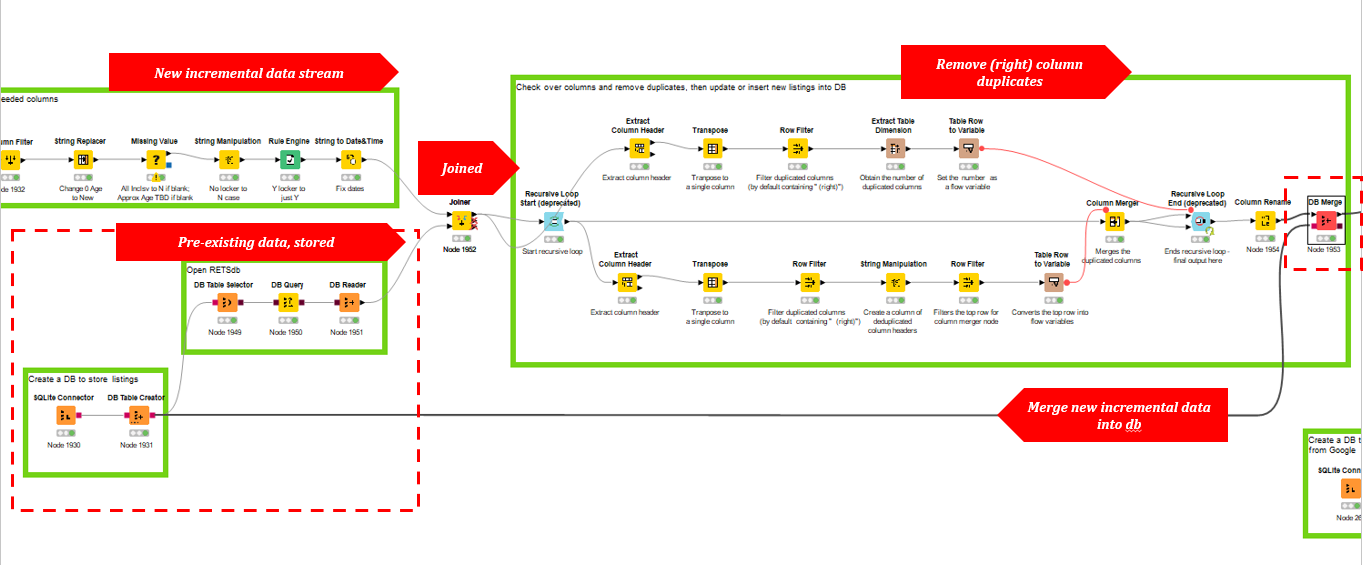
I have a workflow that is working nicely in taking a stream of incremental data, transforming it, and then merging it with the DB Merge node to a SQLite DB Table that contains previously-pulled incremental data. Let’s call this Table One. It’s a great table. An excerpt of the workflow:
The dataset itself is a table of active real estate listings. However, a listing throughout its lifecycle will have price updates (seller decides to up/lower the list price), or other changes (new comments, updated dimensions, etc.). Each listing has a unique ID, called Listing Number, and I came to appreciate that I need a new table, which we should call Table Two.
Table Two, not yet created in any part of the workflow, should be a sort of “change tracker table” for every Listing Number. That way, I can pull up any Listing Number, and see all the changes that have happened. The native data set does include an “Updated Timestamp”. So Table Two could look like:
@qdmt glad you liked the previous hints. You could just setup a SQLite database that would collect all the entries where you can then select the latest one per Listing with the use of a Windows/Rank function (the current driver bundled with KNIME would allow this function). The latest results (per Listing) will then be stored in a new table my_tracking_table_02.
The key in this case is to set up the SQLite table so that it will have an automated PRIMARY KEY and an automated TIMESTAMP. The other columns are dynamically constructed from the sample file with the help of a KNIME Flow Variable (v_sql_string2).
CREATE TABLE IF NOT EXISTS `my_tracking_table_01` (
ID INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL
, $${Sv_sql_string2}$$
, my_Timestamp DATETIME DEFAULT CURRENT_TIMESTAMP NOT NULL
)
This is also like big data systems handle their data operations: just append all data and then select the latest one. You might have to check can handle the volume. Maybe you have to use one database per month/quarter/year. And also think about backups.
Thanks very much @mlauber71 - made this my Sunday project and thought I almost cracked it, but ended up spinning my wheels for a good portion of the day and made a good mess of things (my fault). So if I may, I’d like to share a version of the workflow prior to starting with a historical table.
To recap, this workflow checks a folder for the most recent CSV (for the purpose of a shareable workflow, a “Table Creator” node has a sample dataset), does some cleaning, then merges it or inserts new rows into the SQLite database. This database is essentially the “latest row” of any given ML Number (i.e., the “Listing” ID described above). The “Updated” column is the timestamp that represents when the ML Number has been updated. Note that the CSV-producing client could have overlap of data (can set to produce incremental or overlapping).
Tried to replicate or do something similar to what you had done above, but then thought to at least try some minor changes by simultaneously sending to the current DB Merge node as well as another DB Writer/Insert node that sends to a new, Historical table based on some ML Number/Updated keypair, and then from there, do the ranking. Thought this would also give the added benefit of keeping the main (latest update only table) running fast, while the historical table being accessed separately only when required. Spun wheels here.
Will let it be and step away for now - but any tips or even quick fixes to this would be super appreciated.
