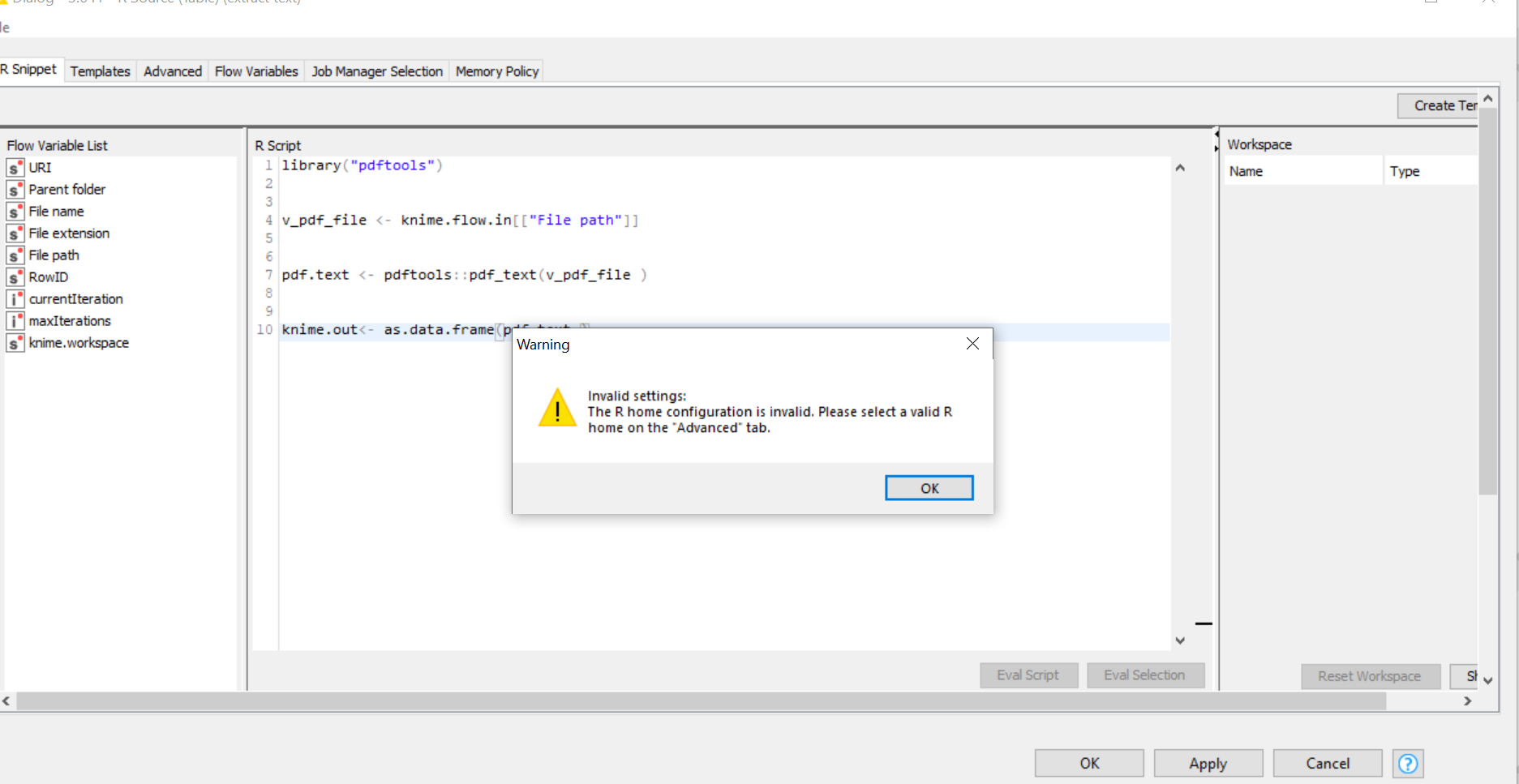
I want to read multiple lines from the PDF File. I have used the PDF Parser as well as the Tika Parser node but unable to fetch the details. Please help me in resolving the issue.
We have already workflow which will extract the PDF details if it is having one line details.
I am uploading the PDF File in doc format as I am unable to upload in PDF format as well as the workflow too. SG 4503089325.pdf.docx (63.2 KB) Automation-IDOC–Singapore.knwf (126.9 KB)
Please don’t post new topics in the KNIME Development forum unless they are specifically related to node development, the KNIME SDK, or similar. I have moved your topic to the main Analytics Platform forum.
Yes it is related to the same topic but here the input file consists of multiple lines and hence we are unable to fetch the details using PDF Parser or Tika Parser.
From the The input PDF file we need to generate Two Text files Header file and Detailed File.
Header File consists of the below details from PDF. As we have multiple lines we need to generate those many number of header lines.
PO Number–4503089325
shipment code—2003085667
PO Date–09.05.2022
Deliverydate–11.05.2022
Quantity
Amount
I took a look at what you posted. As you know, parsing text from PDFs in a non-trivial and oftentimes very frustrating problem - so I sympathize. But you should realize that without focused details it is unlikely that anyone is going to be able to help you. I say this because:
You have posted a large workflow without context on specifically where you are having a problem. Your workflow is largely unannotated and without any descriptive text. Basically, no one can understand what you’ve already tried.
