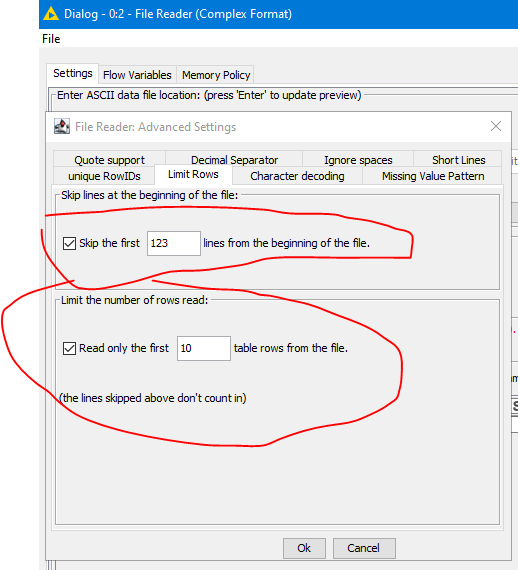
Hi, I have used File reader (complex) before (in a loop) and it worked for me fine when all the files in the loop had stuff to be read at the same position within the files. I used this option:
However now I have filers that have simillar structure, but stuff I need to read from them ( again used in a loop) is not at the same position. Here is example of the file
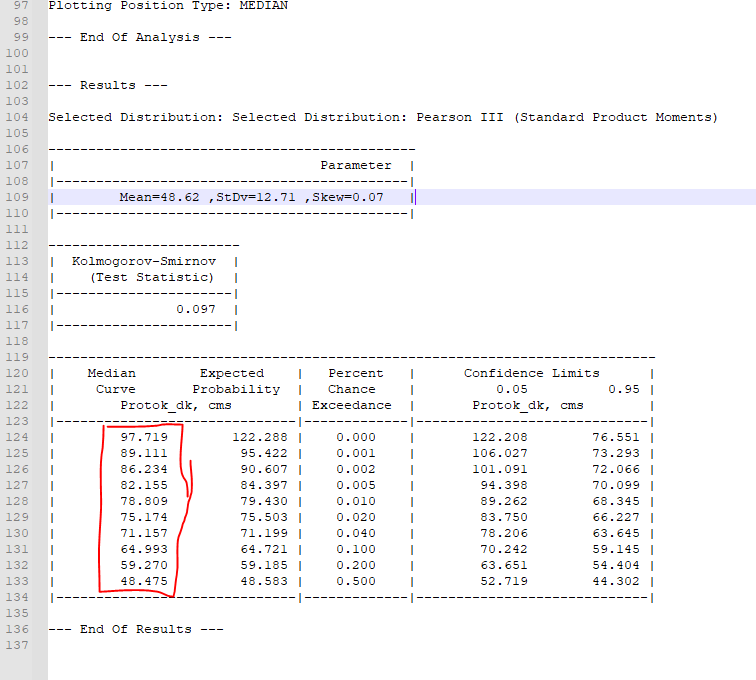
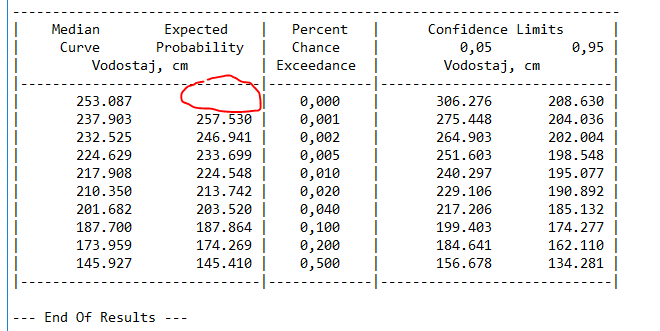
I need to read the red framed values. But in this example its rows 124-133, and in some other file in the loop these values will be maybe rows 119-128, etc… Each file its somewhat different position.
