I tried a few tests based on my previous optimization approaches and might have found some odd behavior I currently struggle to explain. First off, I assume I have a decent and optimized system:
AMD Ryzen 7950X (16 Cores, 32 Threads) - delited for direct die mount!
Primry SSD: SanDisc Extreme Pro 1TB (MLC) - Trim enabled
WD Black SN770 - Trim enabled
Window: Power Mode “High Performance”, Knime whiltelisted under Security
Knime: Up to date, -xmx50g & Dknime.compress.io=false as well as column sorage to max performance (see this post)
The PCI Lanes of the mobo are directly attached to the CPU sparing RTT through the chipset. Therefore, SSD, CPU or RAM throughput are unlikely a bottleneck. I did extensive stability and perf testing when I setup my new PC to ensure thermal throtteling is limiting me only at the least possible moment.
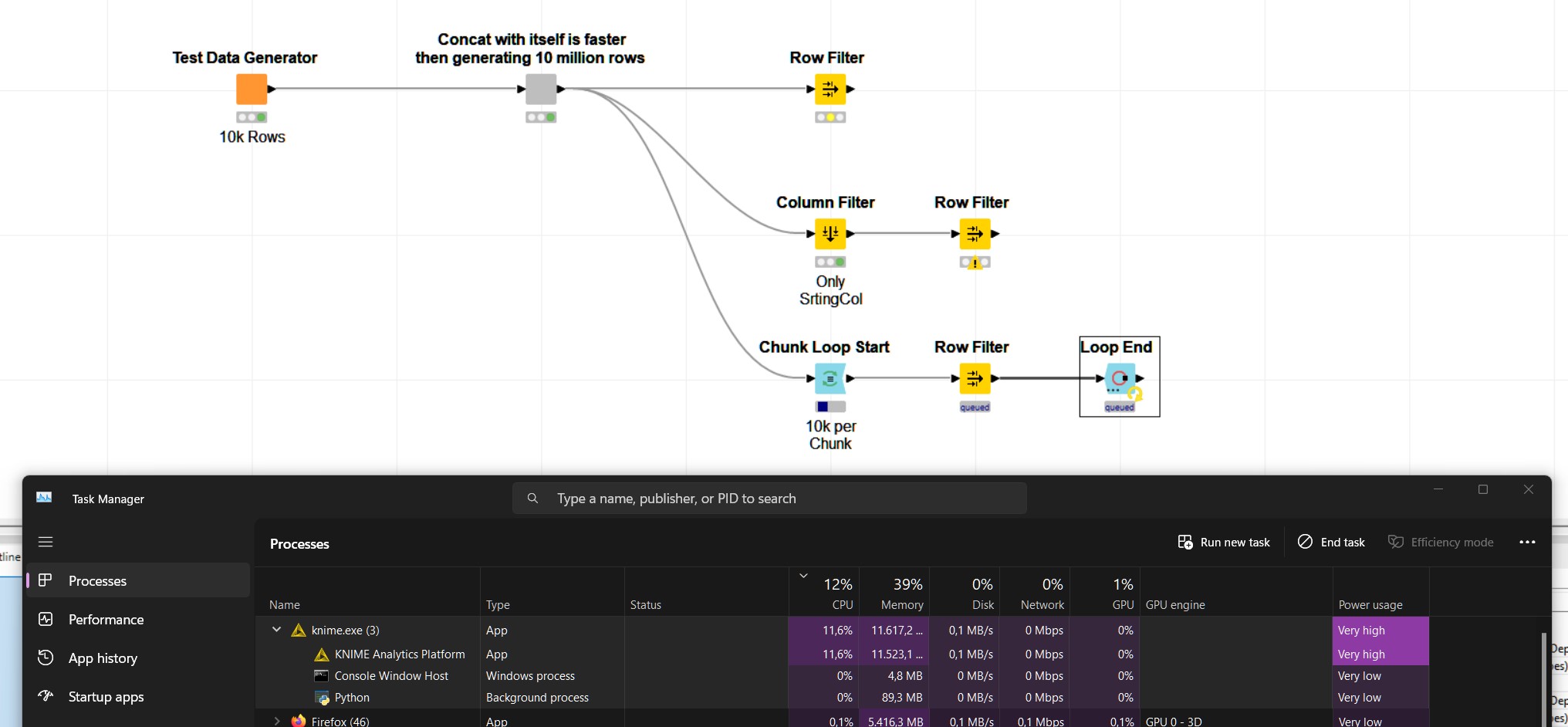
I noticed (sample workflow attached with 10 million rows), that neither are CPU, nor memory nor the SSD are in any kind of way utilized to a reasonable amount. For whatever reason knime ran in efficiency mode (I disabled that from the beginning) so I enabled and disabled it again.
