Hi there,
I have now a few times encountered that large data tables are not visible after e.g. a file reader node or various calculations/countings. We are talking about 150+ mio raw rows or something like that. My raw csv files looks good, but for some reason the reading of the whole file fails. I can do a limited number of row, which works fine.
Are there any limitations on how many rows can be handled?
Will the large dataset be imported and the problems will occur later or do you experience problems also when loading data? If you have problems with import it might help to use the R library Readr instead of KNIME file reader.
I know of no formal restriction for data in KNIME but it depends on how much power your system might bring. These points might be able to help you
check out the links below with hints from KNIME and other information about performance
with large datasets from CSV it might be worth having a separate workflow that stores them in a KNIME table or split up tasks into several workflows
check the memory handling of critical nodes
try to use the Parquet internal compression and see if that bringt any help
if you have a lot of large strings it could be possible to replace them with a dictionary and only deal with (long) integers - only if that fits your task
Thank you for the quick reply. Where can I find the R Library Reader you mention? Does that require additional extentions?
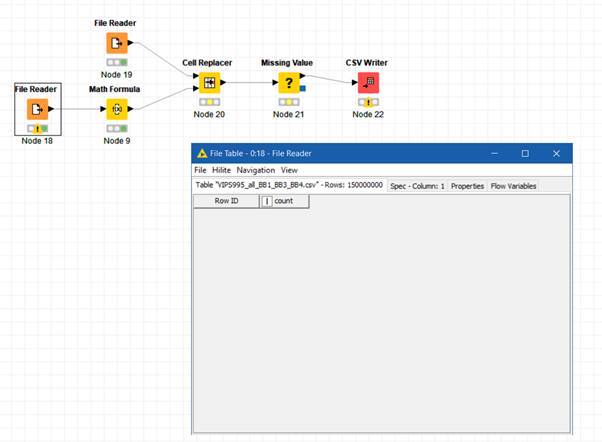
The problem seems to be in the importing/viewing of the data. I tried to increase the row limitation and somewhere between 140 and 150 mio rows, I can’t view the data table any more.
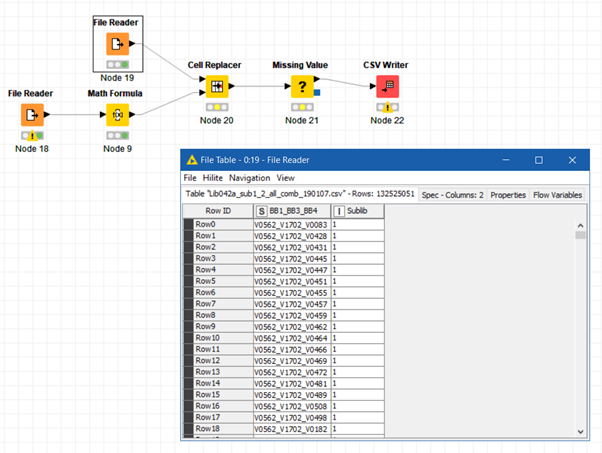
Tried to add two screenshots: One shows the file table from node 18 which is blank (limited to a 150 mio rows) and the other node 19 displays a different file as intended (132+ mio rows)
I am now trying to trim down the data to get below this limit or whatever it is. But really wish to solve this problem. My server has 56 GB ram allocated to KNIME and I have even set all nodes to write table to disc to save memory, but very little was actually used according to task manager.
Will be happy to hear all suggestions.
I can reproduce the problem with 150M rows … the data seems intact but the table viewer doesn’t show it. A workaround is to always a row filter before viewing the data since you are not going to inspect that many rows anyway.
We’ll open a ticket.
Thanks,
Bernd
PS: In KNIME 3.6 and 3.7 you can use Parquet as data storage, which will make table I/O more efficient, especially for this type of data – many rows, repeating data. (File -> Preferences -> KNIME -> Data Storage … it requires the Parquet extension installed from KNIME Labs)
Any luck with resolving this issue? I found a work-around by running my data through a row splitter into two table of approx 75 mio rows, doing the cell replacer that I wanted to on both and summing the results, but it got a little more complex than required.
Would highly appreciate a fix for this in the future
Sorry to write again, but has there been found a fix for the data tables not displaying when going above 150 mio rows? Think this issue also causes problems with other respects (writing large files as csv, groupby nodes etc)
Best
Kolster