What is read is TSV text (6.2GB).
thanks
Hi @lichang , what kind of error messages do you get? Can you share them?
Knime should be able to read any file size. It’s usually your system that would impose a limitation.
Also, how much memory have you assigned to Knime?
EDIT: If you can also explain a bit what you intend to do with the data, it may help to give you a more precise solution based on what you want to do.
Thank you very much for your reply. I have been busy recently and did not reply in time. My memory was 8GB before, but after trying 32GB it still couldn’t run.
I just want to simply read a piece of data that looks slightly larger, and I haven’t figured out what to do later.
But I thought of a possible method, but I don’t know how to achieve it with knime. If you can help, I will be very grateful to you.
As shown in the screenshot I provided. KNIME can read a certain number of rows at a time for later analysis (for example, 50,000 rows each time), and iterate several times to finish reading, so that it will get rid of the memory limit to a certain extent.
Hi @lichang , based on what you said, I’m assuming you are talking about your system’s memory, correct?
Did you increase the memory allocation to Knime though?
Check your knime.ini file. It’s located in the folder where you installed your Knime.
In the knime.ini file, look for the line that starts with -Xmx, and modify the values there. For example:
-Xmx4000m assigns 4000 MB of RAM
-Xmx4g assigns 4GB of RAM
In your case, you can assign 28-30GB, so change this line to:
-Xmx28g
You may need to restart Knime after that so that the change takes into effect.
Try this and see if it works. Let us know what was the previous value.
Other option would include using Python and read the data in chunks
br
Hi @Daniel_Weikert , Knime can read in chunks without Python 
In the end, it will depend on what’s next. I mean if it’s just reading in chunks to then append to a table, it will come down to the same issue.
But if it’s reading in chunks and processing in chunks to somehow reduce the results, this may work.
@lichang one thing you could try is use a local big data environment and copy the TSV file into the environment and use an external table. In theory Hive should be able to handle very large files. It might be possible to load and then convert / compress the file.
It might take some preparations to do that:
Do you have a small sample of the file that would have the very same structure as your large file and the same encoding?
The next thing to try would be to read the data in chunks and tell the CSV Reader to skip to line number n and only read x lines until the whole file has been imported. I am not sure if the reader internally would try to cache the whole thing or if it could handle such a task. The example is reading from a database but the loop might be adapted:
And then you could see if the simple file reader or file reader could handle the data.
In all these cases you might want to consider that once you have the data in a format that you can read and KNIME might be able to handle you will have to have enough resources to process the file. So you might have to use chunks of the data at once. Here are som additional hints about KNIME and performance:
interesting,
do you have a good sample link (sth free online) to download to test the big data environment. I do not have a file that big and I would like to test myself
br
Hi @Daniel_Weikert , you could generate such a file via Knime using the Data Generator node.
You can generate millions of records using this node and you can then write it to a file.
@Daniel_Weikert you could use a data generator in a loop and append it to a CSV file. The CSV writer has the ability to just append data. But be careful not to overload your hard drive  . Maybe do a rough estimation after a few loops
. Maybe do a rough estimation after a few loops
Thanks for the idea
br
Thank you all for providing a lot of ideas. But in terms of this idea, how should I edit the process
What I want to do is to divide a large file into small files. Each small file contains 100w lines of data. The premise is that knime cannot read the large file directly, only part of it.
So how do you read 100w rows of data from a large file every time and write it into excel?
The first time is the first 100w rows, the second time is the 100-200w rows, and so on. . .
br
Loops like Window Loop might help but I can see that Bruno is already typing a much more detailed solution which will certainly help you
br
As I said, Knime can open files with any size. It’s your system that is limiting it. There were a few questions and suggestions that were made regarding your memory allocation. Did you try them? You mentioned that you increased the size of memory of your system, but I then asked if you also increased the allocation of memory to Knime? With 32GB, you should easily be able to open a 6.2GB file.
Is that a requirement, or is this your workaround because you cannot open a big file? Try to assign the proper amount of memory to your Knime, it should work.
