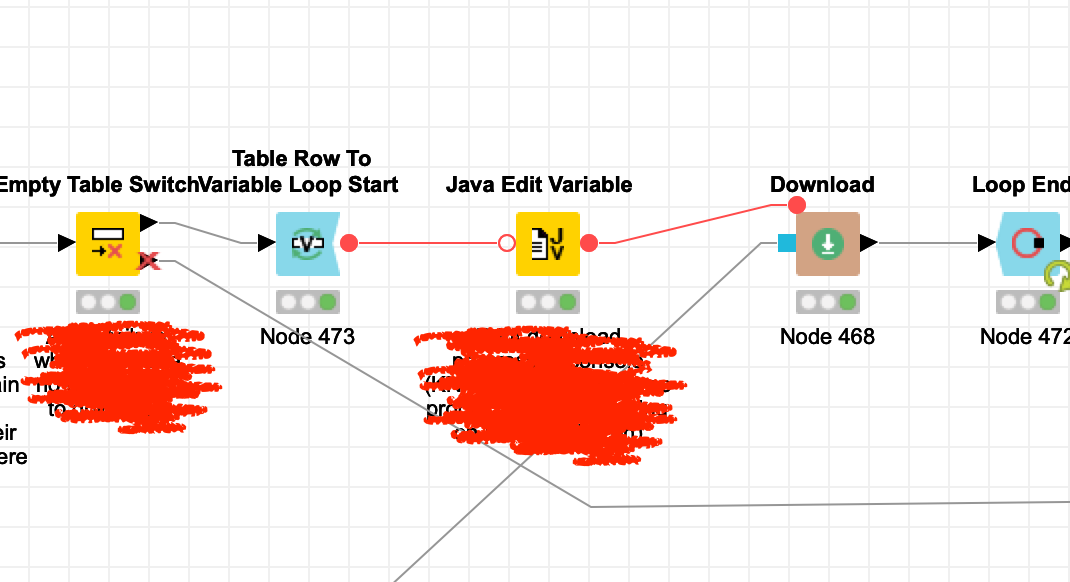
Encountered this very scary error with a long-running workflow during the night occurring at the “Table Row To Variable Loop Start” node. Any ideas? (the machine was running unattended, there was enough disk space, and I didn’t tamper with any temp files of course).
KNIME 4.1.1, macOS 10.14.6
– Philipp
2020-03-01 02:15:52,646 : WARN : KNIME-Worker-79-Java Edit Variable 0:475 : : JavaEditVarNodeModel : Java Edit Variable : 0:475 : ******* Downloading 30006/40313 : 74.43 % *******
2020-03-01 02:15:52,894 : ERROR : KNIME-Worker-73-Table Row To Variable Loop Start 0:473 : : Node : Table Row To Variable Loop Start : 0:473 : Execute failed: Cannot read file "knime_container_20200301_1905559478659870280.bin.snappy"
java.lang.RuntimeException: Cannot read file "knime_container_20200301_1905559478659870280.bin.snappy"
at org.knime.core.data.container.DefaultTableStoreReader.iterator(DefaultTableStoreReader.java:126)
at org.knime.core.data.container.storage.AbstractTableStoreReader.iteratorWithFilter(AbstractTableStoreReader.java:211)
at org.knime.core.data.container.Buffer$FromListFallBackFromFileIterator.initFallBackFromFileIterator(Buffer.java:2186)
at org.knime.core.data.container.Buffer$FromListFallBackFromFileIterator.next(Buffer.java:2204)
at org.knime.base.node.flowvariable.variableloophead.LoopStartVariableNodeModel.execute(LoopStartVariableNodeModel.java:120)
at org.knime.core.node.NodeModel.executeModel(NodeModel.java:580)
at org.knime.core.node.Node.invokeFullyNodeModelExecute(Node.java:1236)
at org.knime.core.node.Node.execute(Node.java:1016)
at org.knime.core.node.workflow.NativeNodeContainer.performExecuteNode(NativeNodeContainer.java:557)
at org.knime.core.node.exec.LocalNodeExecutionJob.mainExecute(LocalNodeExecutionJob.java:95)
at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:218)
at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:124)
at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:334)
at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:210)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123)
at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246)
Caused by: java.io.FileNotFoundException: /private/var/folders/w0/x3n005c967ldzqy6zz3tcmgc0000gn/T/xxxxxxxxxxxxxxxxxxxx/knime_container_20200301_1905559478659870280.bin.snappy (No such file or directory)
at java.io.FileInputStream.open0(Native Method)
at java.io.FileInputStream.open(FileInputStream.java:195)
at java.io.FileInputStream.<init>(FileInputStream.java:138)
at org.knime.core.data.container.DefaultTableStoreFormat$CompressionFormat.getInputStream(DefaultTableStoreFormat.java:207)
at org.knime.core.data.container.DefaultTableStoreReader$FromFileIterator.getInputStream(DefaultTableStoreReader.java:186)
at org.knime.core.data.container.BufferFromFileIteratorVersion20.<init>(BufferFromFileIteratorVersion20.java:124)
at org.knime.core.data.container.DefaultTableStoreReader.iterator(DefaultTableStoreReader.java:119)
... 17 more
