I have a few thousand EDIFACT files that I need to parse.
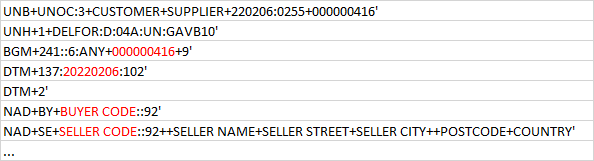
For those who don’t know what they look like: they contain 3-character segments (like DTM for date and time, NAD for name and address, etc). The segments contain data separated by plus and colon (their position is defined by the segment) and they are delimited by a quote mark to separate from the next segment.
i don’t think KNIME has a edifact parser and it would be quite a task to write a real praser with just knime notes, because edifact has some nesting in it (i worked with it in the german utilities sector).
I would advise to parse it via a python package and get the output a python script note.
Fore example you could use https://github.com/nerdocs/pydifact or https://github.com/php-edifact/edifact
You are right: the nesting in EDIFACT can be a challenge. Maybe transforming EDIFACT to JSON as a first step could help with that.
Thanks for the hint with python: I had found those packages too, but I have hardly any experience with it and don’t even know how to implement them or make them do something
Sounds like the promised land
Guess I need to give python a chance and see what happens.
Please find attached two calloff files: one of them containing one message (described by the UNH to UNT loop) and the other one containing multiple messages. Each message contains demand dates and quantities for one material number. Dates are specific days or a period.
Basically every message tells the vendor when they are required to ship a specific material to their customer.
LIN contains the material number.
Actual demand is in QTY+113 with DTM+2 under SCC+24.
Forecast demand (described by a period) is in QTY+113 with DTM+64 (start) and DTM+63 (end), under SCC+4.
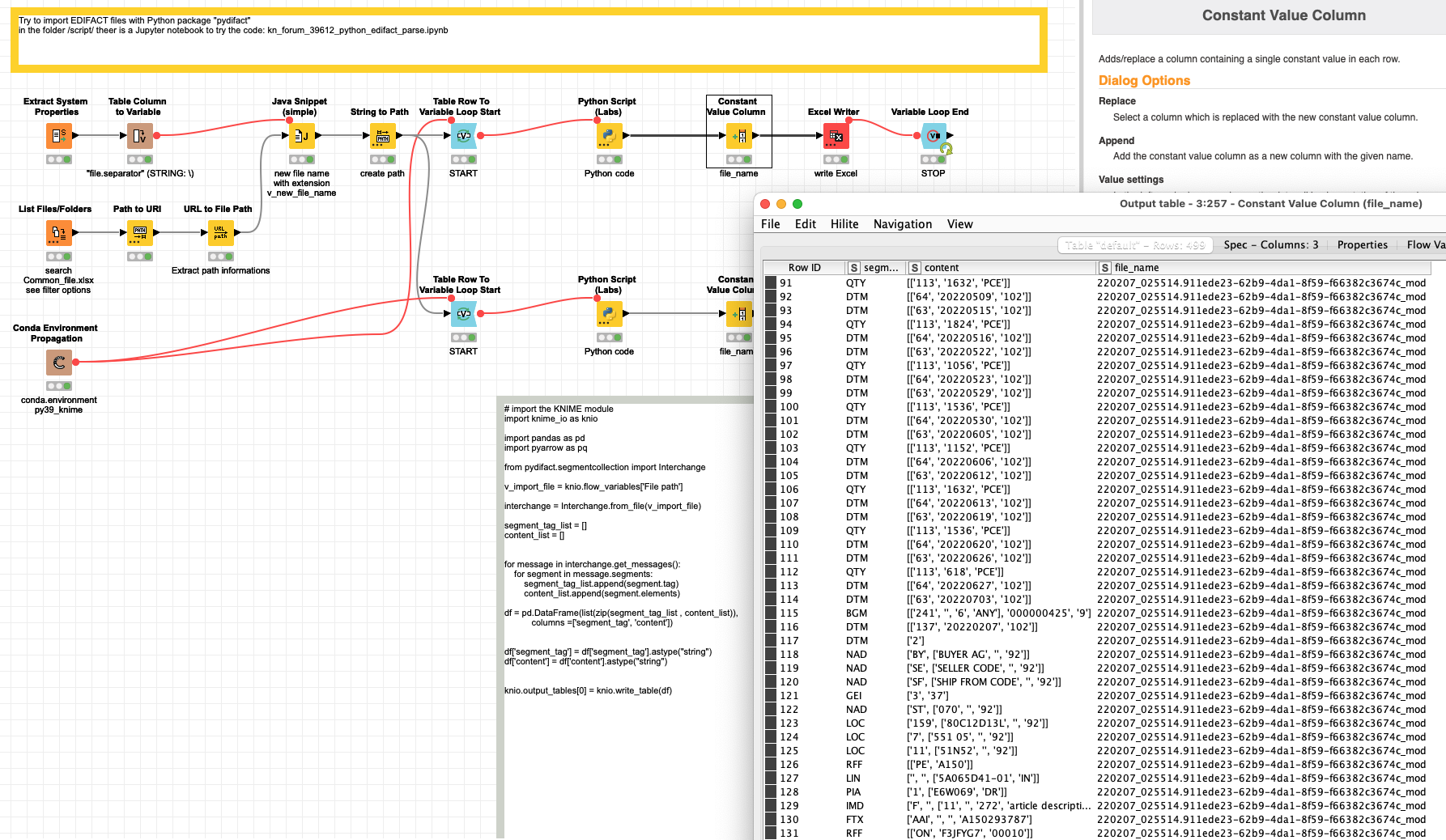
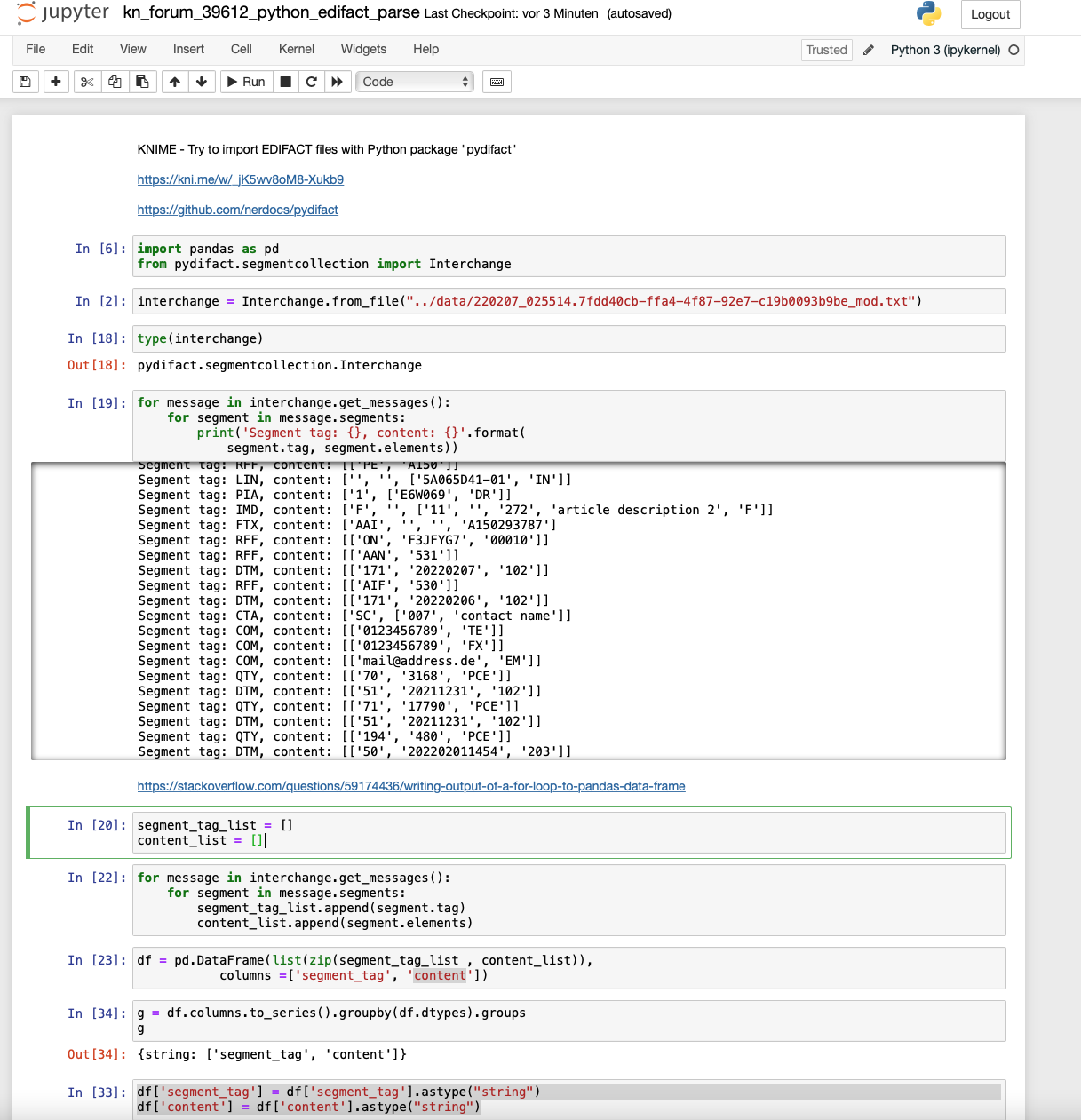
@gentile I tried a first import and split up the messages with the Python library and imported them into KNIME (and Excel to show what they look like). Further work will have to be done to split the lines into the tables you want.
I am not sure if the Python package would also offer this options but it might be worth a try (I am not familiar with the format as to be able to feed some sort of pattern into the code). Otherwise you will have to identify the blocks in the data and transform them to your needs.