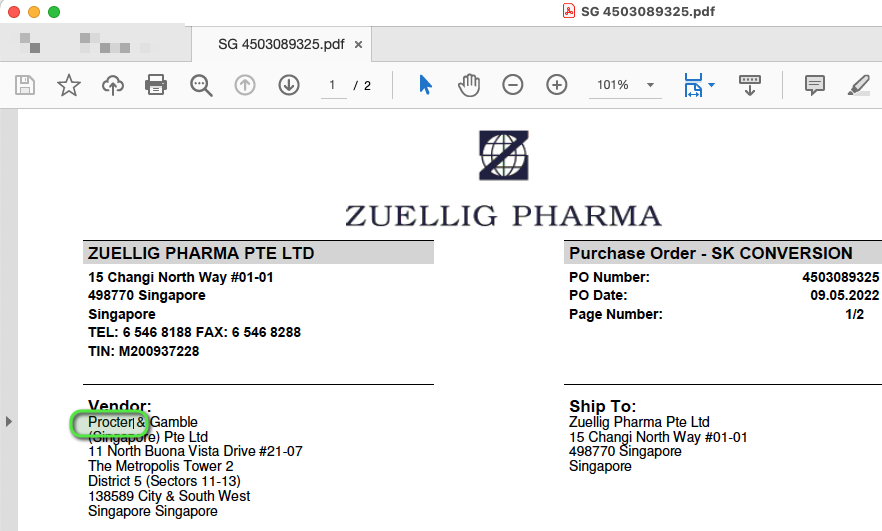
For example, the text I searched for text (like volvo).
And the results will be listed on a different page where I can see which rows of the documents contains that word „volvo” (e.g.: 2. page, 5. page, 13. page etc.)
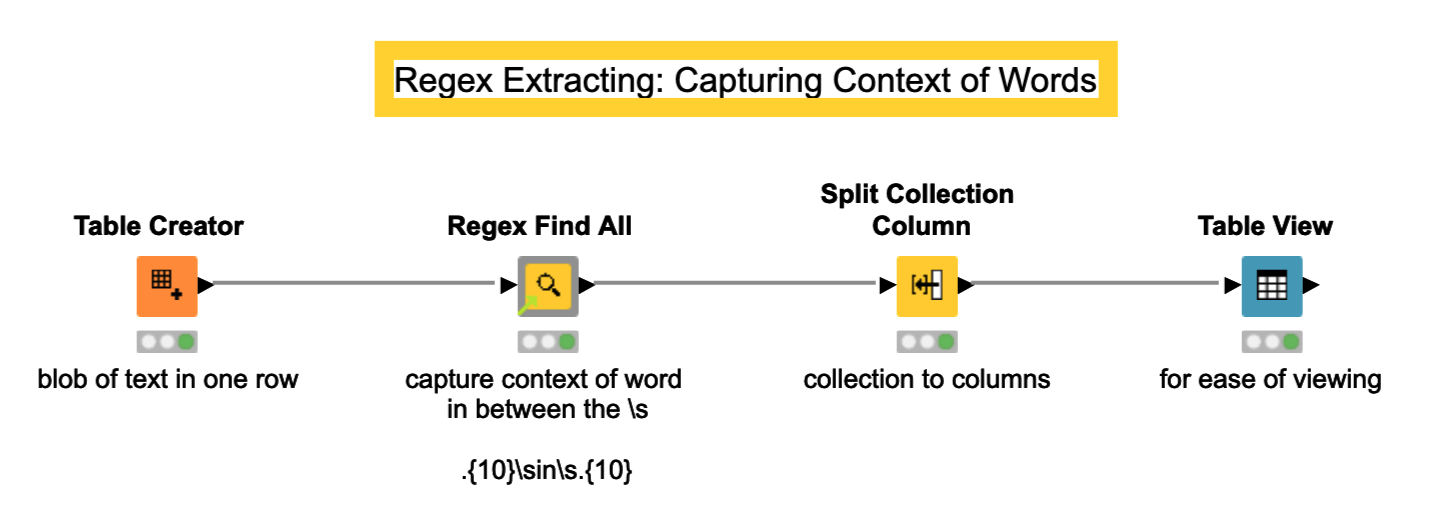
There is no easy way to do that (which I know), but why would you want to do this? Are you trying to see the context in which the word Volvo was used for instance? You could do that with a context window. See the challenge 38 of Just KNIME It to do so.
If you want general information on how to extract from a PDF here is the webinar I ran in August:
I want to do some string manipulation not word embeddings or other text-processing. I just made it up for the challenge like a small lab for string, characters, punctuation and word manipulation etc.,
Thanks for the webinar info.
Thank you for your answer, it was very usful, and I saw the Webinar too.
Thank you.
May I have one more question?
If I have some pdf-s like the sample and I would like to extract text message/call data such as numbers and text.
The call text is located before the text “A jogosult ügy…”.
Whic one cell splitter the best option?