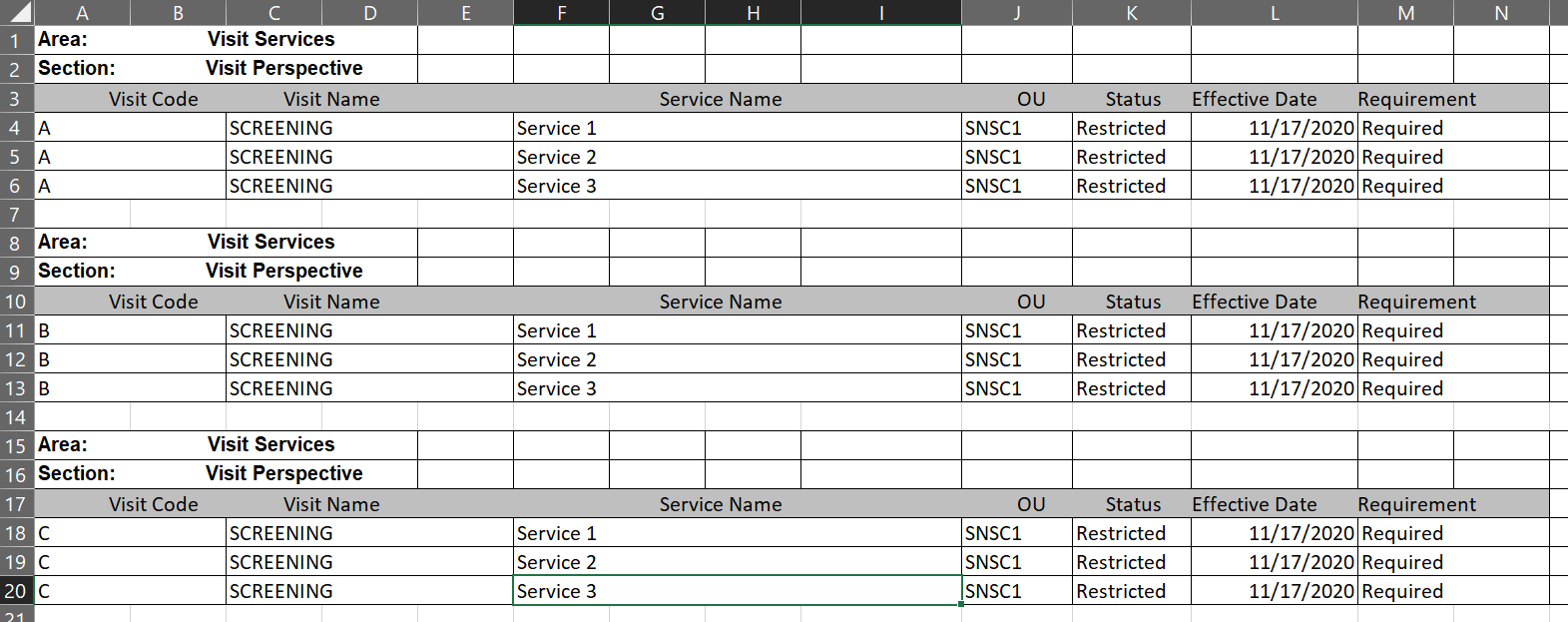
Hello! I’m currently using a single excel sheet that has thousands of rows of data, but I want to get a subset of that full table. There’s a unique identifier that helps me identify the sections I want to isolate (Visit Services), but I’m not sure how to filter down to just those sections from the entire report. The image below is an example of the report I’m trying to parse the data from.
As you can see, there are 3 different sections from the much larger report that I only want to include in the next step of my workflow. The position of this data isn’t constant, neither is how many rows within each section. Does anyone have any ideas how I can pull these 3 sections into their own output, while ignoring all the other data?