Here is what knime Hub says about the node
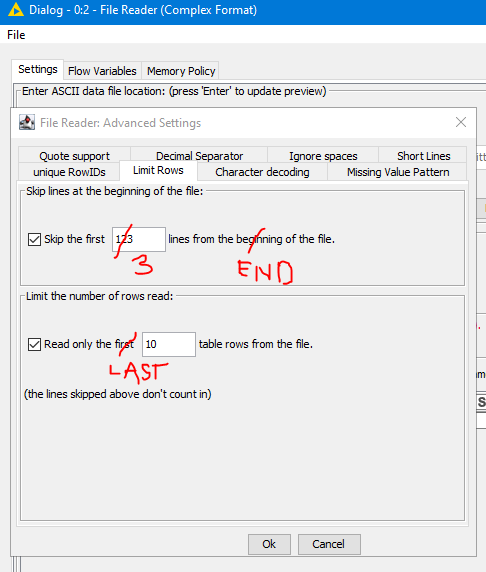
Can someone please suggest alternative node or is there a way to anchor reading the set of values not from the top, but from the bottom of the file. Like this for instance?
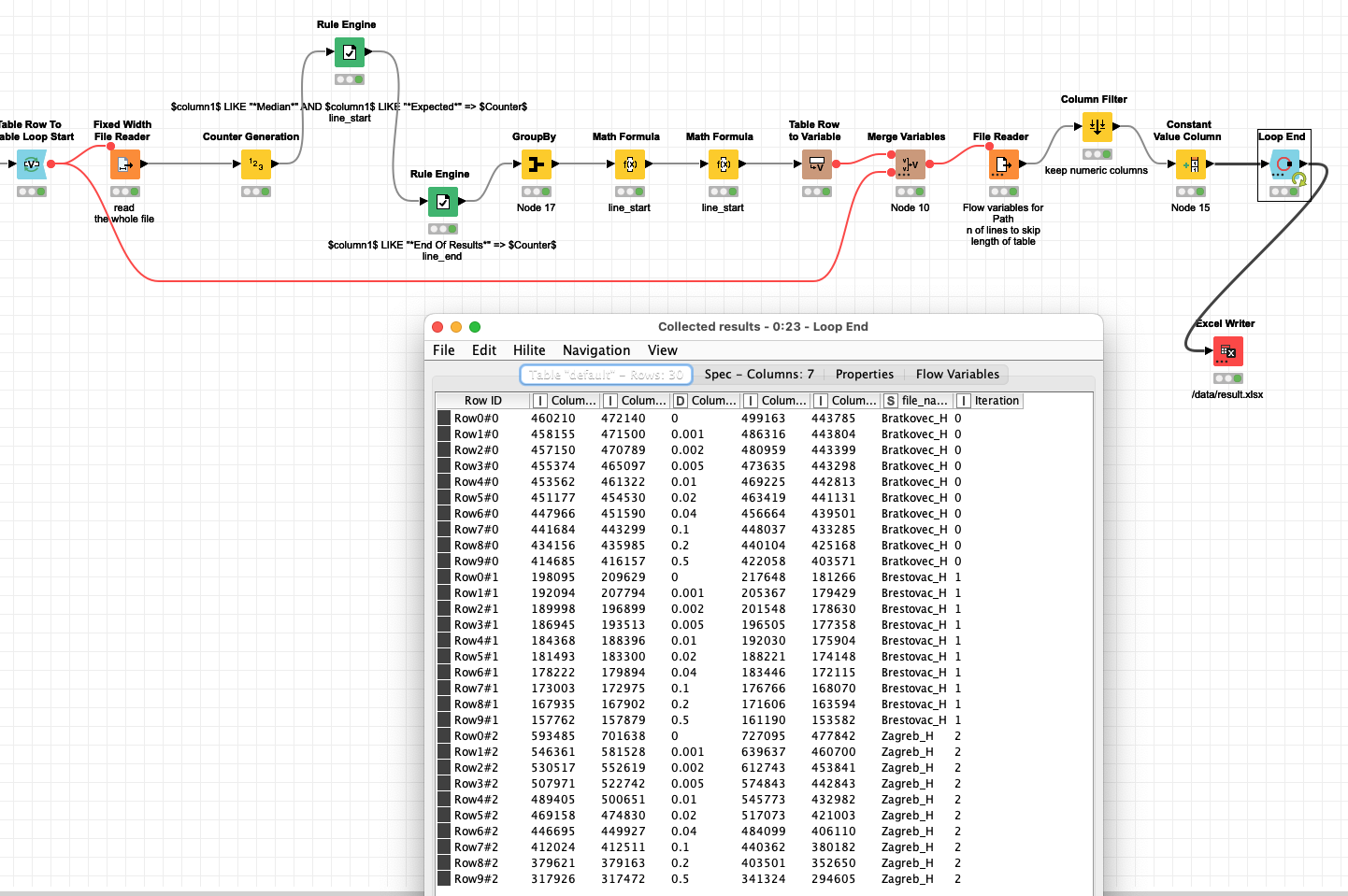
@Dalmatino16 you could try and first read the file where all the data from one line would be within one cell. Then identify points where the data tabel starts and ends
line where “Median” or “Protok_dk” is found plus 4 (or 2 or whatever)
line where “End of Results” is found minus 3 (or 4) as end
A math formula might then determine the lines to be skipped and the number of lines.