2020-03-01 07:08:59,374 : ERROR : KNIME-BackgroundTableWriter-1 : : FileUtil : List Remote Files : 0:467 : Temp folder "/private/var/folders/w0/x3n005c967ldzqy6zz3tcmgc0000gn/T/xxxxxxxxxxxxxxxxxxxx" does not exist (associated with node context "List Remote Files 0:467 (EXECUTED)") - using fallback temp folder ("/private/var/folders/w0/x3n005c967ldzqy6zz3tcmgc0000gn/T"
Did you activate parquet as internal storage option? If so you might deactivate it. I am still wary of this feature and the parquet integration into KNIME.
If this does not help. Next idea could be to switch out snappy for GZIP or none or tell the node to store the table in memory.
Since you are experienced unfortunately it might not be easy to track such a strange error in the middle of an extensive loop.
If stability continues to be an issue you could think about strategies to save intermediate results and be able to restore a loop based on that results. That is not super straightforward but might save the day.
On KNIME server a strategy is possible to have a schedule run every hour or so an pick up where a crashed workflow might have stopped (with the option not to run if the previous job is still on).
Thanks for the very detailed advice, @mlauber71! This is very appreciated and very helpful for future references, also for others!
I had actually worked around the issue for now – the workflow allows to pick up at the previous state, so this was not a huge biggie for me and just a matter of re-triggering it with the outstanding items. However, I think it will be good to have this issue documented here, as I’ll probably not be the only one encountering the error.
Regarding my setup: I’m actually running this on a “vanilla” setup of KNIME (i.e. I’ve not modified any default compression settings).
Cheerio,
Philipp
PS: Should I have the opportunity, then I’ll try to provide a reproducible WF, as I cannot share this specific one. It’s still quite simple: A loop which contains a Java Snippet and a Download node to grab files from S3.
That is a very peculiar error. Thanks for bringing it to our attention and documenting it here. I doubt it is reproducible, but if it is, it’ll of course be much easier to diagnose.
Do you happen to have the log level of your knime.log set to DEBUG? If so, I’d be very interested in having a look at that log.
May I ask what kind of loop it was in which the error occurred? Also, do you know just about how large the table is that was read by the node that threw the error (number of rows / columns)?
Hi everybody,
I encountered the same error at least a couple of times. The errors appeared on a simple Row Filter node inside an extensive loop. I’m running KNIME 4.1.1 in Linux.
I think the name of the file that gave problem was something like: “knime_container_<identification_numbrs>.tmp”
I will upload a portion of the workflow, if I can reproduce the problem.
Cheers,
Gio
Thanks for the details. To get to the bottom of this, I have a couple more questions:
You mentioned that you were working with a vanilla installation of KNIME AP, but just to be sure: does your knime.ini deviate from the vanilla knime.ini in any way?
