Dear all
I’m building a predictor model. My goal is to train a model on data frequency.
This means: I have a) the name of the universities b) the country of the universities and c) if the university needs to be checked (“YES” or “NO”). Each university has to be checked once (accreditation topic). When the university appears a second time on the list, the same university does not need to be checked again.
As a result, universities, which appear on the list once, have the status “YES”, universities which appear 2, 3 or more times, have the status “NO”.
In my opinion, the “Decision Tree Learner” and the “Decision Tree Predictor” are useful and provide the best results so far. However, it seems that it does not fully build on the “frequency” and more on relations between other values. E.g. the connection between the university and a certain country (e.g. Italy) seems to have more weight than the frequency (how often appears the university on the list).
Question: Maybe you can tell me if there is a certain KNIME “Learner” or “Predictor” algorithm that is (more) suitable for my Model or experience?
@LukasB in your scenario it would seem a group by of exciting university names a join and a rule engine or a reference row filter would do the job instead of a model. If this is the job.
Maybe you could provide a sample file and the outcome you want to have. Could be dummy data.
Dear @mlauber71@Daniel_Weikert
Thank you for your feedback.
Sure, may I provide you with a small sample file.
On this list, there are many universities which only appear twice. Some of them appear various times.
However, the outcome is always: The first time = Check in Anabin => “YES”, the second, third etc. times, “NO”.
Thank you
Best regards assessment.xlsx (16.4 KB)
Dear @mlauber71@Daniel_Weikert may I ask another question please:
I built a deployment workflow and implemented a PMML Predictor. This works. However, results which are not known from the trained model are shown with a question mark “?”.
Please see the printscreens attached.
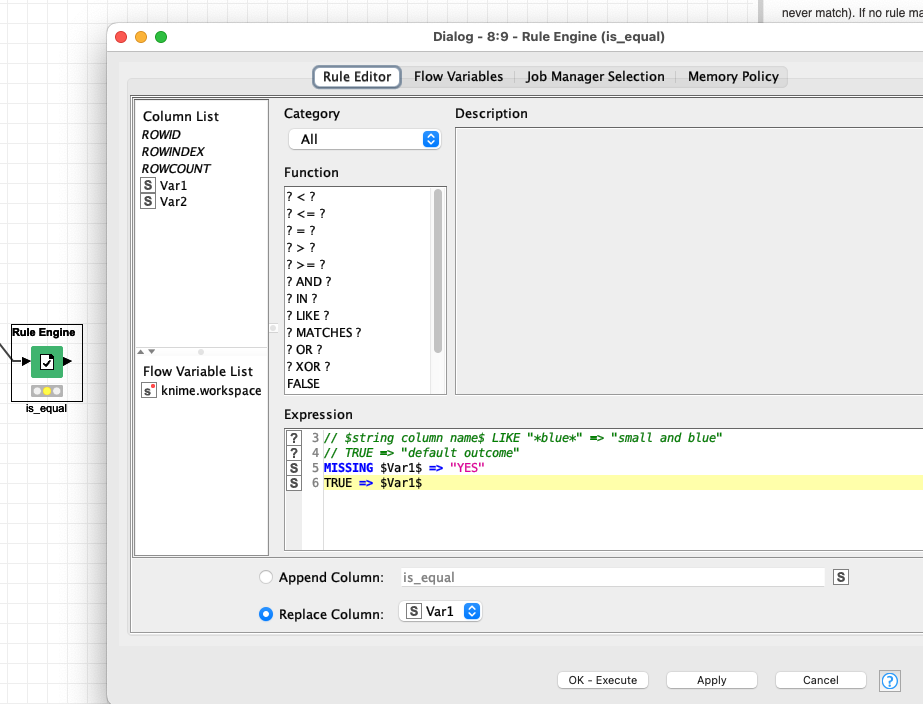
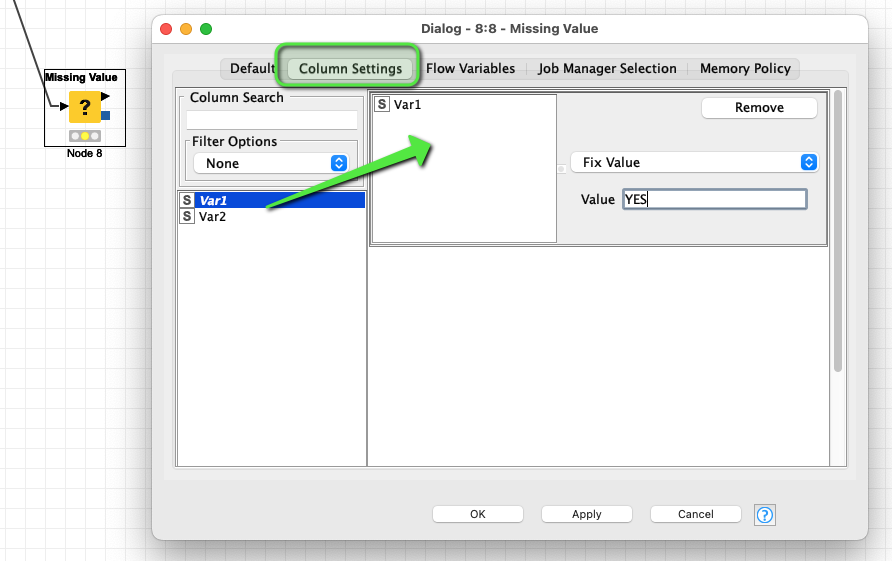
Question: Is there a possibility to link the “PMML Predictor” (a knode after the PMML Predictor) with another knode, which transforms/converts the question marks (“?”) into another value? E.g. YES or NO. Its just about a proper visualization of the results shown by the PMML Predictor.
Thank you for your feedback.
Best regards
Lukas
I still wonder why you have the missing values and still fear that it has to do with the way you constructed your model by (possibly) using University Names in the training. You should be certain that is what you want since it may lead to problems further down the line.
And then we have given you several hints and tried to engage with your case. Of course in a forum no one contributing is entitled to having their remarks taken into account or even being discussed - but in my opinion one could benefit from the debate and 20+ years of experience with machine learning models have taught me to be very careful about my (business) assumptions and what my data really tells me and how I construct my training and test data. I hope you will be happy with your model.
Dear @mlauber71 thank you again for this helpful solution.
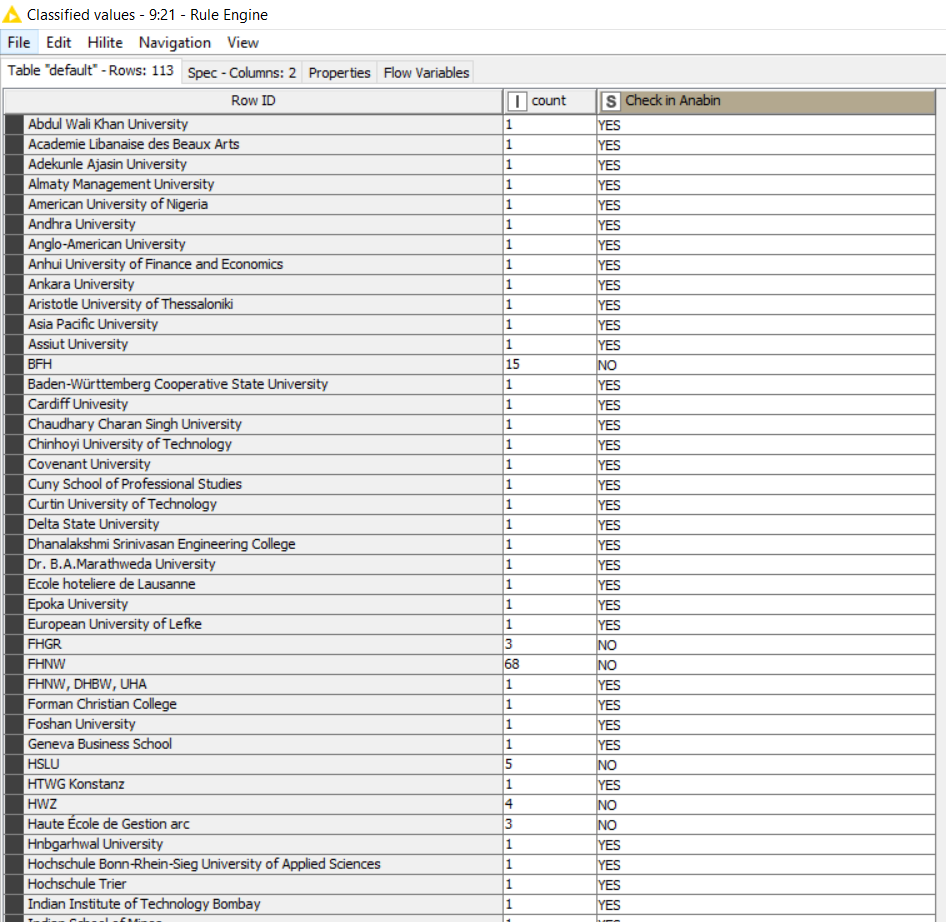
May I ask a follow-up question related to my provided Excel Sheet (datasheet)? In this case, I don’t train a model. Far more, I give outputs for each row, if a university needs to be checked or not. Same as before, when a university appears more than once on the list, the university only needs to be checked the first time (= YES). The second, third…time = “NO”.
My question: Is there a chance that you may adapt your provided Model to the condition that there are no values below the column “Check in Anabin”? The KNIME Model would have to provide the output “YES” or “NO” for each line.
Basically, the output could just be a list with all universities and its corresponding country and a given result (YES or NO) for them. In this case, the university would only be liste once and not several times.
Hi @LukasB
have you tried @mlauber71 s original idea with the groupby node? That would return the unique list of universities and you could do a count aggregation to see how often they appear. If just one then Yes if more then 1 “no” (the yes no can be done using rule engine node)
br