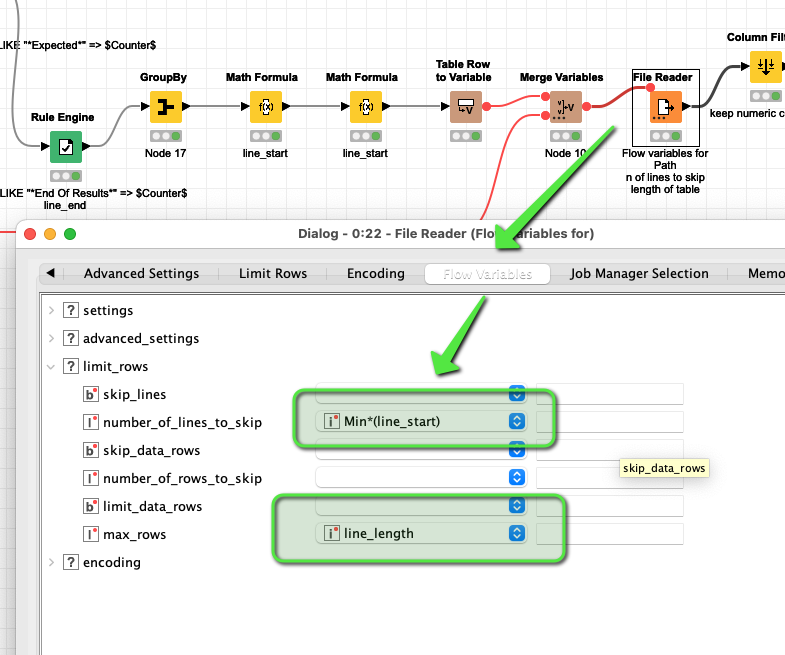
Then bring them als flow variables to your file reader. If you must you could further identify the first and last line with a number in within the block you have defined above.
@Dalmatino16 with the help of the Counter Generation you could give the lines numbers.
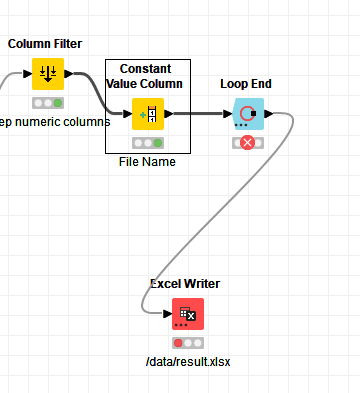
Then you could use the Rule engine to save the number of the line if a certain condition is met and store the line in a separate column (var_start, var_end). Then only keep those columns and use a math node to calculate the start and length. Then convert that into Flow Variables that you can then use to steer your File import.
A somewhat similar example:
You mabye could upload 3 or 4 examples with varying table starts that would represent your task. Then someone might have a look.
Thanks, I am going to try follow the instructions you provided. In the meantime, here are several examples.
