I have a workflow that imports in real estate listings, runs transformations, and sends off to a cloud visualization platform.
While this works great on a single-CSV basis, the nature of source data (active real estate listings) is such that the data can be updated everyday (list price changes, information added, etc.), or, new listings can appear entirely.
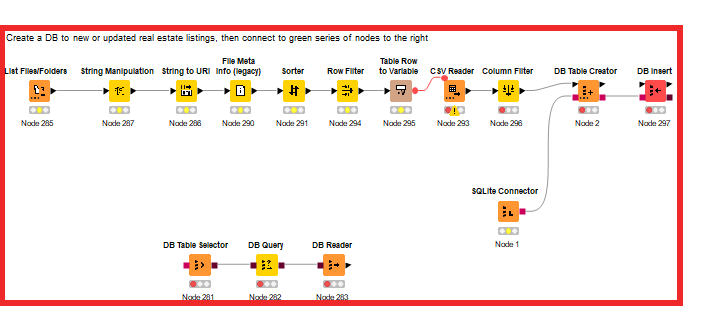
I presume the most efficient way to do this would be to use List Files/Folders and DB nodes to continuously add or update new rows into a workflow-local SQLite database, and then run the transformations. I’ve tried the following image, but got stuck and could use some pointers - this part of KNIME is still a grey area for me:
I’ve also attached a sample workflow. The nodes in the red box are what I’m trying to resolve. The nodes in yellow contain two sample “pulls” of data. You can imagine that the data would be pulled weekly and a new CSV would be generated each time. The nodes in green are working great.
One caveat: the ML Number column is the KeyID of the listing - so no two listings would share the same ML Number. If a listing at the same address has a different ML Number, it’s a new / different sale. If a row is entirely identical, and appears in a new data pull, then no update has been made, but if a row contains some updated column but still shares the ML Number from a previous pull, then the listing has received some updated information (i.e., the list price was dropped).
@qdmt I might be able to take a look at your example later. In the meantime you might want to explore these examples - although they use H2 standalone database:
Thanks again for sharing - took a good crack at trying to adapt the H2-oriented workflow, but got stuck.
The H2 workflow is interesting in that it loops within the workflow every 10s to query the same database, whereas in my case, the “loop” takes place at workflow execution with the List Files/Folders set of nodes at the start that pull the latest file in a folder to update or create new entries in the database. So where in the H2 workflow there are “write” and “update” node streams, I think the spirit of my adapting the workflow was trying to consider that the same “write” operation could be either an update or write. Not sure if that makes sense.
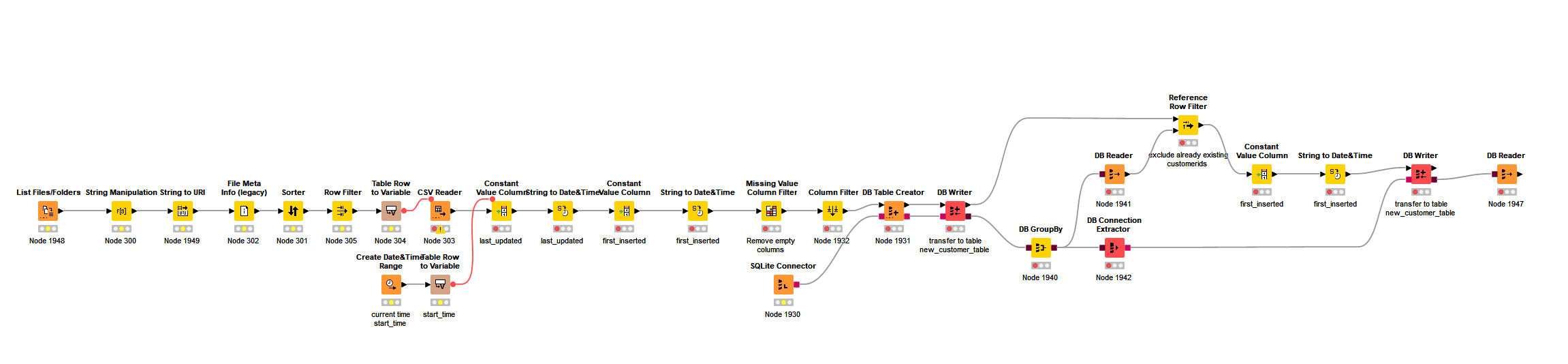
Here’s an overview of the attempt so far, using many of the same nodes in the H2 flow:
I went back and re-reviewed the KNIME manual/guide on all of the DB nodes, and I believe I have solved this by just using the DB Merge node. Such as:
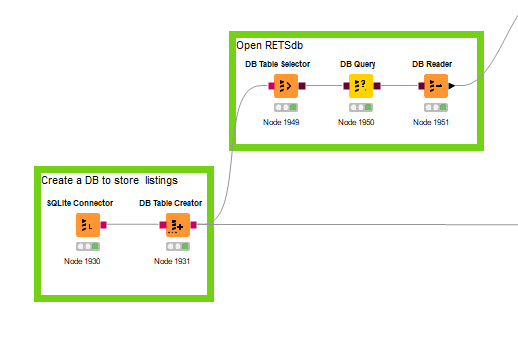
First create the DB, query, and read it:
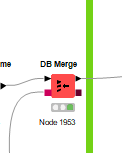
Then merge in new or update new rows:
My overall workflow is quite large, and I still have further QC’ing of the data to do. I’ll look to do a write-up of the solution in case it is helpful.
The 10 seconds is just there to simulate changes and have everything in one sample workflow. Also you could try and use this to semi-automate sich a thing, like checking every few minutes. In a real live scenario you could just let it run when you want or expect a change. There is also a node that would wait for a change but that might not be practical to keep the workflow open all the time.
Unfortunately the source of the data at the moment comes from another client program that produces the CSVs incrementally. However, that program does indeed run on a schedule, and I do believe I can run some kind of Windows-based automation to open the workflow and run it routinely.
There is another initiative I’m exploring to bypass that and use a python node within KNIME to make calls to the server in the same way that the 3rd party program does. This would eliminate the CSVs at least!