Hi @Gavin_Attard,
I tried a few tests based on my previous optimization approaches and might have found some odd behavior I currently struggle to explain. First off, I assume I have a decent and optimized system:
- AMD Ryzen 7950X (16 Cores, 32 Threads) - delited for direct die mount!
- 64 GB Corsair Vengance DD5 6400 CL32 (EXPO Enabled)
- Primry SSD: SanDisc Extreme Pro 1TB (MLC) - Trim enabled
- WD Black SN770 - Trim enabled
- Window: Power Mode “High Performance”, Knime whiltelisted under Security
- Knime: Up to date,
-xmx50g&Dknime.compress.io=falseas well as column sorage to max performance (see this post)
The PCI Lanes of the mobo are directly attached to the CPU sparing RTT through the chipset. Therefore, SSD, CPU or RAM throughput are unlikely a bottleneck. I did extensive stability and perf testing when I setup my new PC to ensure thermal throtteling is limiting me only at the least possible moment.
I noticed (sample workflow attached with 10 million rows), that neither are CPU, nor memory nor the SSD are in any kind of way utilized to a reasonable amount. For whatever reason knime ran in efficiency mode (I disabled that from the beginning) so I enabled and disabled it again.
Neither of the following appraoches do work in a slightest way. The rwo filter only approach takes for ever and never finishes while CPU, Memory, Disks etc. are barely using their pinky. Streamlining did not made a change so I left that out.
Only Row Filter

Chunk + Row Filter
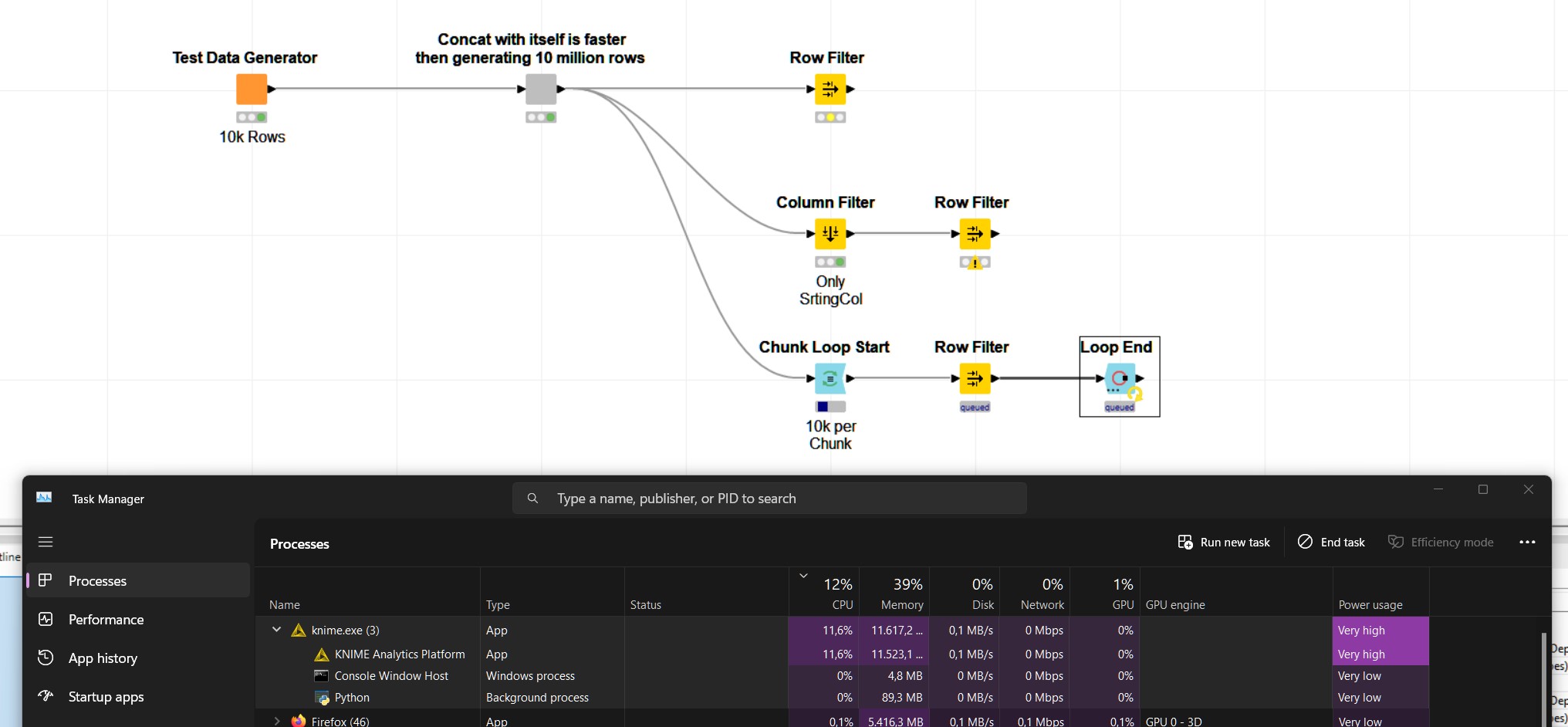
Parallel + Chunk + Row Filter
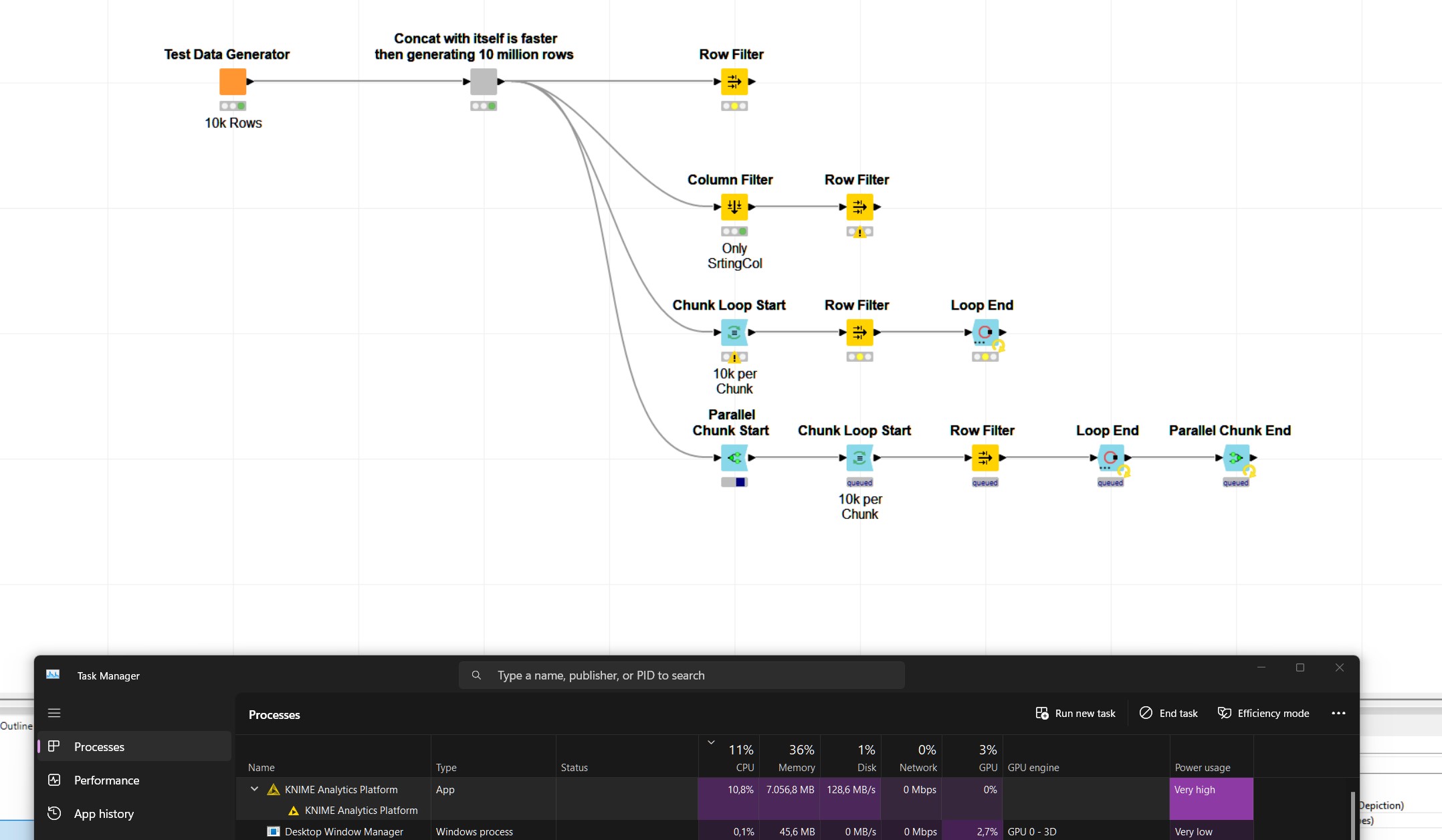
This is feels highly unusual. During the data generation of the following sample workflow CPU and memory spike to about 10 % of my overall capacity. When saving the data to put some stress on my SSD I see a considerably higher throughput which seem to indicate the nodes in the sample workflow might not be optimized for parallelism.