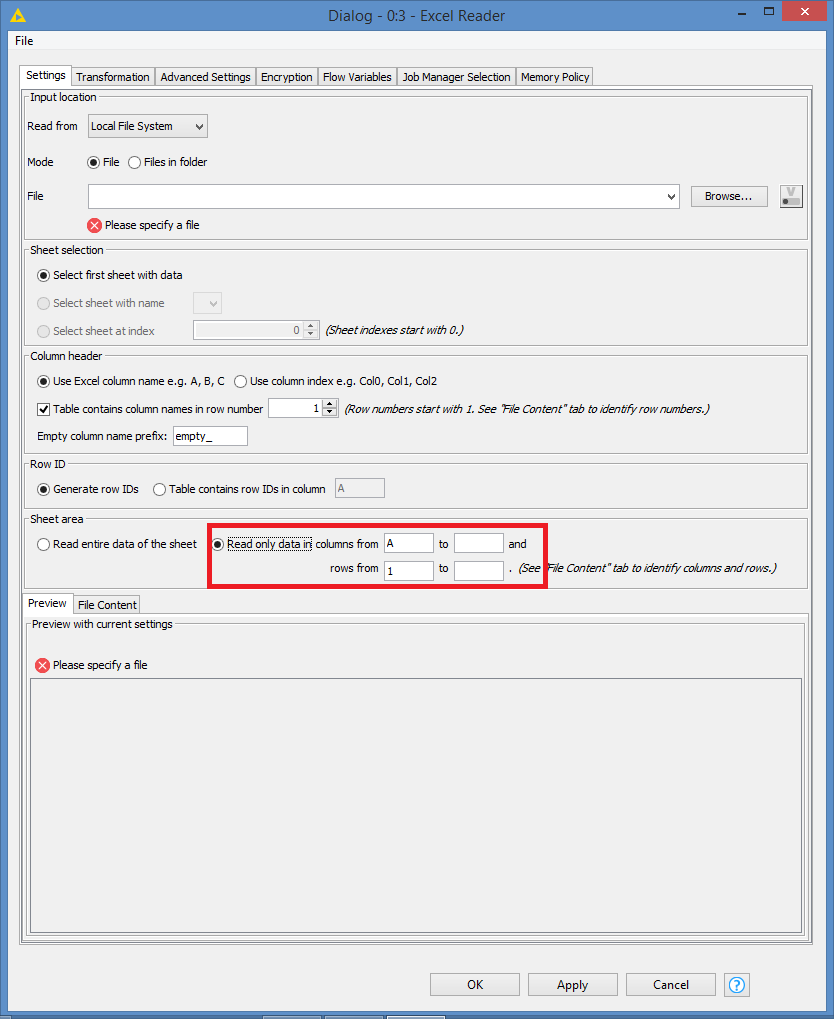
Regardless, it’s also good to know how to partially read a file. The Excel Reader allows you to read from a start row to an end row, so you can partially read an Excel file:
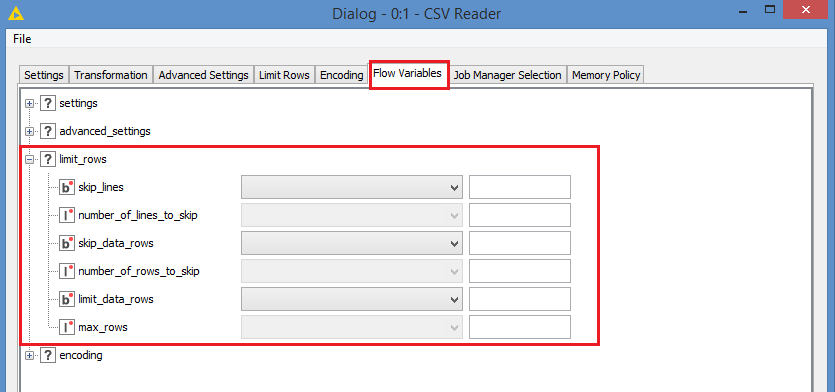
The CSV Reader and the File Reader also both allow you to read a file partially by setting parameters in the Limit Rows tab:
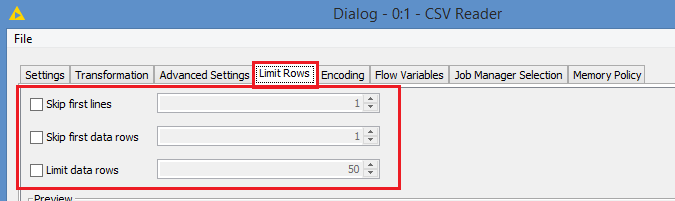
And of course, as always in Knime, any setting you can set manually can be controlled by a variable dynamically, and so for all these settings, you can set the values dynamically in the Flow Variables tab:
I’m not sure what the “w” means in 100w or 200w (and by the way, if you do 100w rows, the second time it will be (100w+1) to 200w rows), but to keep it simple, let’s say we have a file containing 20 records and I want to read 5 lines at a time.
That means it should read:
1: 1-5 rows
2: 6-10 rows
3: 11-15 rows
4: 16-20 rows
Do you see a pattern here?