Neither of the following appraoches do work in a slightest way. The rwo filter only approach takes for ever and never finishes while CPU, Memory, Disks etc. are barely using their pinky. Streamlining did not made a change so I left that out.
This is feels highly unusual. During the data generation of the following sample workflow CPU and memory spike to about 10 % of my overall capacity. When saving the data to put some stress on my SSD I see a considerably higher throughput which seem to indicate the nodes in the sample workflow might not be optimized for parallelism.
You are welcome. Dknime.compress.io=false prevents compression which is usually CPU straining. Though, the data got to be computed first which ideally happens entirely in the memory. However, if either saving the nodes results or more data is moved from memory to the swap on the disk, this back and forth can further dampen efficiency.
I could consistently reproduce the very poor disk read / write speed with any approach using the Row Filter node. Breaking the data down in smaller chunks does not improve anything as the “partitioning” takes too much time.
I just had the idea that simply dropping rows might be more efficient than filtering. It seems that this is a feasible approach as filtering is happening significantly faster and CPU as well as Disk and Memory actually get utilized.
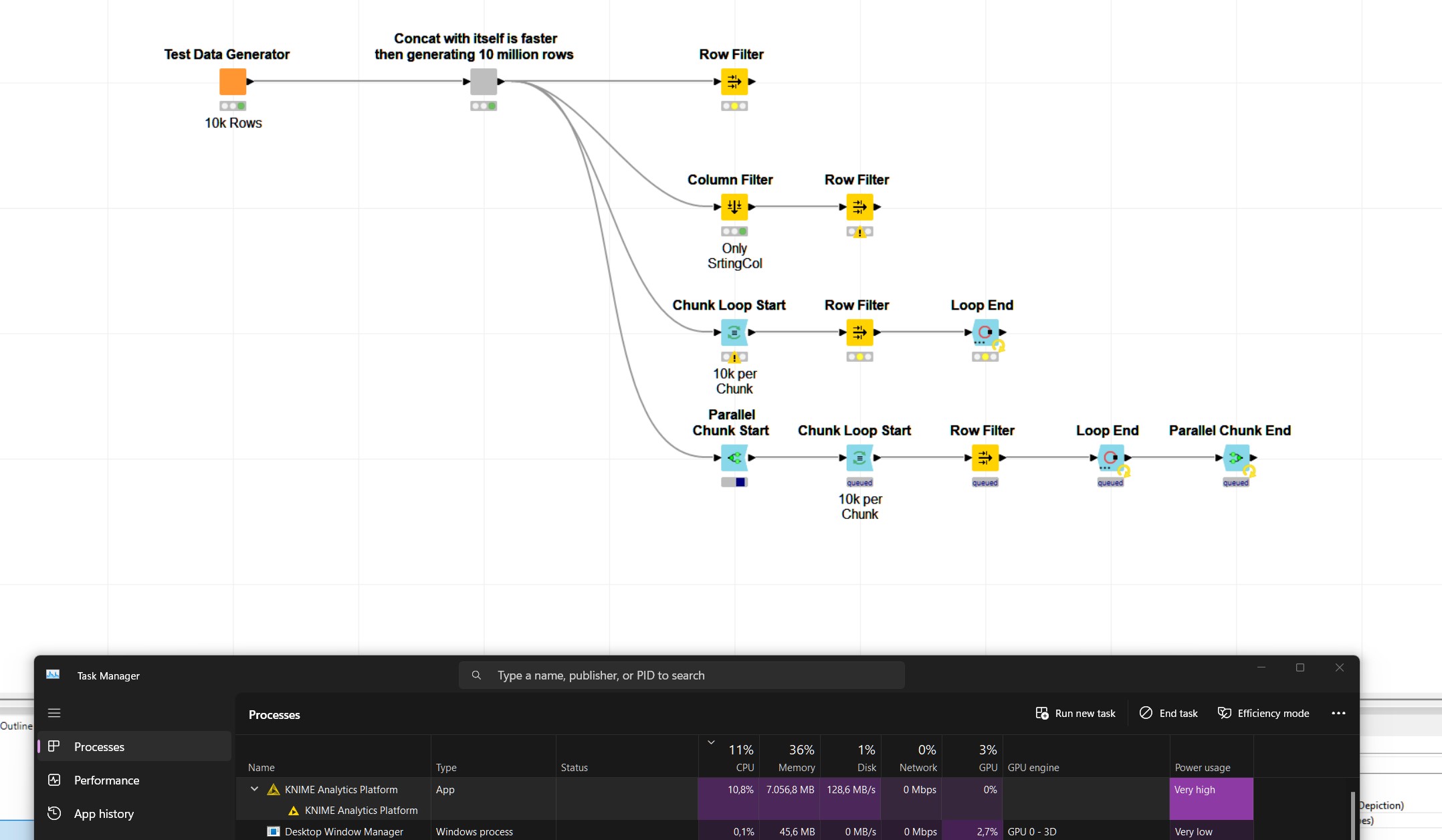
That reminded me of an approach to, with each iteration, subsequentally fillter less and less by using the Recourseive Loops. I am just giving this a few more thoughts and tries.
Update
That idea doesn’t work. The furhter the Row Filter, or Row Splitter progresses filtering the date, the slower it becomes. First it starts rather fast advancing to 10-15 % in a matter of seconds but considerably slows down after 20 %. It took a couple of minutes to advance from 25 to 27 %.
For whatever reason I see lots of continuous disk IO despite memory bit being fully leveraged. Iäve got to give this some thoughts in regards to parallelism.
I am baffled. Once when I worked with >20-30 million rows when analyzing logs from firewalls, containing way beyond hundrets of columns with request parameters, cookies and values, Knime had little to no struggles crunching that data (on a Mac Booke Pro back form 2016 with a mere 16 GB of memory).
Unfortunately that time is two years in the past and I moved to other challanges, so I do not have access to that data to check for possible regressions.