All that I need to extract is 10 values from the column between “Median curve” and “End of results” at the end of the files.
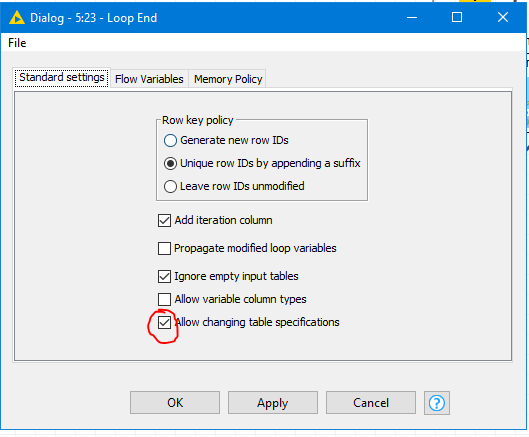
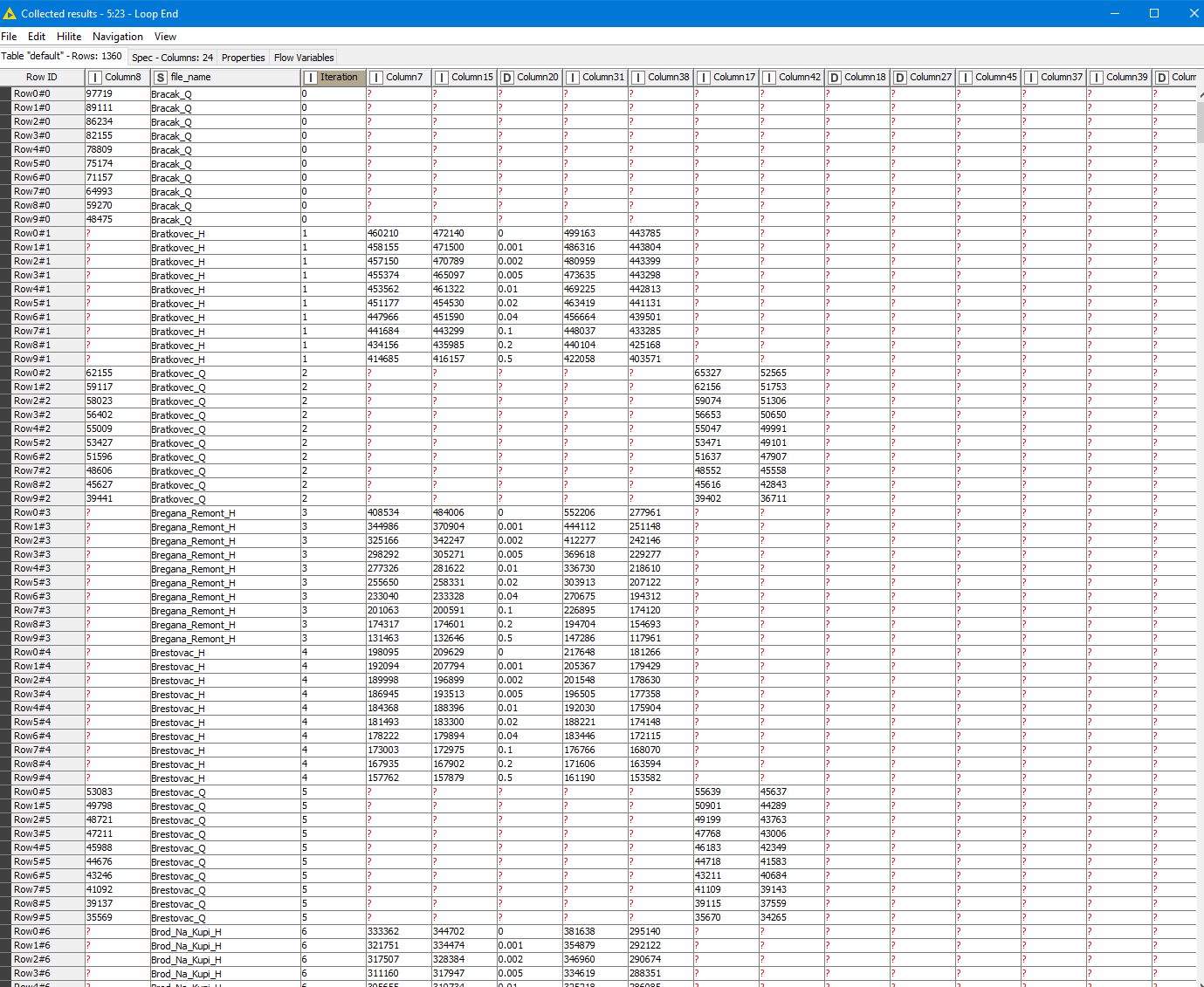
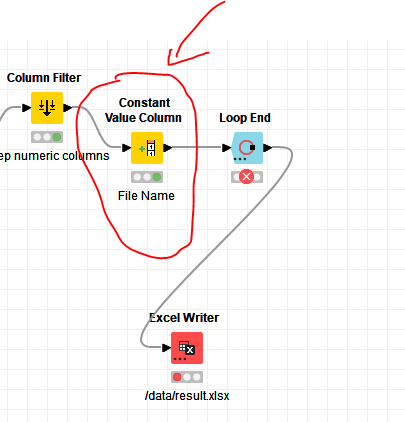
Wow, thanks. Looks like you put a lots of effort in this. I tried to run it I get two errors at the Loop end node.
Here is what they say.
1.ERROR Loop End 3:23 Execute failed: Input table’s structure differs from reference (first iteration) table: different column counts 7 vs. 10
ERROR Loop End 3:23 Execute failed: Input table’s structure differs from reference (first iteration) table: Column 0 [Column8 (Number (integer))] vs. [Column7 (Number (integer))]Column 1 [Column17 (Number (integer))] vs. [Column15 (Number (integer))]Column 2 [Column22 (Number (double))] vs. [Column20 (Number (double))]Column 3 [Column34 (Number (integer))] vs. [Column31 (Number (integer))]Column 4 [Column42 (Number (integer))] vs. [Column38 (Number (integer))]
And some extra warnings
WARN Fixed Width File Reader 3:2 Errors loading flow variables into node : Coding issue: Cannot create URL of data file from 'missing’in filereader config