Rows to read: 5
Starting rows of every run: ((run-1) x 5) + 1
The good thing is that when you run this in a loop, Knime will give you what is the currentIteration is, and since iteration number starts with 0, in reality, this is what you will get:
Iteration | rows read
0 | 1-5
1 | 6-10
2 | 11-15
3 | 16-20
So, to get the starting row of each iteration, you can just use ($currentIteration$ * 5) + 1, meaning if you want to know how many rows to skip for each iteration, it’s just $currentIteration$ * 5, of course where 5 is the number of rows you want to read, so in reality, the proper formula would be:
Rows to skip: $currentIteration$ * $rows_per_batch$
Thanks for the confidence @Daniel_Weikert lol 
Regardless of the loop chosen or implemented, the partial read would still be done via the Limit rows
One thing I’ve noticed though is that there does not seem a way to append to an Excel sheet.
You can write to the same Excel file, but in a new sheet. You can overwrite a sheet, but you cannot append to it.
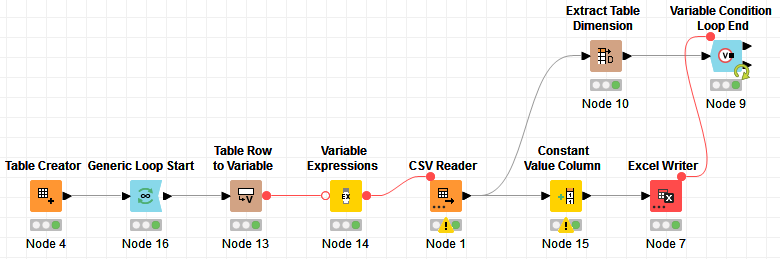
I put something together quickly, but I’m writing to different sheets at the moment. Workflow looks like this:
Since we don’t know how many times we need to loop, I start with a Generic Loop Start, but I know I should stop once we have reached the end of the file, and we know that it is the last batch when the batch size is less than the number of rows per batch.
For a proper test, I add the iteration to the data.
A side note here: @ScottF , there seems to be a bug in the Constant Value Column. I tried adding knime’s currentIteration variable as an int:
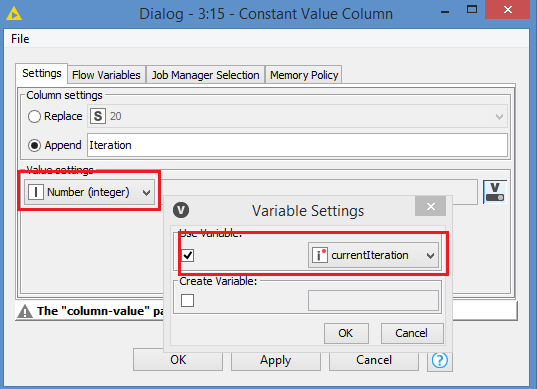
it complains:
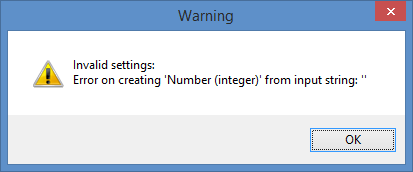
Somehow, it’s seeing the currentIteration variable as a String. It does not complain when I add it as a string:
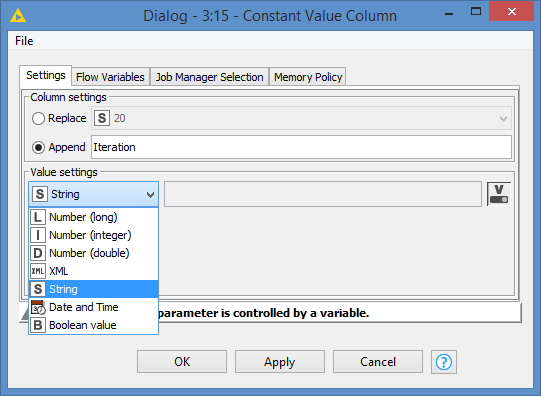
==== END of Side Note ====
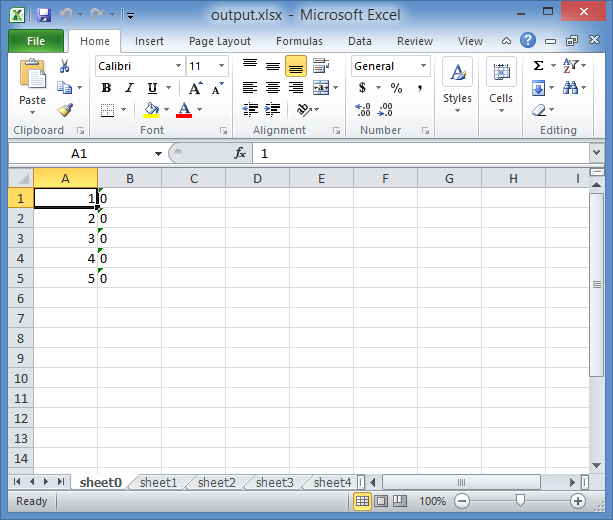
Continuing with the explanation, here’s what the Excel file looks like:
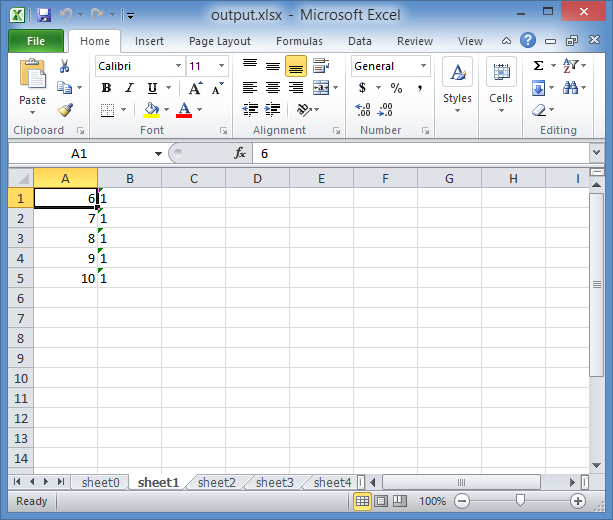
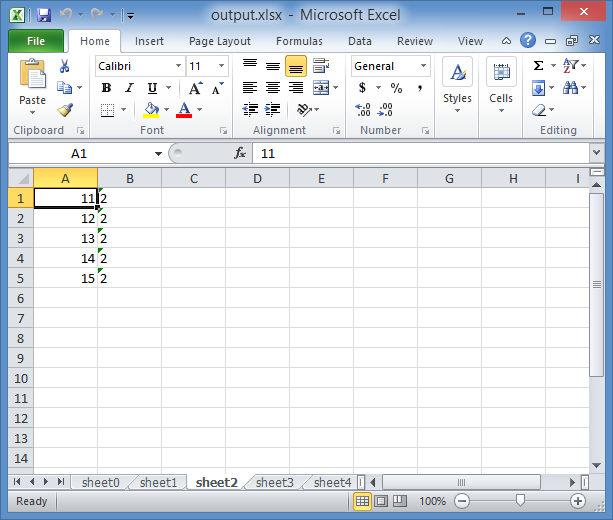
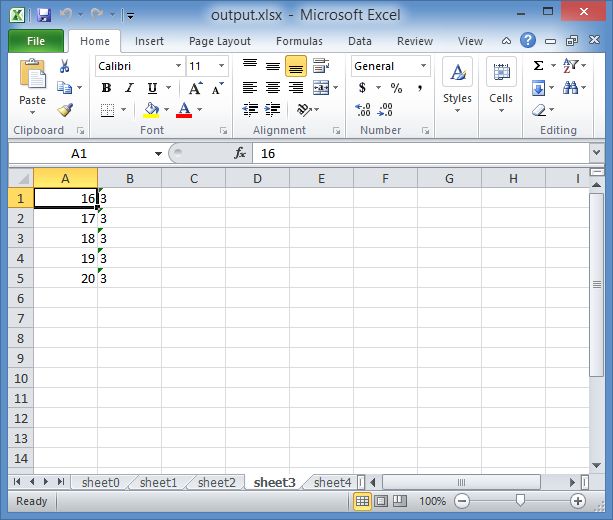
(So the Iteration was written as a string as you can see from the screenshot, because of what I explained in the Side note above)
As you can see, it read only 5 rows each time.
If someone can point out how to append to the same sheet, that would be helpful.
In the mean time, here’s the workflow (sample file included, and it will write to the data folder): CSV read only a few lines at a time.knwf (26.8 KB)
thanks
Best wishes to you and thank you for your continued response.
It seems that the best way is to expand the memory.
br
And “w” is the first letter of Chinese “万(ten thousand)”
br
I have applied the method mentioned, whether it is a loop or a read-only part, you need to have enough memory. This is the premise.
If a device is not capable of reading a large file completely, all methods seem to be ineffective.
Thanks again to everyone who helped.
br
Hello @bruno29a,
seems Scott is successfully ignoring you ![]()
About your side node it’s a bit hard to believe you didn’t come across this issue/design yet. You can find explanation here (not only related to Constant Value Column node):
Br,
Ivan