Data Generation
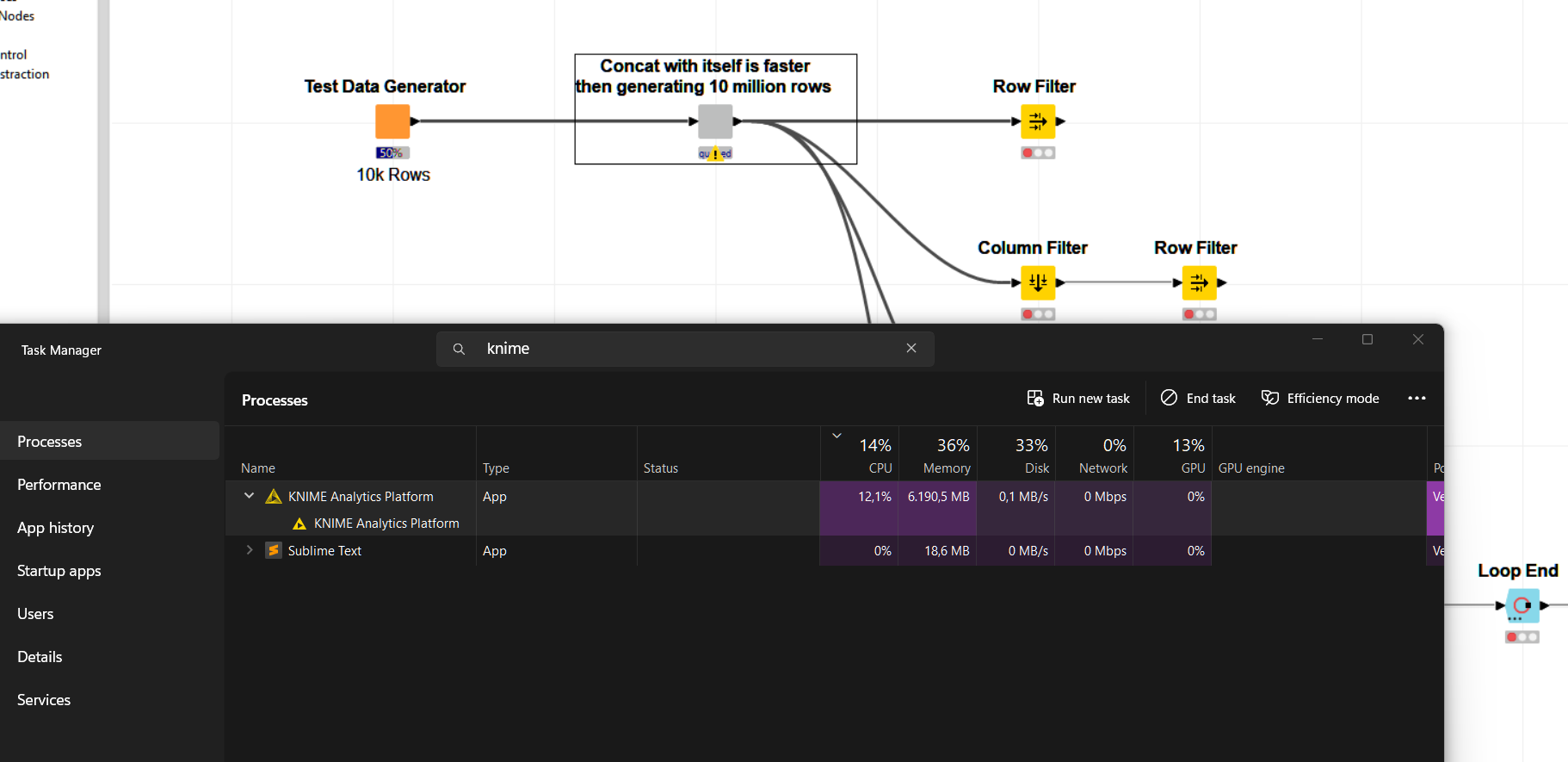
Saving Temp Data