WARN GroupBy 3:17 No grouping column included. Aggregate complete table
Do you have an idea to which table the message referrs to?
" Input table’s structure differs from reference (first iteration) table: different column counts 7 vs. 3"
@Dalmatino16 so it seems the structure of the tables are different and the 3 samples would not represent the whole task. You could try and use a part of the head as column name in order to identify the columns other than by position. I will have to see if I can build something.
Hi, thanks . By looking at the files, I cant see what is different, but then again, I have 140 files so cant check them all by eye.
Can one tell from the workflow or from the loop end output I got which files are problematic? It might be just one file out of 140.
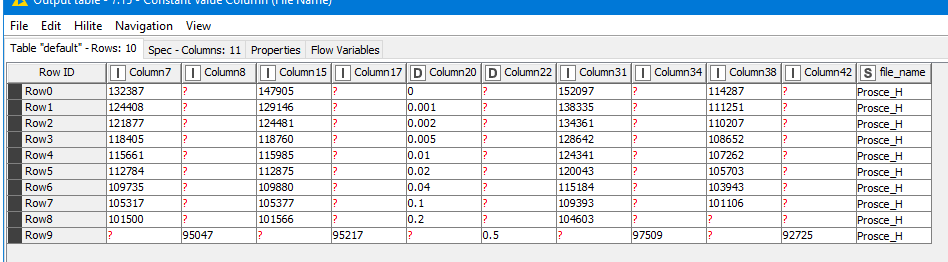
Hi, attached find one file which doesnt work [Prosce_H.txt|attachment](upload://v3Wr9DyZyEJBQZ7NzJz4df3GBY4.txt) (7.2 KB) I cant figure out why. The structure looks the same as one of the files you worked on.