To rule out that Mac OS did not decide to delete the temp file automatically due to it not being used for a long time: For approximately how long was the workflow open when the error occurred? For how long did the workflow run?
Regarding the List Remote Files node, for which an error was logged at 07:08:59: Did that error occur while the machine was still running unattended overnight? Where is the node located in relation to the part of the workflow you took a screenshot of? How large is the table it generates? Is it the table that serves as input to the Table Row To Variable Loop Start node?
Some background / interpretation of what is happening based on the log you attached:
While iterating over the table in memory, the garbage collector decides to discard the table. It can only do so after all references to the table have been cleared. However, KNIME AP holds a reference to the table which it only clears after the table has been fully written to disk (asynchronously, in the background, directly after the node generating the table is green). This way, we make sure to not drop a table from memory if we cannot restore it from disk if need be. I therefore assume that the knime_container file was deleted rather than never created.
In fact, the last error that was logged indicates that the whole workflow temp directory was deleted. I am still at a loss as to why this happened. I read somewhere that Mac OS deletes temp files if they haven’t been touched for three days. But it sounds like a rather far-fetched explanation for the issue.
Hi @marc-bux, thank you for having a look at this problem. I also think that the file is deleted before it is read, that would make sense. What I can exclude is that the problem is related with Mac OS, as in my case it appears running on a GNU/Linux.
Unfortunately this problem seems to appear pseudo-randomly. If I manage to reproduce it, I will post that here.
You mentioned that you were working with a vanilla installation of KNIME AP, but just to be sure: does your knime.ini deviate from the vanilla knime.ini in any way?
I cannot remember making any changes for that installation, but here’s for the records:
To rule out that Mac OS did not decide to delete the temp file automatically due to it not being used for a long time: For approximately how long was the workflow open when the error occurred? For how long did the workflow run?
Looking at the logs, I started the workflow at 2020-03-01 00:46:20,131, and it errored at 2020-03-01 02:15:52,894, so it was running < 2 hours. It was probably “open” in the editor for longer, I had built it during that day.
Regarding the List Remote Files node, for which an error was logged at 07:08:59: Did that error occur while the machine was still running unattended overnight? Where is the node located in relation to the part of the workflow you took a screenshot of? How large is the table it generates? Is it the table that serves as input to the Table Row To Variable Loop Start node?
The error at 2020-03-01 07:08:59,374 must have been triggered when I re-executed after the workflow, in the morning after I saw the error.
The “List Remote Files” comes before the loop – it lists available files from an S3. Afterwards I list local files already downloaded and exclude them using a “Reference Row Filter”.
The “List Remote Files” generates ~ 60,000 rows. After the “Reference Row Filter” which would remove files which I already had locally, there were 40,313 rows which went into the loop (see log above).
A customer is running a workflow related to the same project (but an entirely different workflow). The common denominator is, that we also have a loop and we need to process something between 60,000 … 160,000 rows.
The client runs on a Windows machine, also the latest KNIME version. This specific workflow starts with a “Lists Files” node where I list all .svg files within a directory, and then essentially convert them to .png within the loop, followed by some custom Java snippet which crops away white space from the .png files.
I realize that both of these workflows (downloading S3 files, converting svg to png) should have probably better be done using some scripting language, but KNIME was established in the environment and we had some existing workflows on which we could built upon, so we went for that option.