That appraoch with the recoursive loop to process less and less data with each iteration I leveraged before on millions of rows. This time Knime seems to not be able to cope with the data. Even if I only use one column of strings with a rule engine just doing TRUE => $$ROWINDEX$$, the node seems stuck at 1 % for a minute or more.
I have tried that as well. The RowID Node took about five minutes to reach 3 %. When / with which version was the new data storage framework introduced and is there anything documented what that change means? I thought I followed the changes closely but cannot recall to have read anything about the storage engine.
I think you have to activate the “KNIME Columnar Table Backend” - it might be a default after a certain version - not sure.
It is based o Apache Arrow format which also is being used to communicate better with the Python nodes - although often you would work with Pandas dataframes there and then convert them to Arrow.
Especially in the beginning I experienced some problems with the framework especially when it came to Loops and Chunks and the like - without always being able to exactly pin that down. Same with this task. At one point there was an error with the RowID node - but the next time it disappeared.
Another option for such tasks might be to store the data in a Parquet file in Chunks, then do the filtering over those physically stored chunks and then store the results. Parquet would not hold all the data types that KNIME table does though.
Though, the new one seems to have significantly increased resource utilization (Disk Throughput increased three times) but it not necessarily improved the efficiency as Row FIlter or RowID take pretty much ages to advance just a few percent.
“Fun” but confusing fact … after switch back to the default settings and retried the RowID node, it was substentially faster while only leveraging systems ressoruces to very low percentages. Doesn’t this behavior feel counter intuitive indicating a possible bug? Two minutes into applying the new row IDs the node already passed the 20 % threshold (whihc it never did before).
I too thought of saving the data in another format, maybe a file and use external tools such as a bash command but that would defy the purpose of Knime fur such a mundane task.
i need to set this up Knime native if you like. No python.
I can’t split columns, as well it’s the nature of the task.
For info here is what i am doing.
We are getting data from the GA4 Big Query table.
GA4 has no fixed event schema for events, it’s whatever the business or implementer did.