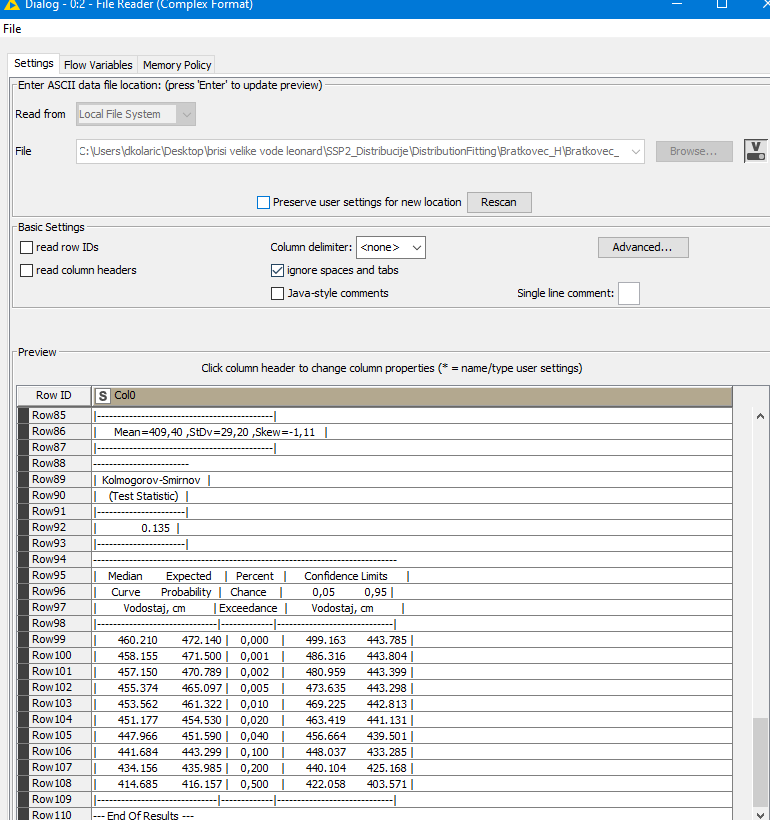
But here are the results of the last node that worked for the Prosce file
issue with Prošće is that in last row values are below 100 which means you have less digits leading to more columns as your separator in File Reader is space. To go around it you can add zeroes before every value that is under 100. But this is not really smart as this would require manual intervention each time there isn’t much rain or there is heavy rain and values go above 1000. So you can keep @mlauber71’s approach but change File Reader to read all data in single column (set separator to something that will never come up in data; e.g. * or something more complex if you want to be sure) and then manipulate it using String Manipulation node to get one space between each value. Follow it with Cell Splitter and you should be fine. And as a bonus you’ll get your values formatted properly
Ivane bok!
I have tried to work with your example and it worked for the most of the stations. However with some there are still problems. One problematic is the file called Djurmanec_H. It has a missing value
so that causes Knime to move the row left. The result looks like this
Its less of the problem because there is only one such file out of 100. But I have a whole set of files which dont have such a case but there is still something thats bothering the script/workflow and it doesnt work on them. I attached one such file. I am going to try figure out what might be the problem, but I am afraid I am not that skillful yet so would appreciate the info if you can quickly see it. Bracak_Q.txt (7.3 KB)
sry for later response. Don’t know have you managed to solve it already.
Anyways I have checked it out and problem with Bracak or difference versus other files is Percent Chance Exceedance column. Seems some files have comma in this column and and some dot. You can solve it by putting String to Number column after Cell Splitter node and configure it to always take Column0_Arr[2] column. Check workflow attached. kn_forum_43962_file_reader_complex_format_ipazin.knwf (77.2 KB)
Note that if your input files are not consistent and format can change with time/person these kind of problems might come on a regular basis.
Ivane bok !
Sorry for my late response now, I didn`t have an access to my account. But yes, you have resloved all the issues for me with the latest workflow. Thanks a lot. I am aware that change of the format can cause an issue. I just have a problem noticing whats different between the formats, sometimes the change is subtle. Any software to suggest which can screen/compare formats?
Best wishes,
Dario