This second workflow produced the following error:
2020-03-02 16:58:16,297 : WARN : KNIME-Worker-22-Java Snippet 0:4 : : Node : Image Writer (Table Column) : 0:7 : Output directory 'C:\Program Files\KNIME\missing' does not exist
2020-03-02 16:58:16,927 : ERROR : KNIME-Worker-22-Variable Loop End 0:12 : : LocalNodeExecutionJob : Variable Loop End : 0:12 : Caught "NullPointerException": null
java.lang.NullPointerException
at java.util.ArrayDeque.addLast(ArrayDeque.java:249)
at org.xerial.snappy.buffer.CachedBufferAllocator.release(CachedBufferAllocator.java:77)
at org.xerial.snappy.SnappyOutputStream.close(SnappyOutputStream.java:424)
at java.io.FilterOutputStream.close(FilterOutputStream.java:159)
at org.knime.core.data.container.BlockableOutputStream.close(BlockableOutputStream.java:160)
at java.io.FilterOutputStream.close(FilterOutputStream.java:159)
at org.knime.core.data.container.LongUTFDataOutputStream.close(LongUTFDataOutputStream.java:90)
at org.knime.core.data.container.DCObjectOutputVersion2.close(DCObjectOutputVersion2.java:152)
at org.knime.core.data.container.DefaultTableStoreWriter.close(DefaultTableStoreWriter.java:146)
at org.knime.core.data.container.Buffer.performClear(Buffer.java:1983)
at org.knime.core.data.container.Buffer$SoftRefLRULifecycle.onClear(Buffer.java:2739)
at org.knime.core.data.container.Buffer.clear(Buffer.java:1962)
at org.knime.core.data.container.ContainerTable.clear(ContainerTable.java:266)
at org.knime.core.data.container.RearrangeColumnsTable.clear(RearrangeColumnsTable.java:670)
at org.knime.core.node.BufferedDataTable.clearSingle(BufferedDataTable.java:947)
at org.knime.core.node.Node.cleanOutPorts(Node.java:1623)
at org.knime.core.node.workflow.NativeNodeContainer.cleanOutPorts(NativeNodeContainer.java:586)
at org.knime.core.node.workflow.NativeNodeContainer.performReset(NativeNodeContainer.java:580)
at org.knime.core.node.workflow.SingleNodeContainer.rawReset(SingleNodeContainer.java:428)
at org.knime.core.node.workflow.WorkflowManager.invokeResetOnSingleNodeContainer(WorkflowManager.java:4573)
at org.knime.core.node.workflow.WorkflowManager.restartLoop(WorkflowManager.java:3267)
at org.knime.core.node.workflow.WorkflowManager.doAfterExecution(WorkflowManager.java:3144)
at org.knime.core.node.workflow.NodeContainer.notifyParentExecuteFinished(NodeContainer.java:630)
at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:248)
at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:124)
at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:334)
at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:210)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123)
at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246)
On first sight, this seems totally unrelated described to the issue above. But the following points seem striking:
The stack trace contains the keyword “snappy” which also appeared in the opening issue – I have not followed the recent KNIME developments that closely, but this seems to be a recent new KNIME feature.
Both workflows used loops with a relatively big amount of rows
This one errored at iteration 31,435 of total 188,473 (which is at least close to 30,006 in the opening post)
Both WFs use Java snippet nodes in their loop bodies.
This second error you’ve been posting looks like an unrelated issue that has recently been brought to our attention via our automated tests. It could occur in the rare case when a table was cleared / discarded exactly at the moment when it was just finished being written to disk by some asynchronous process. The reason why you are seeing this in a loop is that here tables are frequently cleared shortly after they have been created / written to disk. It has since been fixed on our nightly build, but not (yet) in any of our released products. Apologies!
I have created a ticket for the first issue you (and @gcincilla) have reported. It is certainly odd that the workflow temp directory is deleted while the workflow is running. The only point in time where I know KNIME AP would delete this directory is when the workflow is closed. As mentioned earlier, what I could also see being the case is that the OS deletes that temp folder since it has not been modified for an extended period of time (e.g., due to KNIME AP being stuck in a long-running loop during which it processes only small tables that are not flushed to the temp folder). Having said that, we will investigate more thoroughly and check if there are any other occasions where KNIME could accidentally delete that folder (for whatever reason).
No news on it yet. We still aren’t able to reproduce the issue, let alone explain what piece of code could be responsible for deleting the workflow temp directory. Since you are still experiencing the problem - does the error only occur in that one particular workflow? Does it always happen in the same node at roughly the same iteration? Do you, by any chance, have a minimal workflow with which the problem can be reproduced?