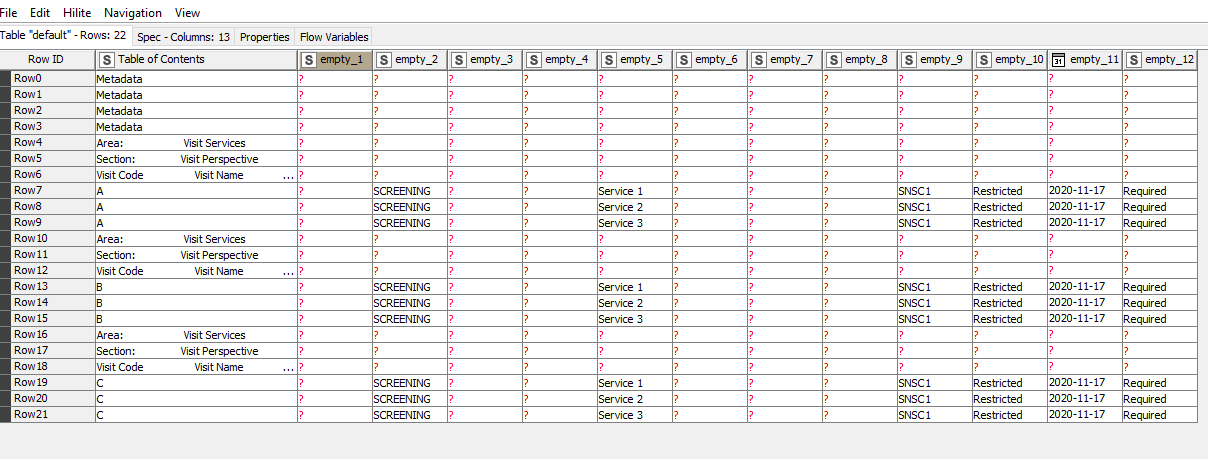
This is the output of my file in KNIME’s excel reader. I know I need to use the row filter node on the column “Table of Contents”, but again, not really sure what my variables should be. Any advice would be greatly appreciated.
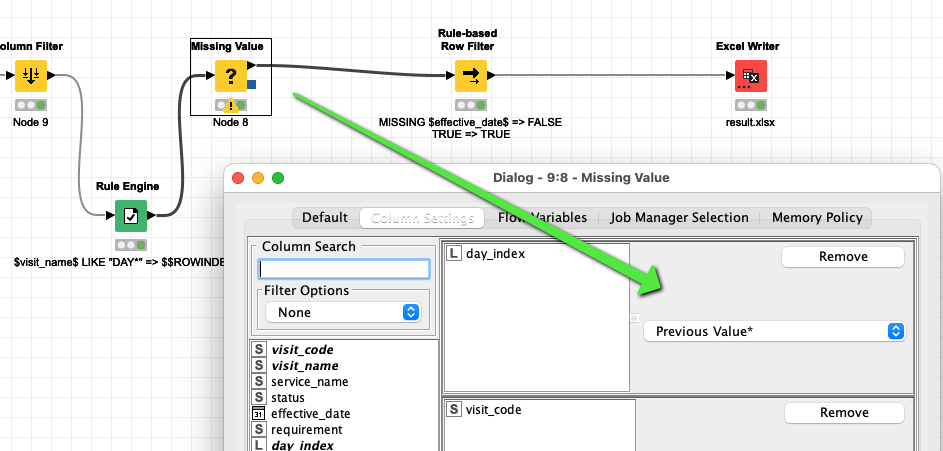
The key will be to identify a start (and stop) line and assign your ID or Rownumber to it and if necessary fill the lines in between with the help of the missing value node.
Here is a somewhat similar example.
Or maybe you upload your excel file here (deleting sensitive information first) and we could try a few things.
Here’s a VERY stripped version of the report (again, normally thousands of rows), but the format and placement of data match exactly what it would look like in the “wild” if you want to mess with this a bit as well. I’ll give your solution a shot and let you know if I run into any issues. Thanks for the reply!!