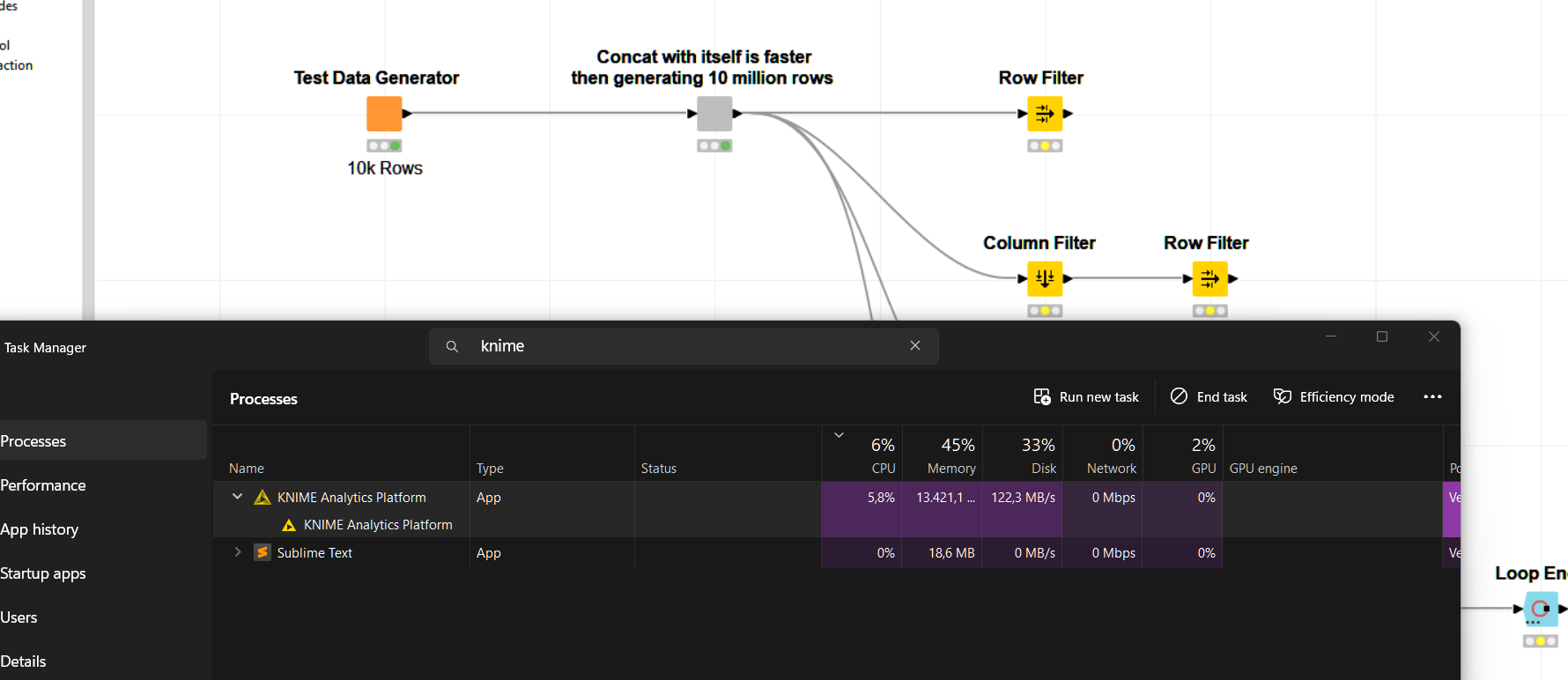
Sample Workflow
Best
Mike