The error occurs with (1) different workflows and (2) on different machines (all macOS).
All share the pattern that they run a loop with 100k+ iterations and that intense GC happens (the Eclipse heap status gauge moves quickly up/down but it seems to be a nice sawtooth, no leakage).
It’s the first time that it happened with this specific workflow. I cannot share it, but maybe the screenshot gives some more clues:
2020-05-04 23:24:37,124 : ERROR : KNIME-Worker-165-Loop End 0:30 : : LocalNodeExecutionJob : Loop End : 0:30 : Caught "NullPointerException": null
java.lang.NullPointerException
at java.util.ArrayDeque.addLast(ArrayDeque.java:249)
at org.xerial.snappy.buffer.CachedBufferAllocator.release(CachedBufferAllocator.java:77)
at org.xerial.snappy.SnappyOutputStream.close(SnappyOutputStream.java:424)
at java.io.FilterOutputStream.close(FilterOutputStream.java:159)
at org.knime.core.data.container.BlockableOutputStream.close(BlockableOutputStream.java:160)
at java.io.FilterOutputStream.close(FilterOutputStream.java:159)
at org.knime.core.data.container.LongUTFDataOutputStream.close(LongUTFDataOutputStream.java:90)
at org.knime.core.data.container.DCObjectOutputVersion2.close(DCObjectOutputVersion2.java:152)
at org.knime.core.data.container.DefaultTableStoreWriter.close(DefaultTableStoreWriter.java:146)
at org.knime.core.data.container.Buffer.performClear(Buffer.java:1983)
at org.knime.core.data.container.Buffer$SoftRefLRULifecycle.onClear(Buffer.java:2739)
at org.knime.core.data.container.Buffer.clear(Buffer.java:1962)
at org.knime.core.data.container.ContainerTable.clear(ContainerTable.java:266)
at org.knime.core.data.container.RearrangeColumnsTable.clear(RearrangeColumnsTable.java:670)
at org.knime.core.node.BufferedDataTable.clearSingle(BufferedDataTable.java:947)
at org.knime.core.node.Node.cleanOutPorts(Node.java:1623)
at org.knime.core.node.workflow.NativeNodeContainer.cleanOutPorts(NativeNodeContainer.java:586)
at org.knime.core.node.workflow.NativeNodeContainer.performReset(NativeNodeContainer.java:580)
at org.knime.core.node.workflow.SingleNodeContainer.rawReset(SingleNodeContainer.java:428)
at org.knime.core.node.workflow.WorkflowManager.invokeResetOnSingleNodeContainer(WorkflowManager.java:4573)
at org.knime.core.node.workflow.WorkflowManager.resetNodesInWFMConnectedToInPorts(WorkflowManager.java:2385)
at org.knime.core.node.workflow.WorkflowManager.restartLoop(WorkflowManager.java:3272)
at org.knime.core.node.workflow.WorkflowManager.doAfterExecution(WorkflowManager.java:3144)
at org.knime.core.node.workflow.NodeContainer.notifyParentExecuteFinished(NodeContainer.java:630)
at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:248)
at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:124)
at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:334)
at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:210)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123)
at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246)
I was not able to reproduce that within a simpler workflow so far.
Happened again during the send attempt during the night. The execution state looks different to above. All the grey meta nodes have the green check mark. Stack trace slightly different.
