Dear Knimers,
I need help with my workflow on an SVM optimization loop. I applied the RBF kernel, and added two parameters, using a series of different ranges of values (from very tiny to widely broad spectra): a) sigma; and b) Overlapping penalty.
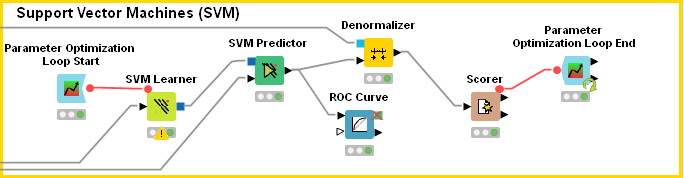
This is what my workflow looks like:
These are my data: Help with PpredictionsClassifcations.xlsx (9.7 KB)
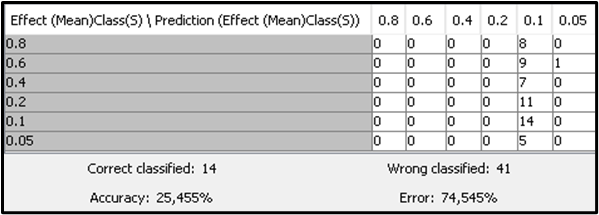
And this is the Confusion Matrix I always get, no matter what parameters I choose (in the Start node):
Can someone help me to find out what am I doing wrong? The predictions I get are almost always the same, and almost all are grouped under just one class…
What kind of problem do you have? ROC Curve is for binary classification. Does Denormalization work correctly? What is the result without the optimization? Same issues?
br
Hi, Daniel,
Sorry if I wasn’t quite clear. Please, let me try to tell you my situation in further detail:
a) I have already used (in other “branches” of this workflow) the same (or a quite similar) approach with five other algorithms (Linear, Polynomial, and Logistic Regressions; with Naïve Bayes; and with a “lazy” one, the k-NN), and applied the Scorer node to evaluate how good (or bad) was the prediction/classification of such algorithms. The results were pretty bad on the first three ones (16,67%; 23,53%; 30,91%), and pretty good with the other two (100%; and 98,18%).
b) next, I calculated separately the ROC curves (and AUC) for each individual class, in order to evaluate the associations among the observed metrics (the column "Effect (Mean)Class(S)) and the predictions of the algorithms, and each of the three (supposed) predictors (i.e., the three factors I investigate if are (or not) associated with my metrics and/or predictions).
c) in all algorithms (except with SVM), the Confusion Matrix showed predictions with a distribution in almost all of my six classes (labeled as: 0.8; 0.6; 0.4; 0.2; 0.1; 0.05).
d) It didn’t seem to me that any problem could be related to denormalization, because both metrics and predictions already were between 0 and 1.
e) without the optimization loops, SVM offered me predictions with a broad distribution in several classes, but all of them are wrong (accuracy = 0%).
f) without the optimization loop, I got the SVM classifications (for all instances) in just one class. Of course, the only “right classifications” are right just by chance (such as “even a stopped clock is right twice a day”).
g) by the way, under the loop, in the SVM Learner node, I imposed twice the same kernel and sigma parameter (because I have chosen the RBF kernel), both on the flag ‘Options’ and ‘Flow Variables’. Did I do it right? This is the Confusion Matrix I got:
Now, what’s next? How could I change the SVM parameters (“sigma” and “Overlapping penalty”) in order to make it works better? Or what should I change in my workflow?
If I haven’t been clear yet, please, let me know. Any questions are welcome.
Thanks for any help.
B.R.,
Rogério.
@rogerius1st you might want to tell us more about your problem. It seems this is (currently) a multi class problem. For that I would recommend reading the entries in my collection under the (well) “[multiclass]” section. Though from looking at your data there is not so much that a model would be able to use. You also might want to make clear what columns are features (is “Munic-yyyy-MM” an ID or a feature?) and which column is the target “Effect (Mean)Class(S)” I assume.
If you absolutely must have a SVM you might also try this implementation which seems to support multi-class tasks:
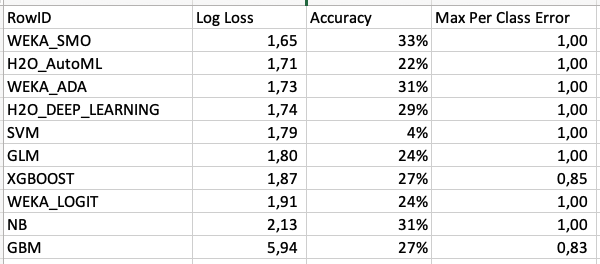
I would recommend using LogLoss as a metric and maybe try to use the H2O.ai AutoML node to get a first idea about where you stand. As it happens I have recently prepared two examples for multi-class problems. Though I am not convinced that this would work in your case since you have very little data it seems. You might try and formulate this as a regression problem or use a (simple) correlation to see if you get results and have a connection between your variables.