As I can see, the first example and the last one are not formatted the same way. In the second one, many cells in the first two columns are vertically merged, so - for example - only the first row of group “A” has the letter “A” in the first column.
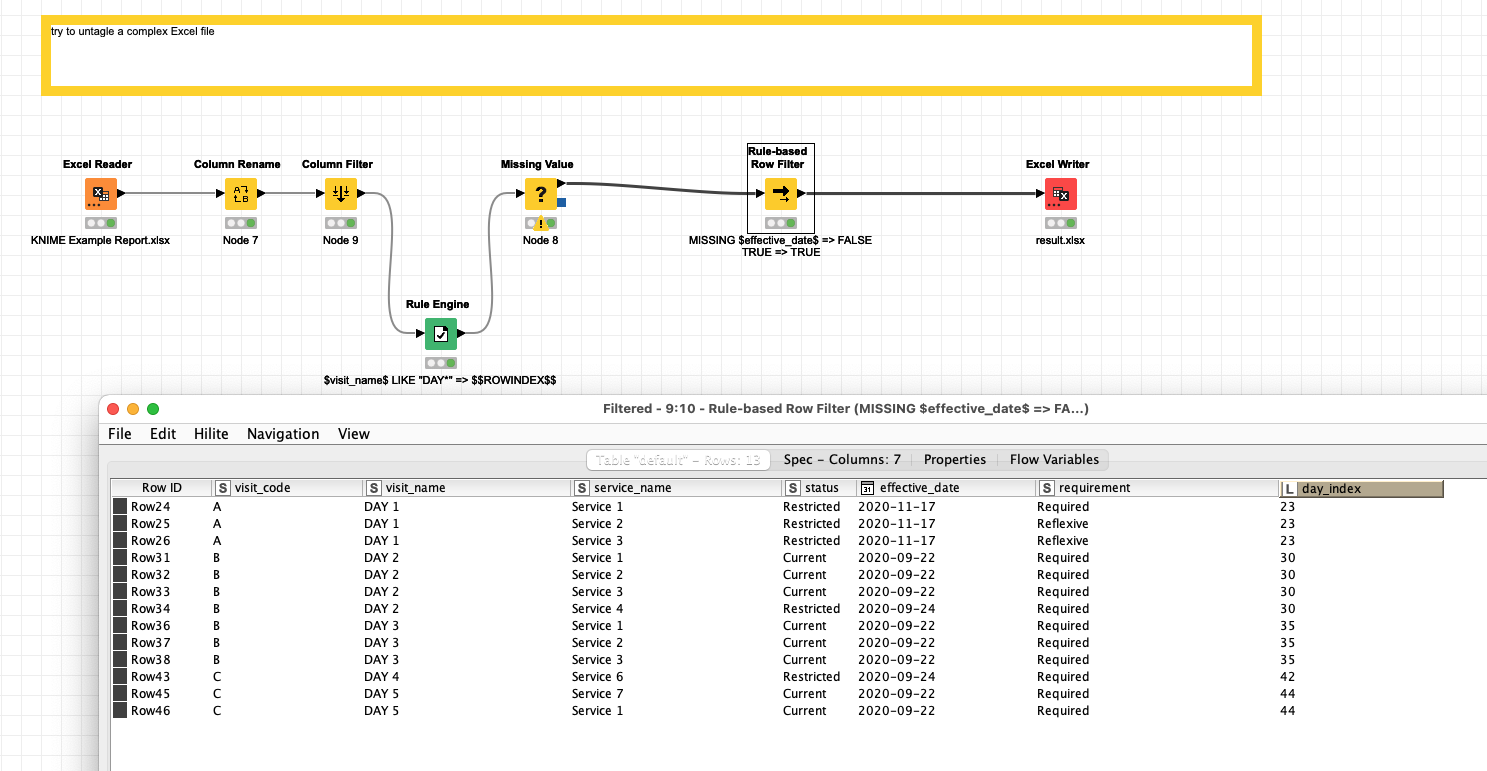
@mvaldes I tried a few things and came up with this. But I fear if your Excel files do not al have this exact structure it can get more complicated. You might try to better identify the headers of the column if they might shift. Also the two screenshots you provided do not seem to be from the same file.
So I think you will have to invest some more work.
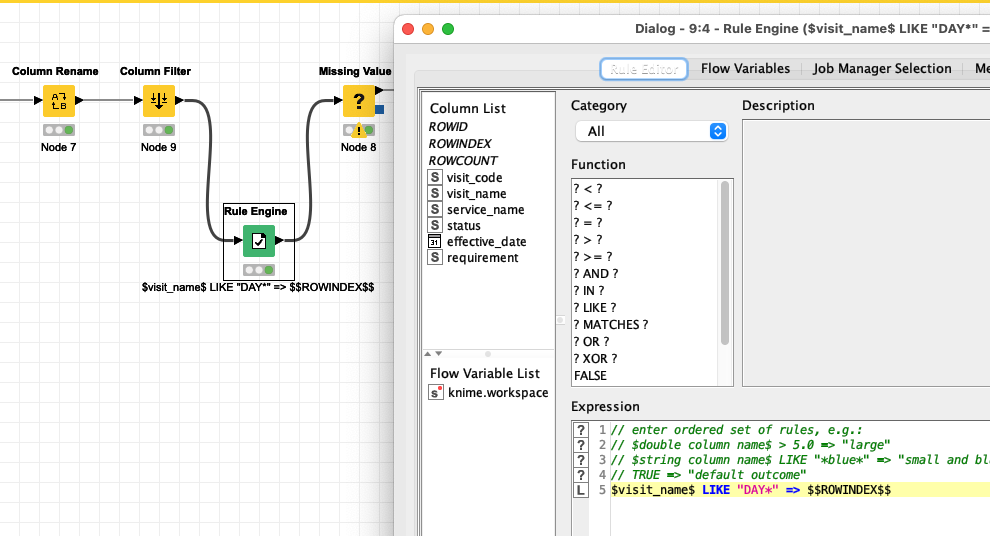
Key to the approach might be to mark the blocks you have by a rule filter (what would a start of a table block look like). In this case it is the term “DAY*” in a column
then copy the RowIndex to all the cells that are following so you can ‘mark’ a table block. And you can take it from there. There are some more complex examples on the forum. And since there questions appear a lot lately I might compile a list or a tutorial. You might search the forum until then.