2020-05-05 07:36:09,684 : ERROR : KNIME-Worker-24-Loop End 0:30 : : LocalNodeExecutionJob : Loop End : 0:30 : Caught "NullPointerException": null
java.lang.NullPointerException
at java.util.ArrayDeque.addLast(ArrayDeque.java:249)
at org.xerial.snappy.buffer.CachedBufferAllocator.release(CachedBufferAllocator.java:77)
at org.xerial.snappy.SnappyOutputStream.close(SnappyOutputStream.java:424)
at java.io.FilterOutputStream.close(FilterOutputStream.java:159)
at org.knime.core.data.container.BlockableOutputStream.close(BlockableOutputStream.java:160)
at java.io.FilterOutputStream.close(FilterOutputStream.java:159)
at org.knime.core.data.container.LongUTFDataOutputStream.close(LongUTFDataOutputStream.java:90)
at org.knime.core.data.container.DCObjectOutputVersion2.close(DCObjectOutputVersion2.java:152)
at org.knime.core.data.container.DefaultTableStoreWriter.close(DefaultTableStoreWriter.java:146)
at org.knime.core.data.container.Buffer.performClear(Buffer.java:1983)
at org.knime.core.data.container.Buffer$SoftRefLRULifecycle.onClear(Buffer.java:2739)
at org.knime.core.data.container.Buffer.clear(Buffer.java:1962)
at org.knime.core.data.container.ContainerTable.clear(ContainerTable.java:266)
at org.knime.core.node.BufferedDataTable.clearSingle(BufferedDataTable.java:947)
at org.knime.core.node.Node.cleanOutPorts(Node.java:1623)
at org.knime.core.node.workflow.NativeNodeContainer.cleanOutPorts(NativeNodeContainer.java:586)
at org.knime.core.node.workflow.NativeNodeContainer.performReset(NativeNodeContainer.java:580)
at org.knime.core.node.workflow.SingleNodeContainer.rawReset(SingleNodeContainer.java:428)
at org.knime.core.node.workflow.WorkflowManager.invokeResetOnSingleNodeContainer(WorkflowManager.java:4573)
at org.knime.core.node.workflow.WorkflowManager.resetNodesInWFMConnectedToInPorts(WorkflowManager.java:2385)
at org.knime.core.node.workflow.WorkflowManager.restartLoop(WorkflowManager.java:3272)
at org.knime.core.node.workflow.WorkflowManager.doAfterExecution(WorkflowManager.java:3144)
at org.knime.core.node.workflow.NodeContainer.notifyParentExecuteFinished(NodeContainer.java:630)
at org.knime.core.node.workflow.NodeExecutionJob.internalRun(NodeExecutionJob.java:248)
at org.knime.core.node.workflow.NodeExecutionJob.run(NodeExecutionJob.java:124)
at org.knime.core.util.ThreadUtils$RunnableWithContextImpl.runWithContext(ThreadUtils.java:334)
at org.knime.core.util.ThreadUtils$RunnableWithContext.run(ThreadUtils.java:210)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at org.knime.core.util.ThreadPool$MyFuture.run(ThreadPool.java:123)
at org.knime.core.util.ThreadPool$Worker.run(ThreadPool.java:246)
would it be an option to use the Cache node at the end of some transformations in order to bring all the data together in one place before moving on in the loop so as to make it easier for the system to do the temporary storage
it might also be an option depending on the size of your data to tell all the nodes before in a Metanode to do their processing in memory and then do a cache which you force to store to disk
then is there an option to run the heavy garbage collector *1) in order to reduce ‘clutter’ (I have no idea how this would affect your outcome just something that came to my mind)
It could very well be that you would have to resort to a combination of measures. Maybe something like:
resort to the original internal storage (zip instead of parquet)
do the jobs within the Metanodes in memory
(- force the metanodes to run one after the other and not in parallel)
cache at the end of every iteration to disk
move on
(try some garbage collection inbetween - which of course might slow down the system or have some other unintended consequeces)
I ran some large data processings on a Windows server and my impression was that a strategic use of cache nodes before Joins could make the process more stable - although I have no ‘scientific’ evidence for that
The last thing I could think of is store the result of every iteration (or every nth) within a parquet file where you would point the HDFS folder of your local KNIME Big Data environment and then adress them all via a Hive extrenal table (so you would hopefully save the loop). Admittedly I have never actually tried this with very large numbers of files on a local machine
WOW! Again many thanks for these ideas I think this is a great collection of best practices, which I will try step by step!
For the time being, setting the compression to GZIP using -Dknime.compress.io=GZIP (as you had suggested initially), did the trick, and the WF ran successfully.