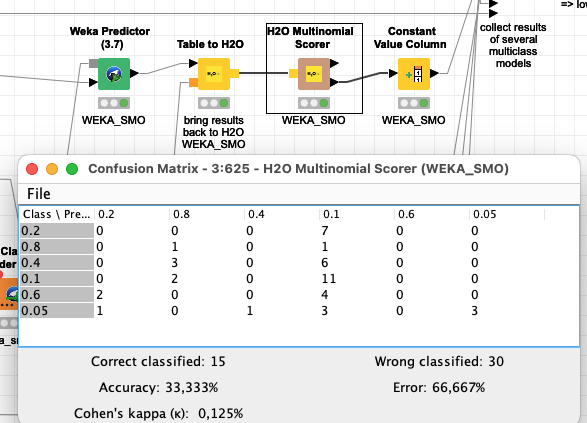
@rogerius1st SMO indeed has the best value in a quick comparison. This might not say that much. You might want to think about reformulating your question as a regression task? Would that be suitable to your needs?
The Accuracy still is not good. You might be able to tweak this by working on the parameters for the SMO but with your small dataset that might run the risk of overfitting.
This is interesting @mlauber71. Thanks for sharing.
Have you gained more experience in model comparison in KNIME regarding weka, H2O, sklearn and Tensorflow/Pytorch ?
br
@Daniel_Weikert this is what I have on Multi-class problems. Comparing the LogLoss. There was another question by @rogerius1st concerning ML frameworks and KNIME in general which I have tried to answer here:
TL;DR: AUC/Gini for general evaluation (combined with Top Decile Lift), AUCPR/LogLoss for highly imbalanced tasks, RMSE for regression tasks and LogLoss again for multi-class problems (here my experience is limited and you have to be careful how to handle them - you might want to check other measures).
Though obviously there is much more to the quality of a (binary) model (especially the actual cut-off point you choose). There are several graphics and statistics created to help you make the decision - which will have to correspond to your business problem/decision. KNIME has since condensed a lot of that into the: Binary Classification Inspector – KNIME Community Hub. These measures can be used regardless of where your model has been computed. The components would just use a submission=your score and a solution=the known truth and some path variables and R under the hood.
These validation component(s) mentioned in the second part in the link above are described in more details here for
@mlauber71
I tried H2O AutoML Node and my pc almost froze due to the CPU load. Currently I do not have cuda so the question is rather for future usage. I saw that deep learning is part of the models by default. Is there an option to specifiy the device type for H2O Algorithm as well?
br
@Daniel_Weikert it seems we are hijacking this thread but hopefully it will generate some insights. If you use the R/RStudio or Python implementation of H2O.ai AutoML you could set what resources you would allow it to have:
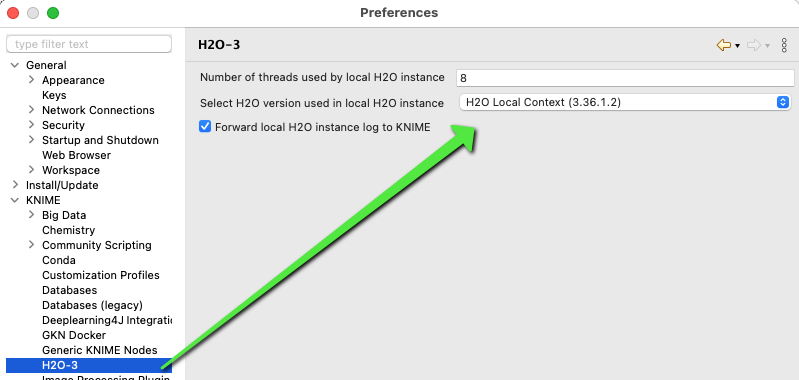
In KNIME you can try and limit the number of threads that might influence your CPU usage. I do not know of any GPU setting here. You might have to revert to another deep learning implementation.
Thanks ok I seems like there is an own module for cuda h2o in python.
Have you used KNIME H2o or other ML nodes in production at work? If so any issues?
edit: hijacking is fine
Others will benefit as well and the topic is related
br
Indeed I have you can hear about the experience here in this video:
As always you have to think about your data and your use case and how to set up the training files. Nice thing with H2O.ai and MOJO files is you can train them in one environment and transfer it to another (R, Python, Spark/BigData) and KNIME will coordinate it or even handle them itself.
A slightly newer collection about how to integrate H2O.ai with Big Data systems can be found here - “The poor man’s ML Ops”: