Hi Everyone!
I am a recent convert from Alteryx to Knime. I really like this tool and compiled a list of feature and usability improvements that could make it even better. I think something Alteryx does well is allow you to build ETL flows with less “clicks”. Many of these feature suggestions would allow a user (like myself) to build ETL flows even quicker! My apologies in advance if some of these features may already be available. I watched the online videos, read Alteryx to Knime document, and did some searches throughout this community but could have missed a few things. Let me know if you agree/disagree or have any suggestions on if these features may already be available!
Feature request list
Is there a way to see the feature requests that are already in progress? I see in other posts feature tickets created, but not sure if there is a way to see when or on which interation update they will occur.
Data explorer
I know I can “ctrl + F” to search data within the data explorer, but a configurable search bar, as well as the ability to search within columns would be extremely helpful.

Also noted in node monitor comment below, but it would be great to make some of the data explorer functionality built into node monitor. It would be great to be able to have a search box in node monitor to explore certain data.
Included screenshot of Alteryx example.

Node drag and connect functionality
Super small feature, but it would be nice if you can drag a node in the viscinity of another node and auto-connect output to input. Those who have used Alteryx probably use this very frequently. Saves a few clicks on drag and drop and then connecting output to input. I know you can also click on a node and then double click on the next node and it autoconnects, but this feature would be great as well!
Data records near node when running workflow
Another small feature also noted in a previous suggestion within the community. When running a workflow in Alteryx, I can see the rumber of records near every tool so I can see the flow of records and where data may be getting lost. I know you can currently hover over the output of the node to see record count, but having the ability to see next to a node makes summary analysis much easier when analyzing your flow (pinpointing where data is lost rather than hovering over each node output. Alteryx example below.
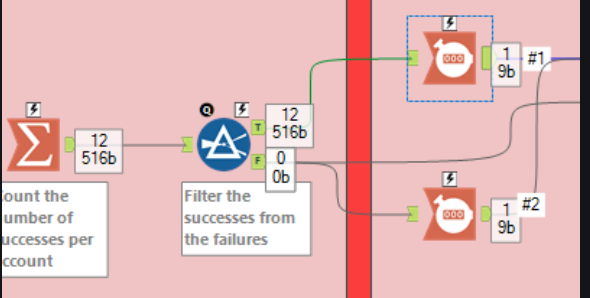
Node monitor window improvements
Output arrow click functionality to node monitor - For nodes with multiple output arrows (row splitter, joiner labs, ect) it would be nice to be able to click on each output arrow and see the updated values in node monitor. Currently, you need to select the port monitor in node output to select the output arrow to see. Maybe there an be updated functionality where clicking a certain output arrow auto-select the port # dropdown in output.
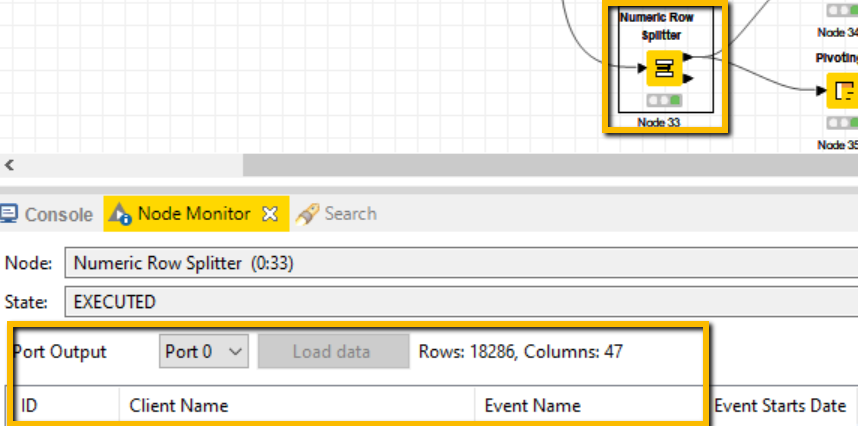
It would be great to have a search bar included in the node monitor to easily search data with in each node’s output. I frequently find myself search for certain data elements after joins to see what is not matching. PERFECT scenario would be to even include search feature by column.
Alteryx example below.
Configuration window pinned to canvas
I know others have posted the desire for this as well, but I think it is worth another mention. When building an ETL flow, it would be great to have the ability to just click on the node and see a config window pinned to the canvas instead of having to double click/right click and open a new window. Alteryx does this well and it is easy to follow your workflow and adjust nodes from one to the next.
Assign hot keys to certain nodes
I know you can update certain keys in preferences, but it would be great to have the ability to program certain nodes in keys. For example, in alteyrx, I frequently use the browse tool (data explorer equivalent). There is a key for “ctrl + B” which I found myself using all the time to quickly add the tool (node) after my current output. I think adding key programming for nodes could make building flows significantly faster.
Group by / Pivoting tool
For both the Group By and Pivoting nodes, I do not see the ability to change the group order, pivots (column order), or aggregation method order. I saw requests on the community in 2019 and I think there was a feature request sent back then. I think a simple up and down arrow in each component section would solve this. Included screenshot shows Alteryx arrows for reordering in summarize tool (equivalent to groupby).
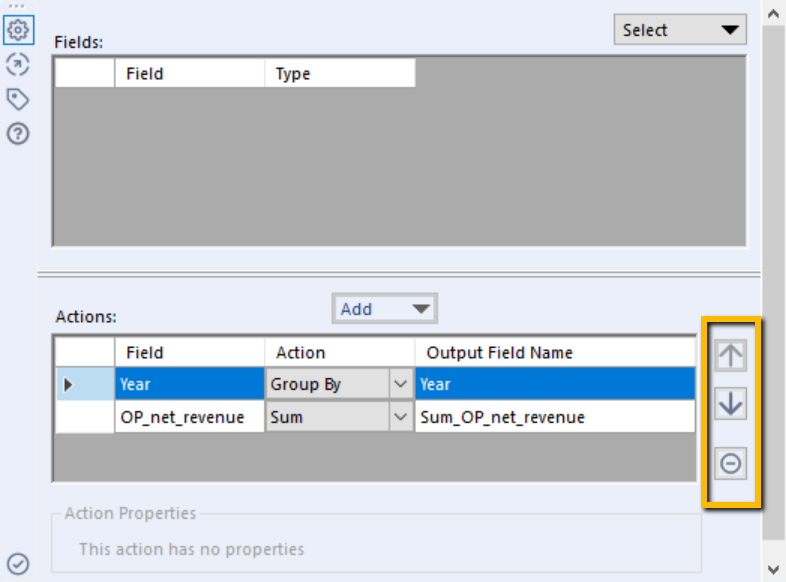
I will make additional posts as I see more opportunities, but I hope these feature requests are helpful! I think they all would result in less “clicks” and the ability to build and manage workflows more quickly.
Thank you,
Nick


 in order to track them and why not, vote them… it’ll be a wonderful tool for developers and for forum users.
in order to track them and why not, vote them… it’ll be a wonderful tool for developers and for forum users.