@qdmt I like your spirit to crack this thing. What you might want to keep in mind: best to make some sort of plan what your workflow should do. In the previous approach there were examples about H2 and UPDATE functions. Also there is an example where only new lines or the ones that have changed are being inserted
In this thread we used SQLite and just appended data like in a Big Data environment and automatically assign IDs and TIMESTAMPS. All this approaches have their benefits. You might want to think about.
H2 and SQLite are both great standalone platforms. SQLite might be a little bit more ‘stable’ but also has fewer functions. H2 is more advanced but I do not have that much information about how it behaves with large sizes.
In theory you could also use a (local) big data environment where you would have the data as single parquet files and manage them (1, 2, 3).
H2 do an UPDATE on the server using a VIEW of the existing and the new data
MERGE an existing database and insert new rows with H2 - use the Northwind DB
Example of H2 database - handling of database structure and use of Primary Keys - insert only new lines by ID
Getting shaped into a database journeyman here! Been re-reading through all your write-ups. Extremely helpful.
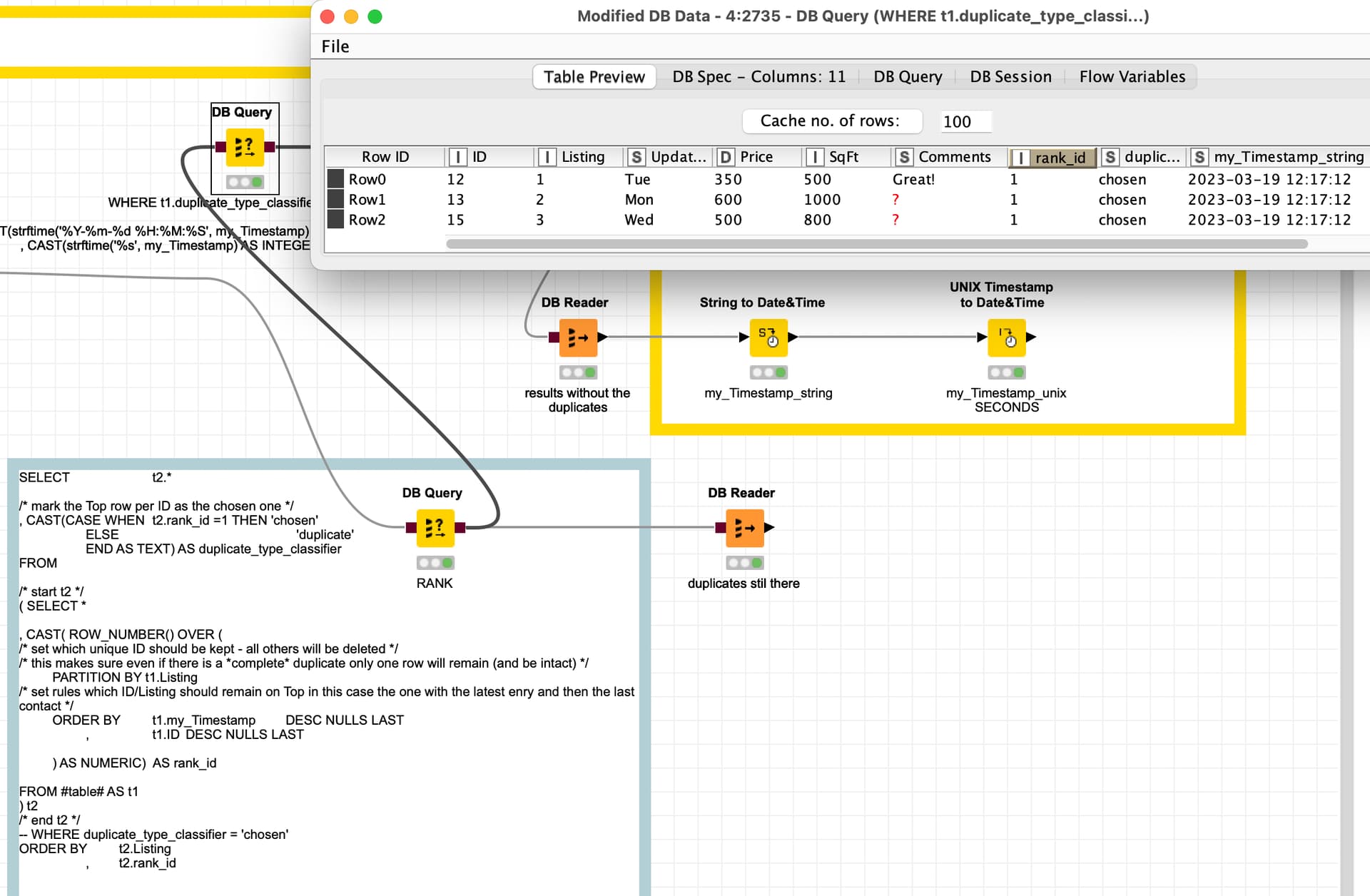
So I think I cracked it, still need to QC, but generally, what I did was simple:
The first DB Merge node in my workflow needs to have two WHERE columns: ID and the timestamp.
This allows for all “update rows” of a given ID’s rows to be kept. Before, I only had the ID column specified, so the Update timestamp was being overwritten, and thus I only had the latest instance of any row.
Then, perform Rank similar to your approach described above, and send only the latest instance to the “latest price” DB table.
Send everything else, including the latest row, to another “historical” table.
I’ll keep testing as more data comes in over the next few days, and if all looks good will do a more detailed writeup on the overall workflow.