What i need to do is unpack the event params which come with the events (these could be anything from 10-15 cols all the way up to 150+, indeed theoretically it’s near limitless).
Then for each event determine which params are populating, then run some top level validations on the them such as % null, values and counts etc…
So, i can’t separate the cols as i don’t know what i need to keep for each event.
one more, and please don’t take this as me shitting on Knime, far from it.
I got a trial alteryx licence to compare perf.
I’ll start with the good thing with Knime, connecting to BQ was super easy and quick. Alteryx… well i gave up as i dint have the time to faff around…
after writing the dataset to CSV i popped it into Alteryx to build in there.
OMG, the speed difference is chalk and cheese. Alteryx was writing to disk at phenomenal speeds while Knime for some reason was either throttling at 6Mb or at most 30
Row Splitter (i used filter in Alteryx) took minutes to filter through the same data while Alteryx shredded it in 6 seconds.
There is no comparison when doing grouping or pivoting, nothing i did in alteyx took more than a min for the same data set.
So i want to return to my original question. Is this just Knime performance? or are there some secret/hidden settings that we need to configure in knime to make this work.
again folks, the comparisons are on the same machine.
I have 64GB Ram of which at least 30Gb is dedicated to Knime
I have a super fast SSD (Alteryx was chucking 100+ Mbs) while Knime seems throttled at 6 or up to 30 (and thats only when writing a file)
The csv file size is the same file size for both Knime and Alteryx
resetting row ids had no effect, i am on old data storage as the chunk loops have not been optimised yet for the new storage type.
I was re-reading the thread to see if there were any more ideas i could try that i missed and came across your post. Thanks so much for trying and verifying this performance issue.
I took remember it being faster, which is why my surprise.
@knime any clues from your end? This seems pretty significant.
About Knimes Read/Write throughput. In one if my previous screenshots it managed to exceed 300 MB / sec. over a prolonged period if time.
However, adding to my statement:
“Fun” but confusing fact … after switch back to the default settings and retried the RowID node, it was substentially faster while only leveraging systems ressoruces to very low percentages.
The node never finished even after hours so I had to abort.
Generally speaking, I believe many share the same (perceived / recalled) experience of a degraded performance.
To be blunt, knime has always been rather slow and doing things say in Python will often be a lot faster in execution, less so in development time. A workflow that has to run often, regularly and has to be performant with millions of rows, yes I will openly question if KNIME is the right tool. Airflow, dagster etc. they exist for a reason.
If all of the potential workaround don’t help or are not possible it’s a simple case of wrong tool for the job with all the downsides of that.
Apologies for not chiming in earlier. This is a loooong topic… Thanks so much for sharing your observations and also for the suggestions @denisfi, @kienerj, @mlauber71 and @mwiegand!
In general, we are aware that some nodes in KNIME do not offer optimal performance. However, your findings are not what we’d expect. There are a few statements that are somewhat confusing, which we should clarify:
While both the KNIME Columnar Backend and the “Parquet” option in the “default” (row-based) KNIME table backend rely on technology from Apache, they are different things.
The option to store KNIME tables in the “default” (row-based) backend in Apache Parquet files only changes the underlying file storage.
The KNIME Columnar Backend uses Apache Arrow underneath and is a complete rewrite of the data handling framework in KNIME. This means KNIME uses a columnar memory layout throughout all processing and offers a lot of performance benefits (incl, e.g. zero copy to Python processes).
You mentioned that you observed KNIME to have been faster in the past. Could you please clarify? Which KNIME AP versions are you referring to, was this using the Columnar Backend or not?
Constantly improving the performance is high on our priority list, e.g. for the upcoming KNIME AP 5.1 release we have added the option to read CSV files in parallel (it does then read at 100+MB/s) and improved the columnar backend. There are a more performance topics that we have planned for the next release (still this year) incl. looking at individual node performances and data encoding.
It’s hard to make 1-to-1 comparisons as Alteryx uses a stream processing engine, but KNIME should not be multiple times slower, especially not in simple cases like filtering rows as stated in the original post.
@Gavin_Attard would you be able to share the workflow so that we can analyze it in more detail?
Are the workflows by @mwiegand (thanks!) representative for the issue you are seeing?