It is is difficult to understand at a glance what your output represents, as there are no headers in the output datasets.
Parts of your workflow just don’t execute (e.g. Cross Joiner, String Manipulation)
I would suggest breaking your workflow into smaller chunks, and focusing on one problem at a time. Remember that people here in the forum are volunteering their time to help you, this isn’t a consulting firm. So give them as many details as possible in a concise way, to help them help you.
Then I would agree with what @ScottF says. It is difficult to follow what you want to do and at which point the community might be able to help. BTW you can enclose data within the node (preferably in the subfolder /data/) so you can have a complete example that other people might be able to run.
I notice this isn’t the first time this happens, @ScottF since you’ve also mentioned this a while ago to them:
In that thread, your comment (and @Daniel_Weikert 's comment too) wasn’t acknowledged at all, as in the case on this one. I’m curious to see what happens in the future.
As the above recommended process not accepting in servers do we have any other possible way to extract the details from the table in the attached PDF File.
If its possible, please kindly help me in resolving the issue.
Attaching the PDF file with .docx extension. This is a dummy data. SG 4503089325.pdf.docx (63.2 KB)
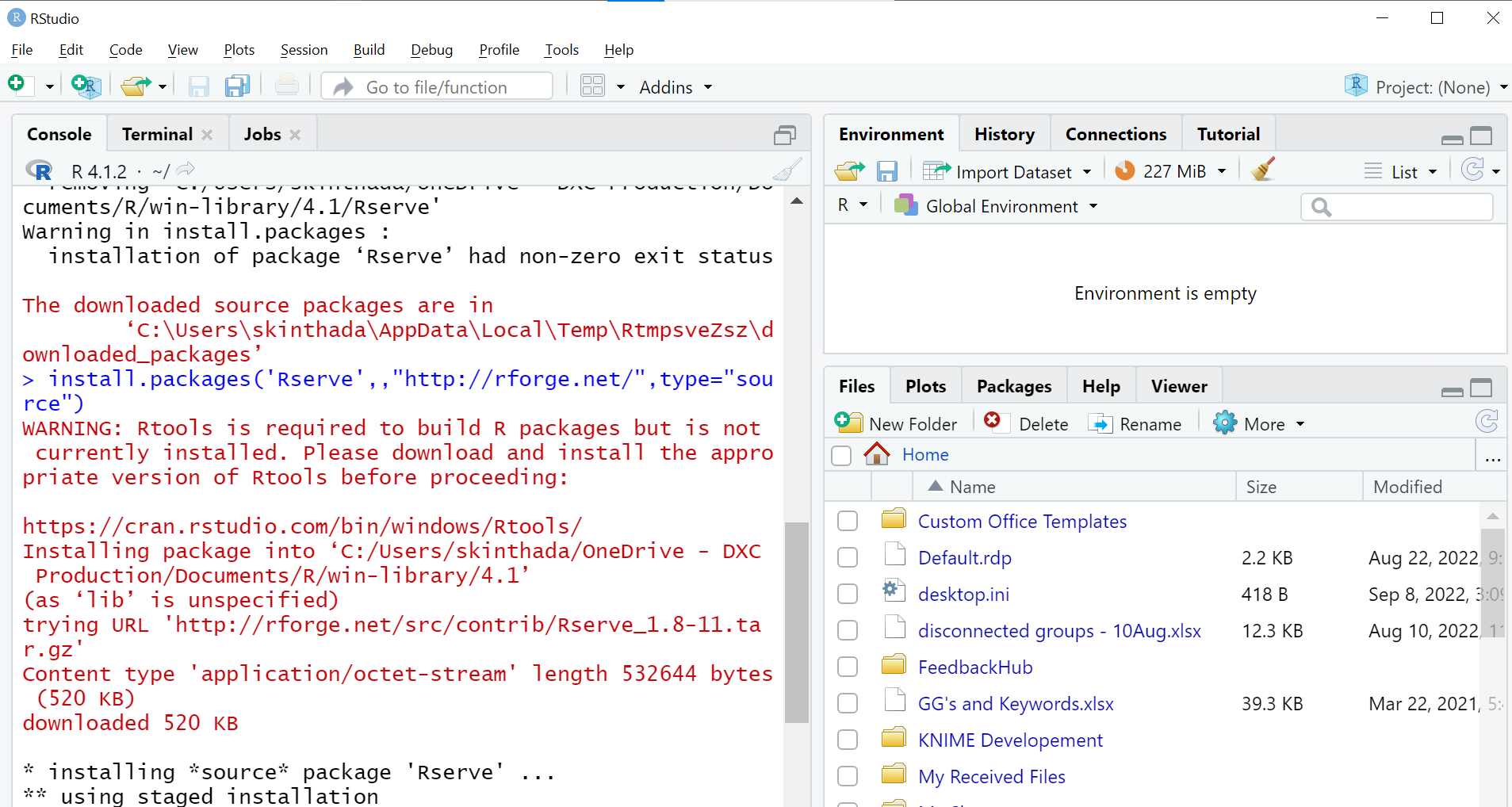
while installing rserve using the below commands using Rtools42 I am facing the below error. Please help me in resolving the issue. Please refer to the below screen shot